[论文阅读](Image Quality Assessment using Contrastive Learning)
文章目录
- 摘要
- 引言
- 方法
-
- 1. 辅助任务
- 保持质量不变的变换
-
- 补充:颜色空间
- 补充:局部归一化
- Evaluating Representations
- 实验结果
-
- 1.训练数据
- 2. 实验
- 3.可视化
摘要
一种自我监督的方式获取图像质量表示的问题。
我们使用畸变类型和程度的预测作为辅助任务,从包含合成和真实混合失真的未标记图像数据集学习特征。然后,我们训练一个深度卷积神经网络(CNN)使用一个contrastive pairwise来解决辅助问题。
我们将提出的训练框架和产生的深层IQA模型作为对比图像质量评估器(CONTRIQUE)。在评估期间,CNN权重被冻结,线性回归器将学习的表示映射到NR设置中的质量分数。我们通过大量的实验表明,与最先进的NR图像质量模型相比,CONTRIQUE获得了具有竞争力的性能,即使没有任何额外的CNN骨干微调。
学习后的表征具有高度的鲁棒性,并且在受合成或真实扭曲影响的图像中具有很好的泛化能力。我们的结果表明,不需要大量标注主观图像质量数据集,就可以获得具有感知相关性的强大质量表征
引言
开发基于CNN的IQA模型的一个障碍是缺乏足够大的标记IQA数据集。注释IQA数据集是一个昂贵且劳动密集型的过程。大多数可用的IQA数据集都太小,无法从头开始有效地训练深度CNN模型。
正因为如此,大多数基于CNN的IQA模型都利用了迁移学习,即CNN在像ImageNet[19]这样的大型数据集上进行预训练,然后对具有主观质量判断的图像进行端到端精细调整。
尽管经过微调的模型在合成失真和真实失真方面都取得了令人印象深刻的性能,但微调需要仔细选择超参数,这些超参数可能随不同的IQA数据库而变化。此外,过度的微调会使模型对训练数据过拟合,限制了模型的泛化能力。
我们引入了一个基于对比学习的IQA训练框架,旨在使用无标记数据集获得高效的图像质量表示
方法
_第1张图片](http://img.e-com-net.com/image/info8/724a1b06d6854bd59bdc9ce57542ed85.jpg)
代码链接
1. 辅助任务
学习问题的辅助任务是一种交替但密切相关的任务,其标签是已知的或很容易获得的。
该方法先训练模型求解一个辅助问题,然后在推理阶段,根据原任务对训练后的模型进行评估。对于IQA,目标是获得能够区分不同类型的扭曲以及退化程度的区别表示。因此,我们将IQA表示学习问题转化为分类问题,其中每一类由具有相似失真类型和相似质量退化程度的图像组成。辅助任务的目标是学习特征,可以将图像区分成与失真相关的类,在训练过程中使用交叉熵目标来实现这一点。
在CONTRIQUE框架中,每个UGC图像都被视为一个独特的类,它是由多种扭曲的独特组合获得的,与其他UGC图像和人工合成的图像是不同的。因此,对于给定的UGC图像xi,只有它的缩放(和转换)版本xj属于同一个类。
损失函数:


其中N为batch中出现的图像个数,P(i)为包含与xi同类图像指标的集合(但不包括指标i), |P(i)|为其基数。目标函数(2)与[34]中提出的有监督的对比损失相似。
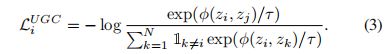
损失函数参考图解SimCLR框架,用对比学习得到一个好的视觉预训练模型
保持质量不变的变换
resize+抗混叠滤波器+crop:
这里做的一个简化的假设是,裁剪后的版本继承了与原始版本相同的失真类。虽然裁剪后的版本不需要代表与原始图像相同的感知质量,我们假设失真类保持几乎相同,不受裁剪操作的影响。
对于每个输入的图像,得到两个随机作物,一个在全尺寸和半尺度。对于图像大小小于M*M的情况,整个图像使用零填充来保持相同的分辨率。此外,裁剪可以批量提供固定分辨率的图像,这在训练深度网络时至关重要,因为使用可变分辨率的训练可能具有挑战性和不稳定性
颜色空间变换+带通变换:
我们将这些模型部署在各种颜色空间中,既代表彩色图像感知,又代表带宽高效和感知驱动的颜色处理。在各种互补的感知相关的颜色和变换域空间中定义的大量特征集合驱动了我们基于特征映射的方法
我们还采用了一个带通变换,用局部均值减法(MS)获得。质谱系数已被证明可以捕捉由于图像失真而产生的统计偏差。在图1所示的训练管道中,**对输入图像的每一裁剪随机选择颜色空间。**通过在训练过程中使用不同的颜色空间,正如我们在第IV-F节中所展示的那样,在测试过程中使用任何颜色空间都会得到类似的表示,使CONTRIQUE对颜色空间保持不变。请注意,我们避免使用积极的增强技术,如颜色抖动、高斯模糊、随机调整大小、MixUp、AutoAugment等,因为这些方法修改了失真信息,因此不能保持质量。
补充:颜色空间
-
自然界的颜色千变万化,为了给颜色一个量化的衡量标准,就需要建立色彩空间模型来描述各种各样的颜色,由于人对色彩的感知是一个复杂的生理和心理联合作用 的过程,所以在不同的应用领域中为了更好更准确的满足各自的需求,就出现了各种各样的色彩空间模型来量化的描述颜色。
-
颜色空间有很多种,常见的有 RGB,CMY,HSV,HSI 等,他们都是采用三个不同的属性(亮度,饱和度和色度)来实现对颜色的描述,不同颜色空间可以相互转换。
-
**使用不同颜色空间的动机是为了提取可以跨不同领域呈现的互补质量信息。**在我们提出的框架中,我们采用了4个颜色空间:RGB、LAB、HSV和灰度。每个颜色空间都具有不同类型的感知相关性,并已在早期的基于NSS的模型中被用于获取质量特征。
-
我们在不同的颜色空间和变换域中研究了真实失真图像的感知相关的自然场景统计。
-
颜色通常用三个相对独立的属性来描述,三个独立变量综合作用,自然就构成一个空间坐标,这就是颜色空间。而颜色可以由不同的角度,用三个一组的不同属性加以描述,就产生了不同的颜色空间。但被描述的颜色对象本身是客观的,不同颜色空间只是从不同的角度去衡量同一个对象。
-
颜色空间按照基本结构可以分两大类:基色颜色空间和色、亮分离颜色空间。前者的典型是 RGB,还包括 CMY、CMYK、CIE XYZ 等;后者包括 YCC/YUV、Lab、以及一批“色相类颜色空间”。CIE XYZ 是定义一切颜色空间的基准,很奇妙的是,它即属于基色颜色空间,也属于色、亮分离颜色空间,是贯穿两者的枢纽。
-
RGB:
计算机色彩显示器显示色彩的原理与彩色电视机一样,都是采用R、G、B相加混色的原理,通过发射出三种不同强度的电子束,使屏幕内侧覆盖的红、绿、蓝磷光材料发光而产生色彩的。这种色彩的表示方法称为RGB色彩空间表示。在多媒体计算机技术中,用的最多的是RGB色彩空间表示。
根据三基色原理,用基色光单位来表示光的量,则在RGB色彩空间,任意色光F都可以用 RGB三色不同分量的相加混合而成:

我们可知自然界中任何一种色光都可由R、G、B三基色按不同的比例相加混合而成,当三基色分量都为0(最弱)时混合为黑色光;当三基色分量都为k(最强)时混合为白色光。任意色彩F是这个立方体坐标中的一点,调整三色系数r、g、b中的任一系数都会改变F的坐标值,也即改变了F的色值。RGB色彩空间采用物理三基色表示,因而物理意义很清楚,适合彩色显象管工作。然而这一体制并不适应人的视觉特点。因而,产生了其它不同的色彩空间表示法。
_第2张图片](http://img.e-com-net.com/image/info8/abeb7ffb5f0647b8b3ed9141a9963fd8.jpg)
色彩空间表示与转换
各种基于RGB原色的色彩空间,不同波长的光分布的疏密程度是不同的,这意味着在这个空间中颜色的分布是不均匀的。简单说,色度的分布和我们的实际感知结果并不吻合,两种相邻的色彩可能在感知上被认为是差异明显的,而相距较远的色彩可能是无法区分的。在色彩科学议题上,这被称为感知均匀性(Perceptual Uniformity)问题。
-
HSV
HSV(Hue色相,Saturation饱和度,Value亮度)颜色空间的模型
艺术家有时偏好使用 HSV 颜色模型而不选择 RGB 或 CMYK 模型,因为它类似于人类感觉颜色的方式。RGB 和 CMYK 分别是加法原色和减法原色模型,以原色组合的方式定义颜色,而 HSV 以人类更熟悉的方式封装了关于颜色的信息:“这是什么颜色?深浅如何?明暗如何?”。
HSV颜色空间可以用一个圆锥空间模型来描述。
_第3张图片](http://img.e-com-net.com/image/info8/9ef7051019254ee5b62de9ad15082fd7.jpg)
-
LAB
Lab模式由三个通道组成,但不是R、G、B通道。它的一个通道是亮度,即L,取值范围是[0,100],表示从纯黑到纯白。另外两个是色彩通道,用A和B来表示。A通道包括的颜色是从深绿色(底亮度值)到灰色(中亮度值)再到亮粉红色(高亮度值),取值范围是[127,-128];B通道则是从亮蓝色(底亮度值)到灰色(中亮度值)再到黄色(高亮度值),取值范围是[127,-128]。因此,这种色彩混合后将产生明亮的色彩。
Lab模式所定义的色彩最多,且与光线及设备无关
补充:局部归一化
提取自然场景统计信息(NSS)
自然图像的像素强度分布与失真图像的像素强度分布不同。当我们对像素强度进行归一化并在这些归一化强度上计算分布时,分布上的差异更加明显。特别地,在归一化之后,自然图像的像素强度遵循高斯分布(贝尔曲线),而非自然或失真图像的像素强度则不遵循高斯分布(贝尔曲线)。因此,分布曲线与理想高斯曲线的偏差是图像失真量的度量。具体形式入下图所示。
_第4张图片](http://img.e-com-net.com/image/info8/a21d4c79b8fa4899812d3efaf2723fc7.jpg)
图4左侧:显示没有添加人工效果的自然图像,符合高斯分布。右图:人造图像,不太适合同一分布
均值减去对比度归一化(MSCN)
有几种不同的标准化图像的方法。我们使用均值减去对比度归一化(MSCN)。下图显示了如何计算MSCN系数。
_第5张图片](http://img.e-com-net.com/image/info8/01a2206a902e447381787a0f9ce0d412.jpg)
_第6张图片](http://img.e-com-net.com/image/info8/2155d4c2346542d699febe166b42e645.jpg)
_第7张图片](http://img.e-com-net.com/image/info8/1f891677ff884e54a248e8304117dfdb.jpg)
参考
brisque & NIQE
_第8张图片](http://img.e-com-net.com/image/info8/09d80f50361b4f6eb4499d0395b08852.jpg)
_第9张图片](http://img.e-com-net.com/image/info8/38f2153126924c2c89938895c3a84f80.jpg)
Evaluating Representations
我们通过将学习到的表征应用于质量预测问题来评估它们,使用人类判断与预测质量分数的相关性作为表征质量的代理。训练完成后,丢弃projector network g(.),使用编码器网络h = f(x)的输出作为图像表示。我们使用正则化线性回归(脊回归)在冻结的编码器网络上训练。这类似于[28]、[45]、[46]中评估自监督模型分类精度的线性评估协议。回归权重是在一个包含地面真实质量分数的合适的IQA数据库上学习的。脊回归的表达式为:

式中GT表示ground-truth质量分数,y表示预测分数,W为与h维数相同的可训练向量,λ为正则化参数,M为h维数,N为训练集中出现的图像个数。与训练类似,我们遵循多尺度约定,并在两种分辨率下计算特征:满尺和半尺,最后的表示是这两种尺度的拼接。
在评估过程中,所有表示都是在输入图像的原始分辨率上计算的,并且没有执行额外的数据增强。请注意,我们没有执行任何额外的微调,编码器的权重将被修改使用地面真实质量分数的监督。
**虽然微调可能产生更好的性能,但我们避免它,因为它会改变已学习的编码器权重,而且它不会是无监督训练过程效率的真正指标(it would not be a true indicator of the efficiency of the unsupervised training process)。**此外,我们在第IV-B节中指出,即使不进行微调,与SOTA IQA模型相比,CONTRIQUE也能达到具有竞争力的性能。
实验结果
1.训练数据
_第10张图片](http://img.e-com-net.com/image/info8/60066056fc154c24ada3e299c5e4a346.jpg)
_第11张图片](http://img.e-com-net.com/image/info8/269b35dfdbb44eedb29accd0d7bc7d5f.jpg)
2. 实验
_第12张图片](http://img.e-com-net.com/image/info8/808bbadf661e478fa8ab057b5944190c.jpg)
_第13张图片](http://img.e-com-net.com/image/info8/6cd3611caa4d4c0da1e7495b7ffe400c.jpg)
3.可视化
使用t-sne,学习后的CONTRQUE表示如图所示。在图中,为了绘制图像,我们使用了4种常见的合成失真:白噪声、高斯模糊、JPEG和JPEG200,以及自然图像和UGC图像。每一组包含150幅图像,其中包含来自CSIQ-IQA数据集的合成失真,而自然图像和UGC图像分别来自KADIS和KonIQ数据集。为了比较,我们还在图2中包含了Resnet-50 (Imagenet预训练)的特征。由于辅助任务是学习失真可鉴别嵌入,学习的CONTRIQUE特征可以根据失真的类型很容易地进行聚类,如图2所示。然而,Resnet-50特征却并非如此,因为它们似乎分散在空间中,并没有形成可分离的簇。图2也说明了对于白噪声和JPEG压缩失真,CONTRIQUE特征的退化级别可分性。
_第14张图片](http://img.e-com-net.com/image/info8/7cc6f0d4875348f28ee8fd13ff4b5074.jpg)