基于FPGA的PCIE设计(3)
PCIE协议基础
- 参考文献
- PCIE常用软件
- 项目简述
- PCIE概述
-
- ***PCIE协议主要包括四个部分:***
- ***下面将以主板上面的PCIE拓扑结构来介绍PCIE结构中上面的四个部件。***
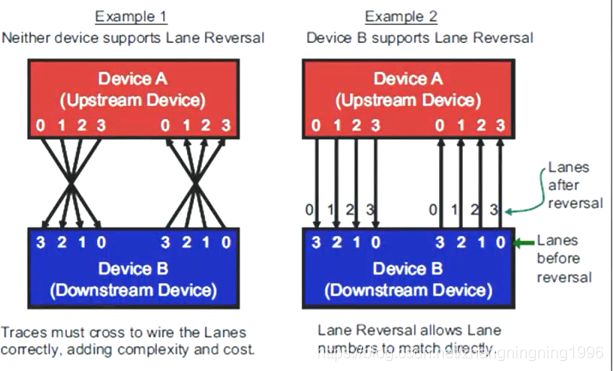
- ***PCIE设备为了避免布线的交叉,引入了Lane Reversal功能***,
- ***PCIE的接口形式主要体现在下图:***
- ***如何计算PCIE的数据吞吐量:***
- PCIE的前身
-
- ***PCI的起源***
- ***PCIE与PCI的不同点***
- ***PCI拓扑结构示例***
- ***PCIE拓扑结构示例***
- ***Bus Enumeration***
- PCIE背景知识
-
- ***X86结构的地址空间***
- ***Memory Map示例***
- ***IO Map示例***
- PCIE地址空间
-
- ***PCIE设备分配到哪些地址空间***
- ***Configuration Space***
- ***PCIE Configuration Space的示例***
- ***PCIE Memory Space与IO Space的对比***
- PCIE Memory Space示例
- ***PCIE IO Space示例***
- 总结
参考文献
[1]、移知网(接下来几篇博客是博主学习该课程的笔记加上了自己的一点见解,对于复杂性的知识,一定要养成记笔记的习惯,否则学完之后和没学一个样)
PCIE常用软件
[1]、System Information Viewer
[2]、MindShare Arbor
[3]、Read & Write Utility
项目简述
前面已经有两篇博客介绍了PCIE,相信大家应该都看不懂,前面的博客主要讲解了PCIE在FPGA中的实现,那么我们就接着学习这个协议。在接下来的几篇博客,我将尽可能的讲解一些我学会的PCIE的知识,但是要想真正学会还是得看Base Specification。这里再次说明,如果只是为了使用PCIE那么完全没有必要对PCIE的协议了解太深,因为在FPGA里面有相应的IP。这里说明一下XDMA的缺点,因为XDMA使用起来非常方便,但是本身的缺点是占用的逻辑资源量巨大。
PCIE概述
PCIE协议的全称是PCI Express。
全双工点对对的串行通信协议。
PCIE的术语有Link、Lane。
Link其实就是指传输端和接收端之间的通路
Lane是值一对tx、rx。其中一条Link可以包括多个Lane
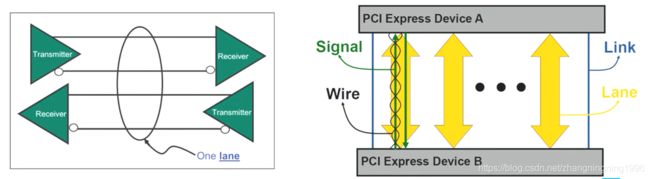
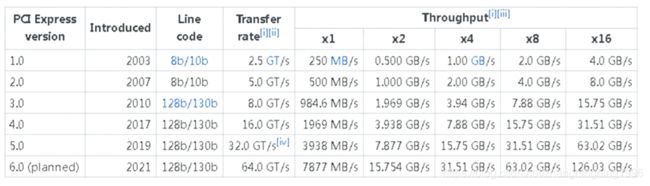
常见的Link包括x1,x2,x4,x8,x16条Lane,常见的速率如下:2.5,5,8,16,32GT/s,分别是PCIE1.0、2.0、3.0、4.0、5.0的速率,PCIE6.0也正在研发过程中。
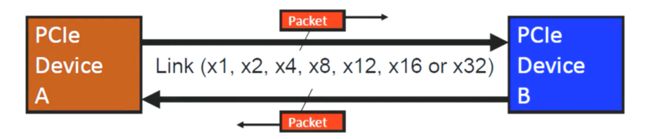
PCIE协议主要包括四个部分:
1、Root Complex
是PCIE系统的顶层,主要负责连接CPU和Memory到外面的PCIE设备
2、Switch
提供一个扇出和聚合的能力,允许多个设备经过Switch连接到一个PCIE接口。
3、Bridge
桥提供一个接口到其他总线,如PCI或PCI-X端点,也就是说经过该端口PCIE的拓扑结构上面可以连接PCI设备。
4、Endpoint
PCle拓扑中的设备,它不是Switch或Bridge,而是充当总线上事务的启动器和完成器。
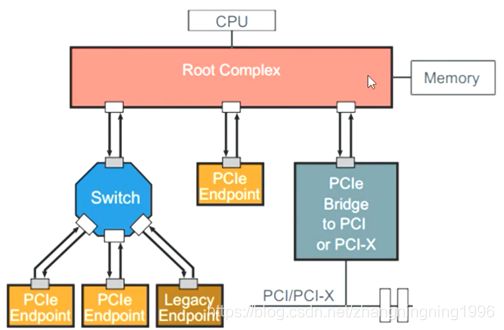
下面将以主板上面的PCIE拓扑结构来介绍PCIE结构中上面的四个部件。
PCIE结构的Root Complex在主板中的位置:
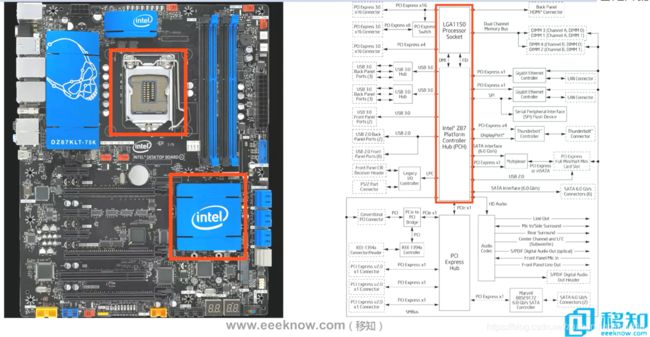
PCIE结构中的Switch在主板上的体现为:
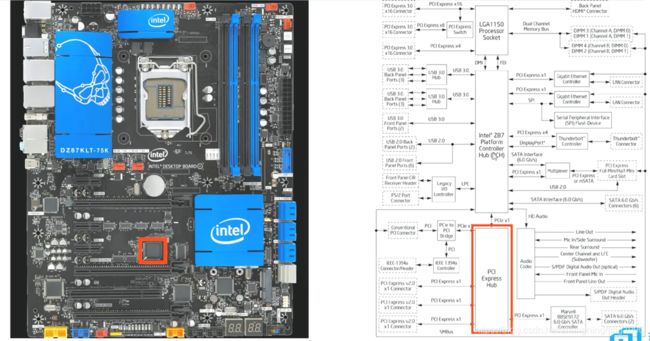
PCIE结构中的Bridge在主板上的体现为:
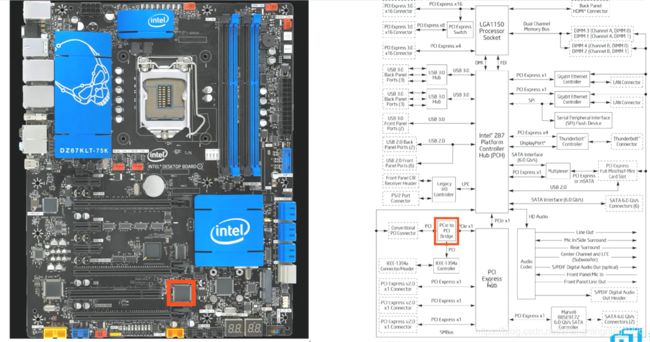
主板上面的Endpoint部位如下:
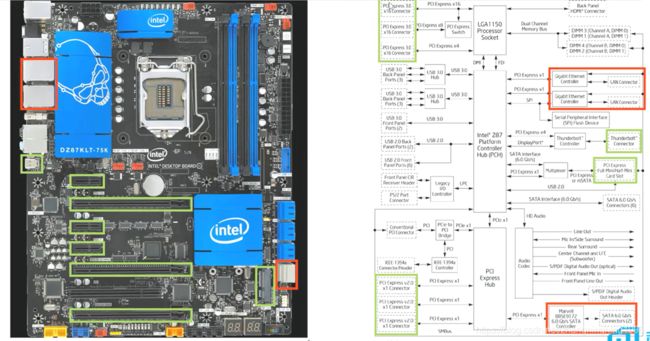
经过上面的介绍可以发现,主板上绝大多数的硬件都是经过PCIE的拓扑结构连接到CPU上面的,如显卡、硬盘、网卡等等。
这里值得说明,PCIE的兼容性很强,举例说明如下:
1、X8卡槽可以连接X1,X2,X4,X8,X16的PCIE设备。
2、PCIE2.0的设备可以连接PCIE1.0、2.0、3.0、4.0的设备。
只不过上面的速度全部是向下兼容。
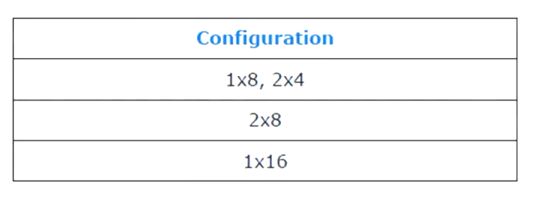
注意主板上面还有PCIE的分叉结构,如下:
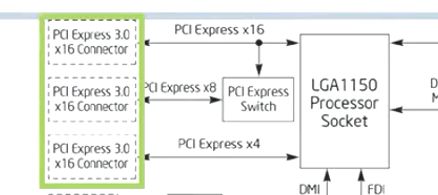
该结构可以连接一个连接一个PCIE X16的设备,也可以连接两个PCIE X8的设备,或者连接一个PCIE X8两个PCIE X4的设备。具体的配置如下:
PCIE设备为了避免布线的交叉,引入了Lane Reversal功能,
也就是说Device A的0线接Device B的最高编码的线(这里注意,这里的一条线就是一对Lane),如下:
PCIE强制性的引入了Polarity Inversion技术,也就是说Device A的正线接Device B的负线,如下:
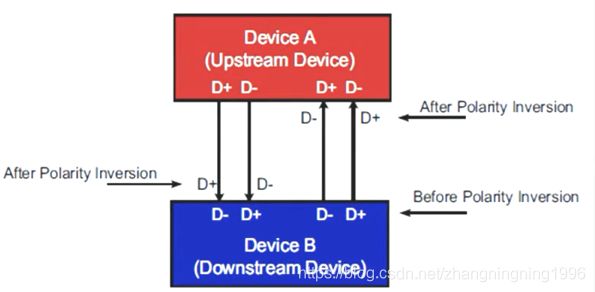
PCIE协议可以不支持Lane Reversal功能但是必须支持Polarity Inversion技术。
PCIE的接口形式主要体现在下图:

现在AMD公司已经生产了PCIE4.0的主板:

如何计算PCIE的数据吞吐量:

这里因为8/10b编码的效率太低,从PCIE3.0该编码已经换成了128/130b编码。
经过上面的计算,PCIE不同协议的数据吞吐量如下:
例子:网卡厂商需要设计一款四口千兆网卡和一款爽口万兆网卡,该如何选择性价比最高的解决方案?
1、四口千兆网卡

2、双口万兆网卡

PCIE的前身
PCI的起源
在1990年代早期发展,以解决当时在pc机中使用的外围总线的缺点,PCI协议被提出来。紧接着电脑的数据吞吐量逐渐增大,PCI满足不了人们的需求,PCI-X被提出来。几年后,PCI-X (pci - extended)被开发为PCl体系结构的逻辑扩展,并大大提高了总线的性能。其中PCI与PCI-X统称为PCI协议。详细的情况如下:
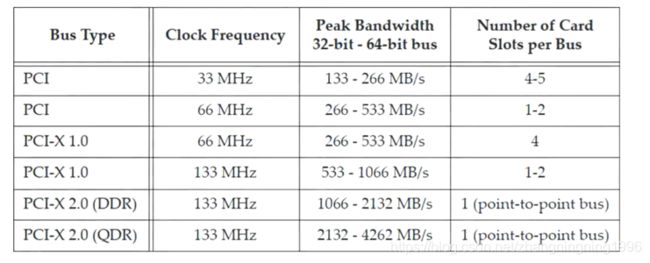
PCIE与PCI的不同点
常见的PCI与PCIE的拓扑排列结构如下:

PCl:共享总线这里的限制是,由于每个设备共享相同的总线,当要连接的设备数量更多时,它们必须等待总线释放来发送和接收数据。PCI总线式并行的,所以数据无法跑的太快。
PCIE:点对点将拓扑完全改变为串行架构,其中每个设备都有自己的专用总线。所以传输速率很快。这里有一个先验知识,一般串行数据总是比并行数据跑的快,因为数据并行越多越容易产生数据错位,建立时间与保持时间更不容易满足。
但是软件向后兼容性PCle最重要的设计目标之一。为了减少变更的成本、风险和工作量的一种常见方法是为PCI编写的软件PCIE可以使用,同理为PCIE编写的软件PCI同样可以使用。
PCI拓扑结构示例
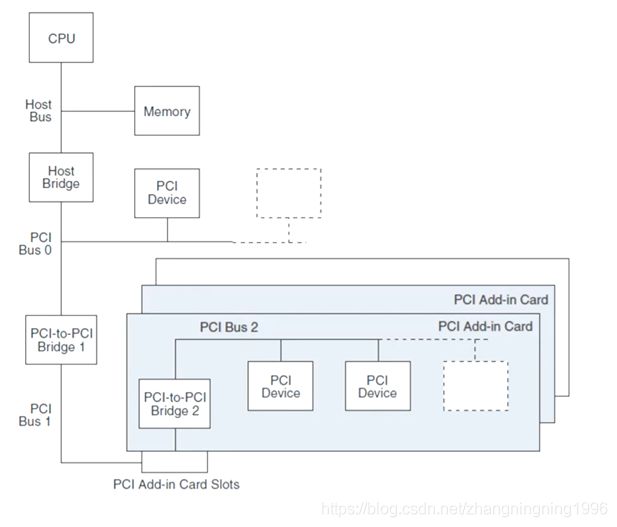
Host Bridge:提供从本地处理器总线到PCI总线的转换
PCI-to-PCI Bridge:连接两个PCI总线部分
PCIE拓扑结构示例
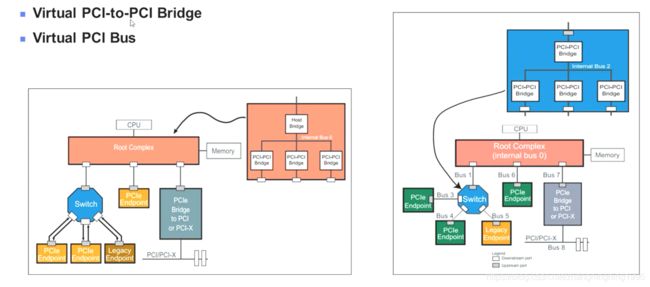
下面将出现非常重要的三个概念,也是在TLP包中经常出现的概念,绝大多数同学不太清楚。
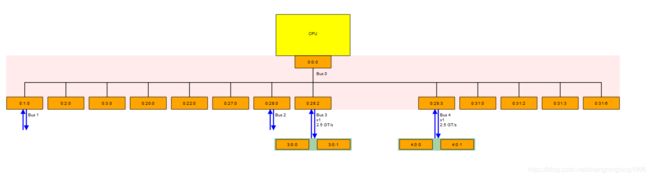
上层配置软件(Root Complex)负责检测所有的PCIE总线设备,为了区分PCIE设备,对每条Bus、Device、Functions进行编号,也就是我们常说的Bus Number、Device Number、Functions Number。如下图:

Bus:一个PCIE系统中编号为1~256,也就是连接PCIE设备的线。
Device:PCIE设备,对于每个总线编号为1~32,也就是说每条总线最多有32个PCIE设备。
Function:每个设备内部可能分为几个不同的PCIE函数,比如显卡内部就有视频与声音两部分,每个设备内部Function的数目最多是8个,编号也就是1~8。
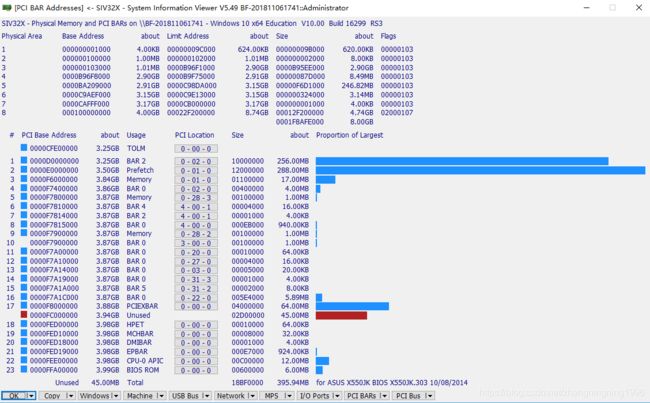
这里推荐一个查看电脑PCIE拓扑结构的软件:System Information Viewer

点击软件的PCI Bus会出现下列数据。
这里再推荐一个查看电脑PCIE拓扑结构的软件:MindShare Arbor
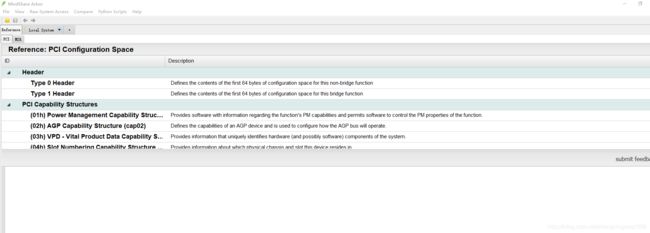
可以得到我电脑上的PCIE拓扑图:
这里并没有现实完全,至于为什么我也不清楚,知道的同学可以留言讨论一下。
Bus Enumeration
扫描PCle结构以发现其拓扑的过程称为枚举过程。首先说明BUS枚举是基于深度优先的标准,相信学过数据结构的同学对这个概念比较了解,这里不再多介绍,同学们可以查阅相应的原理。
这里又要引入三个TLP包中重要的概念如下:
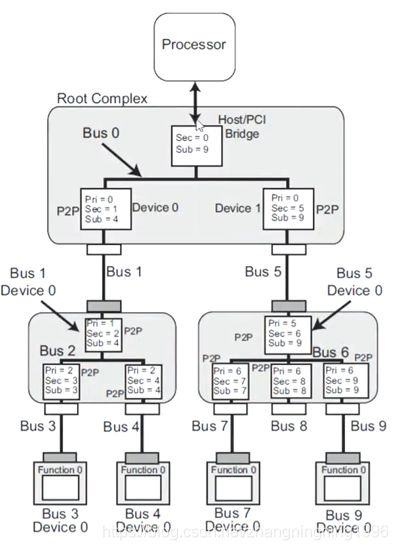
Primary Bus:Bridge上游的Bus Number。
Secondary Bus:Bridge下游的Bus Numeber。
Subordinate Bus:Bridge下游最大的Bus Numeber。
结合图形理解上面三个概念。
PCIE背景知识
X86结构的地址空间
x86体系结构将地址空间分隔为两个编程上完全不同的组:Memory和IO。
之前,Memory被用作数据的存储,在那里读和写不会有副作用,IO端口被用来控制外部硬件,这需要不同的时间来工作。这里也就是说Memory读写的速度要比IO读写的速度快的多。
现在IO读写应慢慢被Memory读写所取代,只是因为要兼容PCI所以目前PCIE协议还支持IO读写。
对于Memory Space与IO Space的大小如下:

空间分布如下:
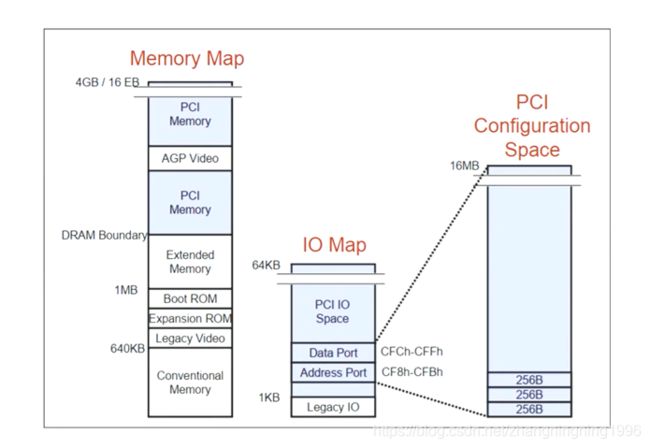
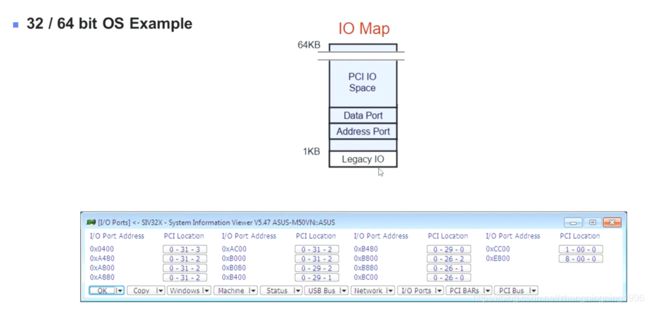
这里需要说明IO Map的访问主要通过Data Port作为数据,Address Port作为地址访问PCI Configuration Space的16MB空间。
Memory Map示例
对于32位操作系统:
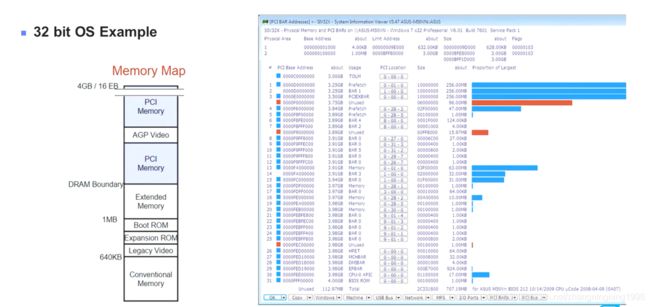
对于64位操作系统:

从上面可以看出PCIE分配的Base Address,不管32位64位操作系统都分配到了4G以下,这方便软件与PCIE设备的兼容性。
IO Map示例
PCIE地址空间
PCIE设备分配到哪些地址空间
PCle中有四个地址空间。
Configuration Space:配置空间,每个Function都包含内部寄存器配置空间,允许软件可以看见和控制其地址和资源。
Memory Space:内存空间,映射同一组特定于设备的寄存器在内存地址空间和IO Spcace一样的方式。
I/O Space:输入输出空间,在pc的早期,内部寄存器/存储在I0设备被访问通过IO地址空间。
Message Space:信息空间,这是一个新的地址空间在PCI中没有该地址空间。这个地址的存在消除了对物理边带信号的需要,如中断。可以减少PCI的引脚,将中断信号变成Message的TLP包进行传输,进而减少了PCI中物理引脚的个数。
Configuration Space
首先PC机需要用户设置开关和跳线分配资源为每个安装在主板上的PCIE设备,这经常导致内存冲突,IO和中断设置。
然后I/O架构,Extended ISA (EISA)和IBM PS2系统,是第一个实现即插即用架构的。在这些架构中,配置文件被分配给每个设备,进而允许系统软件分配基本资源为每个设备。

PCI设备的Configuration Space是4KB,而PCIE是4KB。PCIE多出了PCIE Extended space,该空间只能被PCIE Enhanced Configuration Access Mechanism进行访问。
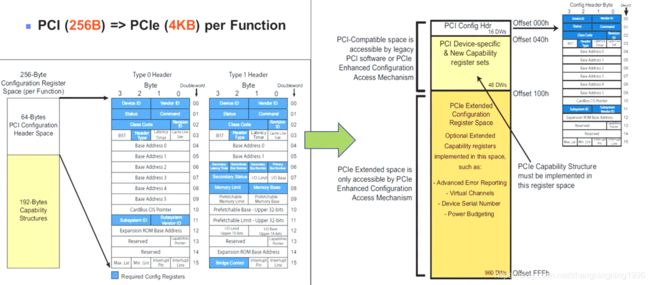
这里配置空间分为Type1与Type2两种,对于Switch,Root Complex、Bridge是Type1型,对于Endpoint是Type0型。
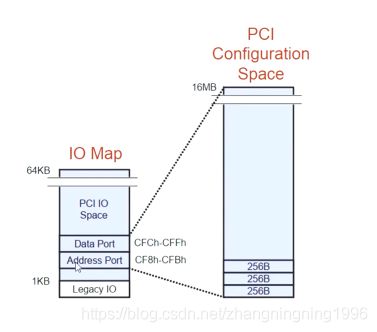
PCI协议的Configuration Space是通过IO读写的方式间接读写的,这里为什么是间接读写,因为PCI协议的IO读写只有64KB的大小,但是PCI的Configuration Space足足有16MB的空间大小,所以只能间接访问。
那么为什么PCI的Configuration Space有16MB的大小呢?

与Configuration Space相关联的寄存器如下:

间接访问的方式是利用IO Map中的Address Port作为PCI Configuration Space的地址,Data Port作为PCI Configuration Space的数据进行相应的Configuration Space的访问,如下图:
PCIE协议的Configuration Space使用的是Memory Map的方式进行的访问,这个方式又被称为MMIO,但是仍是Memory Map的方式。那么PCIE协议每一个Function的Configuration Space被由256B扩展到4KB,那么总的Configuration Space的大小是256MB,具体的计算方法如下:

在System Information Viewer中可以进行查看
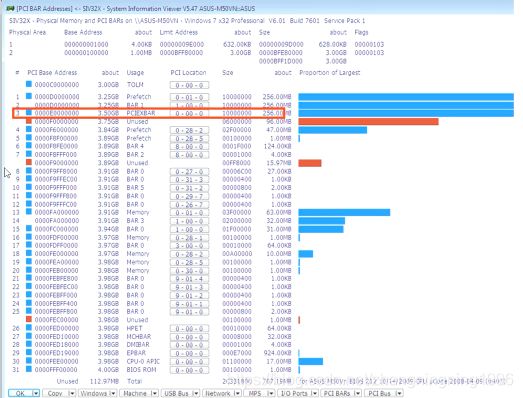
PCIE Configuration Space的示例
在这个例子中,PCIE Configuration Space的其实地址是0xE0000000,那么如何判断哪一个设备是我们常说的 Configuration Space呢?其实在PCIE的拓扑图中,编号Bus = 0,Device = 0,Function = 0的设备就是Configuration Space也被称为Host Bridge,在地址中的存储是按照TLP包的形式进行存储,如下图:

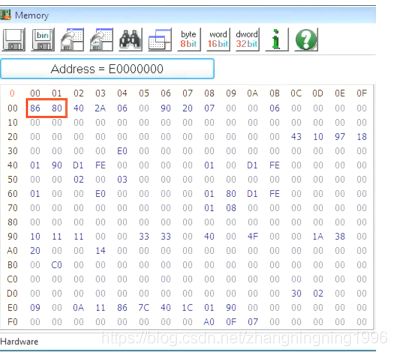
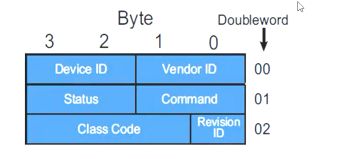
由前面的知识可知,TLP包的前两个字节是厂商ID,那么上面的前两个字节是8086也就是Intel给自己厂家分配的厂商ID。那么我们知道,每个PCIE Function的Configuration Space大小是4KB,所有的PCIE设备占有256MB的配置空间,那么我们如何查找其他设备的配置空间呢?
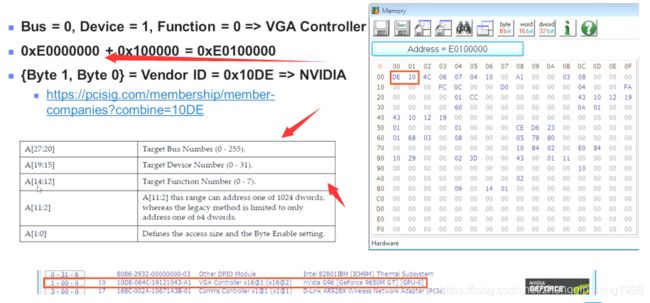
PCIE Memory Space与IO Space的对比
在pc机的早期,内部寄存器/存储在I0设备被访问通过IO Space来进行相应的读写(由英特尔定义)。然而,由于与lO地址空间相关的一些限制和不良影响,该地址空间很快就失去了软件和硬件供应商的青睐。
因为上面的不利影响,这导致IO设备的内部寄存器/存储被映射到内存Memory Space(通常称为memory-mapped IO,或MMIO),但是注意这仍然是Memory Space。
这允许新软件使用内存地址空间(MMIO)访问设备的内部寄存器,同时允许旧软件继续运行,因为它仍然可以使用IO Space访问设备的内部寄存器。
较新的PCIE设备通常不依赖旧软件或存在遗留兼容性问题,只是通过内存地址空间(MMIO)映射内部寄存器/存储,而不请求lO Map Space。
事实上,PCle规范实际上不鼓励使用IO地址空间,这表明它只受PCI协议的遗留原因的支持,将来可能会被弃用。
PCIE Memory Space示例
只需要使用System Information Viewer软件查看PCIE的拓扑图,然后,查找相应Function的地址,最后使用Read & Write Utility软件读取相应地址位置的数据即可。

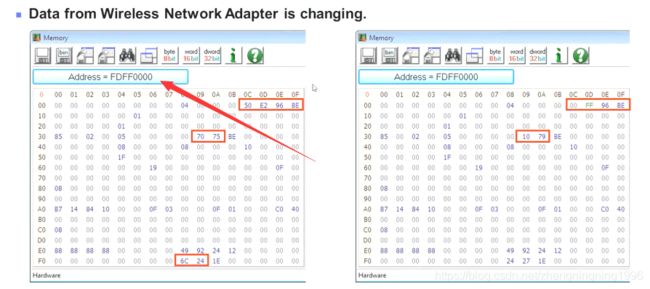
PCIE IO Space示例
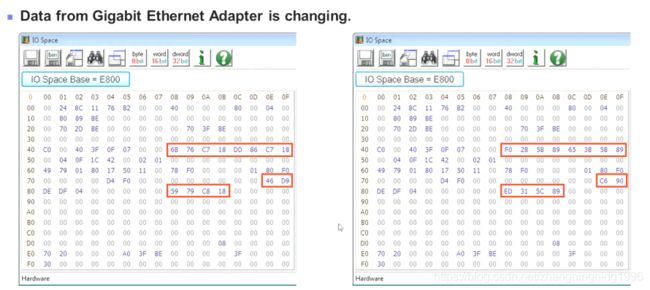
总结
上面所有的实践都基于三个软件
[1]、System Information Viewer
[2]、MindShare Arbor
[3]、Read & Write Utility
这些软件可以去网上下载,嫌麻烦的同学也可以进群和我要。至此,PCIE概述部分讲解完毕,接下来详细总结PCIE协议。
创作不易,认为文章有帮助的同学们可以关注、点赞、转发支持。为行业贡献及其微小的一部分。对文章有什么看法或者需要更近一步交流的同学,可以加入下面的群:
