模型剪枝简介
原题:Pruning Deep Neural Networks
原文:HTML
作者:Ranjeet Singh
如今,深度学习模型需要大量的计算、内存和电能,这成为我们需要实时推理或在计算资源有限的边缘设备和浏览器上运行模型的瓶颈。能效是当前深度学习模型的主要关注点,解决方法之一是提高推理效率。
Larger Model => More Memory References => More Energy
剪枝(pruning) 是一种用于推理的方法,以有效地产生尺寸更小、更节省内存、更省电和推理速度更快且精度损失最小的模型,其他这样的技术是权重共享(weight sharing)和量化(quantization)。深度学习从神经科学(Neuroscience)领域获得灵感的几个方面。深度学习中的剪枝也是一个受生物学启发的概念,我将在本文的稍后部分讨论。
随着深度学习的进步,最先进的模型越来越精确,但这种进步是有代价的。
First challenge — Models are getting larger
很难通过无线更新分发大型模型。
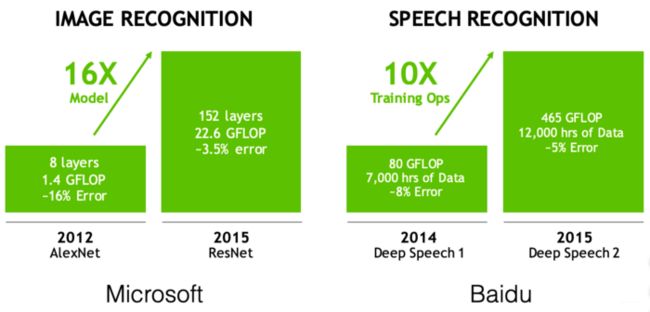
The Second Challenge: Speed

如此长的培训时间限制了ML研究员的生产力。
The Third Challenge: Energy Efficiency
AlphaGo: 1920 CPUs and 280 GPUs, $3000 electric bill per game。
- On Mobile devices: drains battery
- On data-center: increases TCO
Solution — Efficient Inference Algorithms
- Pruning
- Weight Sharing
- Quantization
- Low-Rank Approximation
- Binary / Ternary Net
- Winograd Transformation
Biological Inspiration for Pruning
人工神经网络中的剪枝被认为是人脑中突触剪枝(Synaptic Pruning)的一个想法,在人脑中,轴突(axon)和树突(dendrite)完全腐烂和死亡,导致突触消除,这发生在许多哺乳动物的幼儿期和青春期开始之间。剪枝从出生时开始,一直持续到25岁左右。
Pruning Deep Neural Networks
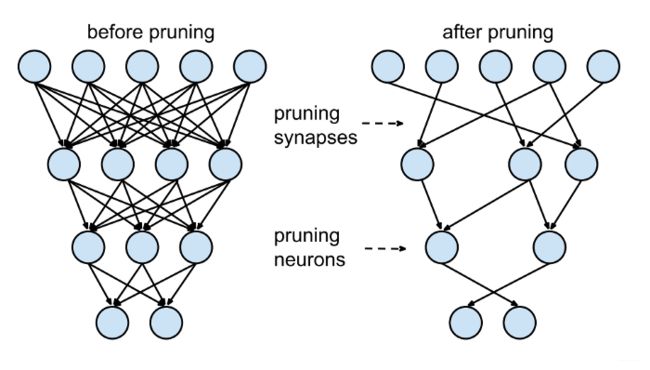
网络通常看起来像左边的网络:下面一层的每个神经元都与上面一层有联系,但这意味着我们必须将许多浮点数相乘。理想情况下,我们只需要将每个神经元连接到其他几个神经元上,并节省一些乘法运算;这称为“稀疏(sparse)”网络。
稀疏模型更容易压缩,我们可以在推理过程中跳过零来改善延迟。
如果可以根据神经元的贡献程度对网络中的神经元进行排名,那么可以从网络中移除排名较低的神经元,从而形成一个更小、更快的网络。
得到更快/更小的深度学习网络,对于在移动设备上运行来说非常重要。
例如,可以根据神经元权重的L1/L2范数来进行排序。剪枝后,准确率会下降(如果排名结果准确的话,下降不会太多),网络通常是训练-剪枝-训练-剪枝(trained-pruned-trained-pruned)迭代恢复的。如果我们一次剪枝太多,网络可能会被破坏得无法恢复。所以在实践中,这是一个迭代过程——通常被称为迭代剪枝(iterative pruning):剪枝/训练/重复。 可参考Tensorflow团队的这段代码,了解迭代剪枝。
Weight pruning
- 将权重矩阵中的各个权重设置为零。这相当于删除上图中的连接。
- 这里,为了实现k%的稀疏性,我们根据权重矩阵W中的各个权重的大小对它们进行排序,然后将最小的k%设置为零。
f = h5py.File("model_weights.h5",'r+')
for k in [.25, .50, .60, .70, .80, .90, .95, .97, .99]:
ranks = {}
for l in list(f['model_weights'])[:-1]:
data = f['model_weights'][l][l][‘kernel:0’]
w = np.array(data)
ranks[l] = (rankdata(np.abs(w), method='dense')-1).astype(int).reshape(w.shape)
lower_bound_rank = np.ceil(np.max(ranks[l])*k).astype(int)
ranks[l][ranks[l] <= lower_bound_rank] = 0
ranks[l][ranks[l] > lower_bound_rank] = 1
w = w * ranks[l]
data[…] = w
Unit/Neuron pruning
- 将权重矩阵中的整个列设置为零,将其设置为零,实际上是删除相应的输出神经元。
- 为了获得k%的稀疏性,我们根据权重矩阵的L2范数对列进行排序,并删除最小的k%。
f = h5py.File("model_weights.h5",'r+')
for k in [.25, .50, .60, .70, .80, .90, .95, .97, .99]:
ranks = {}
for l in list(f['model_weights'])[:-1]:
data = f['model_weights'][l][l]['kernel:0']
w = np.array(data)
norm = LA.norm(w,axis=0)
norm = np.tile(norm,(w.shape[0],1))
ranks[l] = (rankdata(norm,method='dense')-1).astype(int).reshape(norm.shape)
lower_bound_rank = np.ceil(np.max(ranks[l]) * k).astype(int)
ranks[l][ranks[l] <= lower_bound_rank] = 0
ranks[l][ranks[l] > lower_bound_rank] = 1
w = w * ranks[l]
data[…] = w
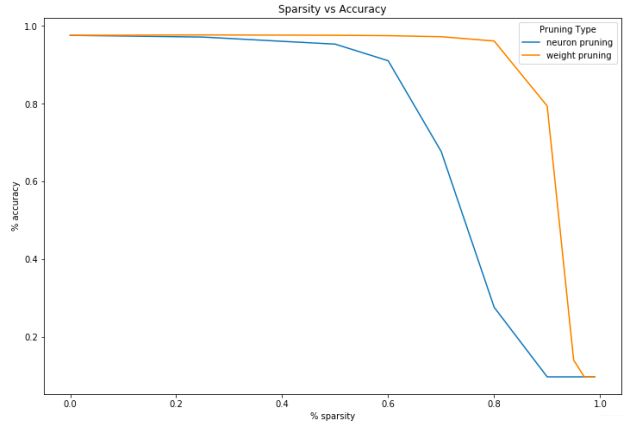
随着增加稀疏性并删除更多网络,任务性能将逐渐降低。预计稀疏性与性能的下降曲线如何?
使用以下简单神经网络架构对MNIST数据集上的图像分类模型进行剪枝:


Key Takeaways
许多研究人员认为剪枝是一种被忽视的方法,将会得到更多的关注并在实践中使用。我们展示了如何使用非常简单的神经网络架构在玩具数据集上获得良好的结果。我认为深度学习在实践中用来解决的许多问题都类似于这个问题,在有限的数据集上使用迁移学习,因此它们也可以从剪枝中受益。
References
- Code for this blog post
- To prune, or not to prune: exploring the efficacy of pruning for model compression, Michael H. Zhu, Suyog Gupta, 2017
- Learning to Prune Filters in Convolutional Neural Networks, Qiangui Huang et. al, 2018
- Pruning deep neural networks to make them fast and small
- Optimize machine learning models with Tensorflow Model Optimization Toolkit