Pytorch总结十三之 神经网络模型:批量归一化、ResNet、DenseNet
Pytorch总结十三之 神经网络模型:ResNet、DenseNet
- 本节将介绍批量归一化(batch normalization)层,它能让较深的神经网络的训练变得更加容易。在实战Kaggle比赛 - 预测房价里,我们对输入数据做了标准化处理:处理后的任意一个特征在数据集中的所有样本上的均值为0,标准差为1。标准化处理输入数据使各个特征的分布相近,这往往更容易训练出有效的模型。
- 通常来说,数据标准化预处理对于浅层模型就⾜够有效了。随着模型训练的进⾏,当每层中参数更新时,靠近输出层的输出较难出现剧烈变化。但对深层神经⽹络来说,即使输⼊数据已做标准化,训练中模型参数的更新依然很容易造成靠近输出层输出的剧烈变化。这种计算数值的不稳定性通常令我们难以训练出有效的深度模型。
- 批量归⼀化的提出正是为了应对深度模型训练的挑战。在模型训练时,批量归⼀化利⽤⼩批量上的均值和标准差,不断调整神经⽹络中间输出,从⽽使整个神经⽹络在各层的中间输出的数值更稳定。批量归⼀化和下⼀节将要介绍的残差⽹络为训练和设计深度模型提供了两类重要思路。
1.批量归一化
对全连接层和卷积层做批量归⼀化的⽅法稍有不同。下⾯我们将分别介绍这两种情况下的批量归⼀化。
1.1 对全连接层做批量归一化


1.2 对卷积层做批量归一化

1.3 预测时的批量归一化
使⽤批量归⼀化训练时,我们可以将批量⼤⼩设得⼤⼀点,从⽽使批量内样本的均值和⽅差的计算都较为准确。将训练好的模型⽤于预测时,我们希望模型对于任意输⼊都有确定的输出。因此,单个样本的输出不应取决于批量归⼀化所需要的随机⼩批量中的均值和⽅差。⼀种常⽤的⽅法是通过移动平均估算整个训练数据集的样本均值和⽅差,并在预测时使⽤它们得到确定的输出。可⻅,和丢弃层⼀样,批量归⼀化层在训练模式和预测模式下的计算结果也是不⼀样的。
#批量归一化
import time
import torch
from torch import nn,optim
import torch.nn.functional as F
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l
device=torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def batch_norm(is_training,X,gamma,beta,moving_mean,moving_var,eps,momentum):
#判断当前模式是训练模式还是预测模式
if not is_training:
#如果是预测模式下,直接使用传入的移动平均所得的均值和方差
x_hat=(X - moving_mean)/torch.sqrt(moving_var+eps)
else:
assert len(X.shape) in (2,4)
if len(X.shape)==2:
#使用全连接层的情况,计算特征维上的均值和方差
mean=X.mean(dim=0)
var=((X-mean)**2).mean(dim=0)
else:
#使用二维卷积层的情况,计算通道上(axis=1)的均值和方差,这里需要保持x的形状以便后边做广播运算
mean=X.mean(dim=0,keepdim=True).mean(dim=2,keepdim=True).mean(dim=3,keepdim=True)
var=((X-mean)**2).mean(dim=0,keepdim=True).mean(dim=2,keepdim=True).mean(dim=3,keepdim=True)
#训练模式下用当前的均值和方差做标准化
X_hat=(X-mean)/torch.sqrt(var+eps)
#更新移动平均的均值和方差
moving_mean=momentum*moving_mean+(1.0-momentum)*mean
moving_var=momentum*moving_var+(1.0-momentum)*var
Y=gamma*X_hat+beta #拉伸和平移
return Y,moving_mean,moving_var
接下来,我们⾃定义⼀个 BatchNorm 层。它保存参与求梯度和迭代的拉伸参数 gamma 和偏移参数 beta ,同时也维护移动平均得到的均值和⽅差,以便能够在模型预测时被使⽤。 BatchNorm 实例所需指定的 num_features 参数对于全连接层来说应为输出个数,对于卷积层来说则为输出通道数。该实例所需指定的 num_dims 参数对于全连接层和卷积层来说分别为 2 和 4 。
class BatchNorm(nn.Module):
def __init__(self,num_features,num_dims):
super(BatchNorm, self).__init__()
if num_dims==2:
shape=(1,num_features)
else:
shape=(1,num_features,1,1)
#参与求梯度和迭代的拉伸和偏移参数,分别初始化为 0 和 1
self.gamma=nn.Parameter(torch.ones(shape))
self.bata=nn.Parameter(torch.zeros(shape))
#不参与求梯度和迭代的变量,全在内存上初始化成0
self.moving_mean=torch.zeros(shape)
self.moving_var=torch.zeros(shape)
def forward(self,X):
#如果不在内存上,将moving_mean 和moving_var 复制到x所在显存上
if self.moving_mean.device!=X.device:
self.moving_mean=self.moving_mean.to(X.device)
self.moving_var=self.moving_var.to(X.device)
#保存更新过的moving_mean和moving_var,Model实例的training属性默认为true,调用.eval()后设成false
Y,self.moving_mean,self.meaning_var=batch_norm(self.training,X,self.gamma.self.beta,
self.moving_mean,self.moving_var,
eps=1e-5,momentum=0.9)
return Y
1.4 使用批量归一化层的LeNet
在所有的卷积层或全连接层之后、激活层之前加入批量归一化层:
net = nn.Sequential(
nn.Conv2d(1, 6, 5), # in_channels, out_channels,kernel_size
BatchNorm(6, num_dims=4),
nn.Sigmoid(),
nn.MaxPool2d(2, 2), # kernel_size, stride
nn.Conv2d(6, 16, 5),
BatchNorm(16, num_dims=4),
nn.Sigmoid(),
nn.MaxPool2d(2, 2),
d2l.FlattenLayer(),
nn.Linear(16 * 4 * 4, 120),
BatchNorm(120, num_dims=2),
nn.Sigmoid(),
nn.Linear(120, 84),
BatchNorm(84, num_dims=2),
nn.Sigmoid(),
nn.Linear(84, 10)
)
batch_size = 256
train_iter, test_iter =d2l.load_data_fashion_mnist(batch_size=batch_size)
lr, num_epochs = 0.001, 5
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
d2l.train_ch5(net, train_iter, test_iter, batch_size, optimizer,device, num_epochs)
bug----尚未解决!

1.5 简洁实现
与我们刚刚⾃⼰定义的 BatchNorm 类 相 ⽐ , Pytorch 中 nn 模 块 定 义 的 BatchNorm1d 和BatchNorm2d 类 使 ⽤ 起 来 更 加 简 单 ,⼆ 者 分 别 ⽤ 于 全 连 接 层 和 卷 积 层 , 都 需 要 指 定 输 ⼊ 的num_features 参数值。下⾯我们⽤PyTorch实现使⽤批量归⼀化的LeNet。
net = nn.Sequential(
nn.Conv2d(1, 6, 5), # in_channels, out_channels,kernel_size
nn.BatchNorm2d(6),
nn.Sigmoid(),
nn.MaxPool2d(2, 2), # kernel_size, stride
nn.Conv2d(6, 16, 5),
nn.BatchNorm2d(16),
nn.Sigmoid(),
nn.MaxPool2d(2, 2),
d2l.FlattenLayer(),
nn.Linear(16 * 4 * 4, 120),
nn.BatchNorm1d(120),
nn.Sigmoid(),
nn.Linear(120, 84),
nn.BatchNorm1d(84),
nn.Sigmoid(),
nn.Linear(84, 10)
)
#测试训练:
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)
lr, num_epochs = 0.001, 5
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
d2l.train_ch5(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs)
output:
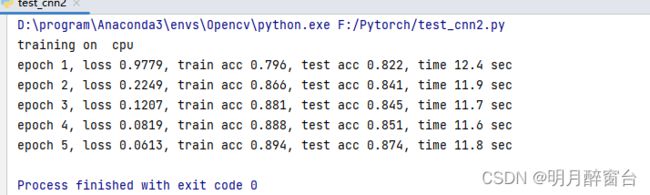
1.6 小结
- 在模型训练时,批量归⼀化利⽤⼩批量上的均值和标准差,不断调整神经⽹络的中间输出,从⽽使整个神经⽹络在各层的中间输出的数值更稳定。
- 对全连接层和卷积层做批量归⼀化的⽅法稍有不同。
- 批量归⼀化层和丢弃层⼀样,在训练模式和预测模式的计算结果是不⼀样的。
- PyTorch提供了BatchNorm类⽅便使⽤。
2.残差网络(RESNET)
在实践中,添加过多的层后训练误差往往不降反升。即使利⽤批量归⼀化带来的数值稳定性使训练深层模型更加容易,该问题仍然存在。针对这⼀问题,何恺明等⼈提出了残差⽹络(ResNet)。它在2015年的ImageNet图像识别挑战赛夺魁,并深刻影响了后来的深度神经⽹络的设计。
2.1 残差块

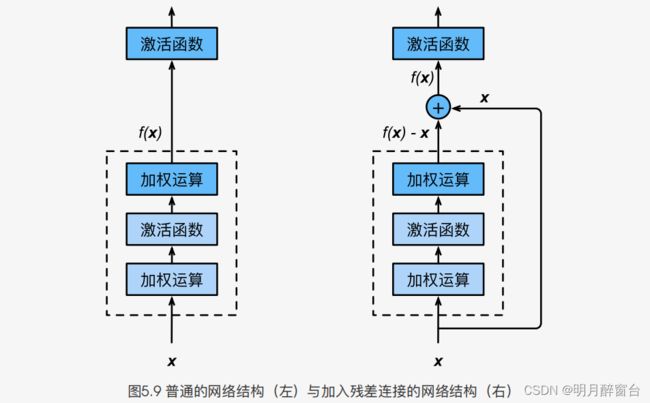
- ResNet 沿用了 VGG 全
3x3卷积层的设计。残差块里首先有2个相同输出通道数的3x3卷积层。每个卷积层后接一个批量归一化层和ReLU激活函数。然后我们将输入跳过这两个卷积运算后直接加载最后的ReLU激活函数前。这样的设计要求两个卷积层的输出和输入形状一样,从而可以想加。如果想改变通道数,就需要引入一个额外的1x1卷积层来将输入变换成需要的形状后在做相加运算。 - 残差块的实现如下,它可以设定输出通道数、是否使用额外的
1x1卷积层来修改通道数以及卷积层的步幅。
#Resnet
import time
import torch
from torch import nn,optim
import torch.nn.functional as F
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l
device=torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class Residual(nn.Module):
def __init__(self,in_channels,out_channels,use_1x1conv=False,stride=1):
super(Residual, self).__init__()
self.conv1=nn.Conv2d(in_channels,out_channels,kernel_size=3,padding=1,stride=stride)
self.conv2=nn.Conv2d(out_channels,out_channels,kernel_size=3,padding=1)
if use_1x1conv:
self.conv3=nn.Conv2d(in_channels,out_channels,kernel_size=1,stride=stride)
else:
self.conv3=None
self.bn1=nn.BatchNorm2d(out_channels)
self.bn2=nn.BatchNorm2d(out_channels)
def forward(self,X):
Y=F.relu(self.bn1(self.conv1(X)))
Y=self.bn2(self.conv2(Y))
if self.conv3:
X=self.conv3(X)
return F.relu(Y+X)
测试输出:
#see the output:
blk=Residual(3,3)
X=torch.rand((4,3,6,6))
print(blk(X).shape)
#在增加输出通道数的同事减半输出的高和宽
blk=Residual(3,6,use_1x1conv=True,stride=2)
print(blk(X).shape)

2.2 ResNet模型
ResNet的前两层和之前介绍的GooLeNet中的一样:在输出通道数为64、步幅为2的7x7卷积层后接步幅为3x3的最大池化层。不同之处在于ResNet每个卷积层后层架的批量归一化层。
net=nn.Sequential(nn.Conv2d(1,64,kernel_size=7,stride=2,padding=3),
nn.BatchNorm2d(64), #批量归一化
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1))
- GoogLeNet在后面接了4个由Inception块组成的模块。ResNet则使用4个残差块组成的模块,每个模块使用若干个同样输出通道数的残差块。第一个模块的通道数同输入通道数一致,由于之前已经使用了步幅为2的最大池化层,所以无需减小高和宽。之后的每个模块在第一个残差快里将上一个模块的通道数翻倍,并将高和宽减半。
- 下⾯我们来实现这个模块。注意,这⾥对第⼀个模块做了特别处理。
def resnet_block(in_channels,out_channels,num_residuals,first_block=False):
if first_block:
assert in_channels==out_channels
blk=[]
for i in range(num_residuals):
if i==0 and not first_block:
blk.append((Residual(in_channels,out_channels,use_1x1conv=True,stride=2)))
else:
blk.append(Residual(out_channels,out_channels))
return nn.Sequential(*blk)
接着我们为ResNet加⼊所有残差块。这⾥每个模块使⽤两个残差块。
#接着,为resnet加入所有残差块,每个模块使用两个残差块
net.add_module('resnet_block1',resnet_block(64,64,2,first_block=True))
net.add_module('resnet_block2',resnet_block(64,128,2))
net.add_module('resnet_block3',resnet_block(128,256,2))
net.add_module('resnet_block4',resnet_block(256,512,2))
最后,与GoogLeNet⼀样,加⼊全局平均池化层后接上全连接层输出:
#加入全局平均池化层后街上全连接层输出
net.add_module('global_avg_pool',d2l.GlobalAvgPool2d())
net.add_module('fc',nn.Sequential(d2l.FlattenLayer(),nn.Linear(512,10)))
- 这⾥每个模块⾥有4个卷积层(不计算
1x1卷积层),加上最开始的卷积层和最后的全连接层,共计18层。这个模型通常也被称为ResNet-18。通过配置不同的通道数和模块⾥的残差块数可以得到不同的ResNet模型,例如更深的含152层的ResNet-152。虽然ResNet的主体架构跟GoogLeNet的类似,但ResNet结构更简单,修改也更⽅便。这些因素都导致了ResNet迅速被⼴泛使⽤。
在训练ResNet之前,我们来观察⼀下输⼊形状在ResNet不同模块之间的变化:
X = torch.rand((1, 1, 224, 224))
for name, layer in net.named_children():
X = layer(X)
print(name, ' output shape:\t', X.shape)
output:

2.3 获取数据和训练模型
在Fashion-MNIST数据集上训练ResNet
#获取数据和训练模型
batch_size = 256
# 如出现“out of memory”的报错信息,可减⼩batch_size或resize
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size,resize=96)
lr, num_epochs = 0.001, 5
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
d2l.train_ch5(net, train_iter, test_iter, batch_size, optimizer,device, num_epochs)

2.4 小结
- 残差块通过跨层的数据通道从而能够训练出有效的深度神经网络
- ResNet深刻影响了后来的深度神经网络的设计
3.稠密连接网络(DENSENET)
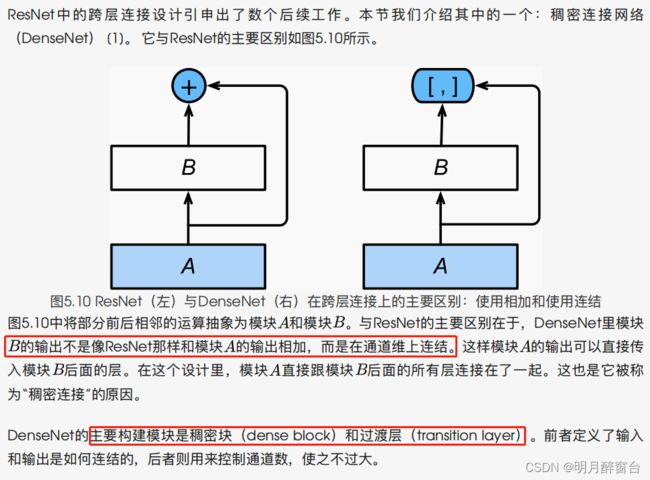
3.1 稠密块
- DenseNet使⽤了ResNet改良版的“批量归⼀化、激活和卷积”结构,我们⾸先在 conv_block 函数⾥实现这个结构。
import time
import torch
from torch import nn, optim
import torch.nn.functional as F
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def conv_block(in_channels, out_channels):
blk = nn.Sequential(nn.BatchNorm2d(in_channels),
nn.ReLU(),
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))
return blk
稠密块由多个 conv_block 组成,每块使⽤相同的输出通道数。但在前向计算时,我们将每块的输⼊和
输出在通道维上连结。
class DenseBlock(nn.Module):
def __init__(self, num_convs, in_channels, out_channels):
super(DenseBlock, self).__init__()
net = []
for i in range(num_convs):
in_c = in_channels + i * out_channels
net.append(conv_block(in_c, out_channels))
self.net = nn.ModuleList(net)
self.out_channels = in_channels + num_convs * out_channels # 计算输出通道数
def forward(self, X):
for blk in self.net:
Y = blk(X)
X = torch.cat((X, Y), dim=1) # 在通道维上将输入和输出连结
return X
在下⾯的例⼦中,我们定义⼀个有2个输出通道数为10的卷积块。使⽤通道数为3的输⼊时,我们会得到通道数为3+2x10=23 的输出。卷积块的通道数控制了输出通道数相对于输⼊通道数的增⻓,因此也被称为增⻓率(growth rate)。
blk = DenseBlock(2, 3, 10)
X = torch.rand(4, 3, 8, 8)
Y = blk(X)
print(Y.shape) # torch.Size([4, 23, 8, 8])
3.2 过渡层
由于每个稠密块都会带来通道数的增加,使⽤过多则会带来过于复杂的模型。过渡层⽤来控制模型复杂度。它通过 1x1 卷积层来减⼩通道数,并使⽤步幅为2的平均池化层减半⾼和宽,从⽽进⼀步降低模型复杂度。
def transition_block(in_channels, out_channels):
blk = nn.Sequential(
nn.BatchNorm2d(in_channels),
nn.ReLU(),
nn.Conv2d(in_channels, out_channels, kernel_size=1),
nn.AvgPool2d(kernel_size=2, stride=2))
return blk
对上一个例子中稠密块的输出使用通道数为10的过渡层。此时输出的通道数减为10,高和宽均减半。
blk = transition_block(23, 10)
print(blk(Y).shape) # torch.Size([4, 10, 4, 4])
3.3 DenseNet模型
- 我们来构造DenseNet模型。DenseNet首先使用同ResNet一样的单卷积层和最大池化层。
net = nn.Sequential(
nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
- 类似于ResNet接下来使用的4个残差块,DenseNet使用的是4个稠密块。同ResNet一样,我们可以设置每个稠密块使用多少个卷积层。这里我们设成4,从而与上一节的ResNet-18保持一致。稠密块里的卷积层通道数(即增长率)设为32,所以每个稠密块将增加128个通道。
- ResNet里通过步幅为2的残差块在每个模块之间减小高和宽。这里我们则使用过渡层来减半高和宽,并减半通道数
num_channels, growth_rate = 64, 32 # num_channels为当前的通道数
num_convs_in_dense_blocks = [4, 4, 4, 4]
for i, num_convs in enumerate(num_convs_in_dense_blocks):
DB = DenseBlock(num_convs, num_channels, growth_rate)
net.add_module("DenseBlosk_%d" % i, DB)
# 上一个稠密块的输出通道数
num_channels = DB.out_channels
# 在稠密块之间加入通道数减半的过渡层
if i != len(num_convs_in_dense_blocks) - 1:
net.add_module("transition_block_%d" % i, transition_block(num_channels, num_channels // 2))
num_channels = num_channels // 2
- 同ResNet一样,最后接上全局池化层和全连接层来输出。
net.add_module("BN", nn.BatchNorm2d(num_channels))
net.add_module("relu", nn.ReLU())
net.add_module("global_avg_pool", d2l.GlobalAvgPool2d()) # GlobalAvgPool2d的输出: (Batch, num_channels, 1, 1)
net.add_module("fc", nn.Sequential(d2l.FlattenLayer(), nn.Linear(num_channels, 10)))
打印每个子模块的输出维度确保网络无误:
X = torch.rand((1, 1, 96, 96))
for name, layer in net.named_children():
X = layer(X)
print(name, ' output shape:\t', X.shape)

3.4 获取数据并训练模型
- 由于这里使用了比较深的网络,本节里我们将输入高和宽从224降到96来简化计算。
batch_size = 256
# 如出现“out of memory”的报错信息,可减小batch_size或resize
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
lr, num_epochs = 0.001, 5
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
d2l.train_ch5(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs)
output:

3.5 小结
- 在跨连接层上,不同于ResNet 中将输入与输出相加,DenseNet 在通道维上连结输入与输出
- DenseNet的主要构建模块是稠密块和过渡层