Hive支持的计算引擎
目前Hive支持MapReduce、Tez和Spark 3种计算引擎。
MapReduce计算引擎
在Hive 2.0之后不推荐MR作为计算引擎。
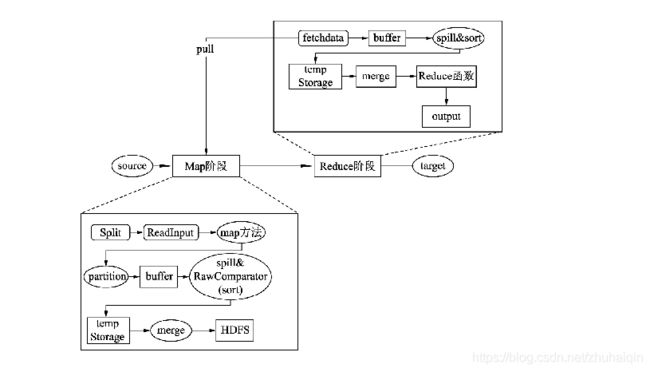
Map和Reduce的工作流程
MR运行的完整过程:
Map在读取数据时,先将数据拆分成若干数据,并读取到Map方法中被处理。数据在输出的时候,被分成若干分区并写入内存缓存(buffer)中,内存缓存被数据填充到一定程度会溢出到磁盘并排序,当Map执行完后会将一个机器上输出的临时文件进行归并存入到HDFS中。
当Reduce启动时,会启动一个线程去读取Map输出的数据,并写入到启动Reduce机器的内存中,在数据溢出到磁盘时会对数据进行再次排序。当读取数据完成后会将临时文件进行合并,作为Reduce函数的数据源。
Tez计算引擎
Apache Tez是进行大规模数据处理且支持DAG作业的计算框架,它直接源于MapReduce框架,除了能够支持MapReduce特性,还支持新的作业形式,并允许不同类型的作业能够在一个集群中运行。
Tez将原有的Map和Reduce两个操作简化为一个概念——Vertex,并将原有的计算处理节点拆分成多个组成部分:Vertex Input、Vertex Output、Sorting、Shuffling和Merging。计算节点之间的数据通信被统称为Edge,这些分解后的元操作可以任意灵活组合,产生新的操作,这些操作经过一些控制程序组装后,可形成一个大的DAG作业。
通过允许Apache Hive运行复杂的DAG任务,Tez可以用来处理数据,之前需要多个MR jobs,现在一个Tez任务中。

Tez和MapReduce作业的比较
Tez绕过了MapReduce很多不必要的中间的数据存储和读取的过程,直接在一个作业中表达了MapReduce需要多个作业共同协作才能完成的事情。
Tez和MapReduce一样都运行使用YARN作为资源调度和管理。但与MapReduce on YARN不同,Tez on YARN并不是将作业提交到ResourceManager,而是提交到AMPoolServer的服务上,AMPoolServer存放着若干已经预先启动ApplicationMaster的服务。
当用户提交一个作业上来后,AMPoolServer从中选择一个ApplicationMaster用于管理用户提交上来的作业,这样既可以节省ResourceManager创建ApplicationMaster的时间,而又能够重用每个ApplicationMaster的资源,节省了资源释放和创建时间。
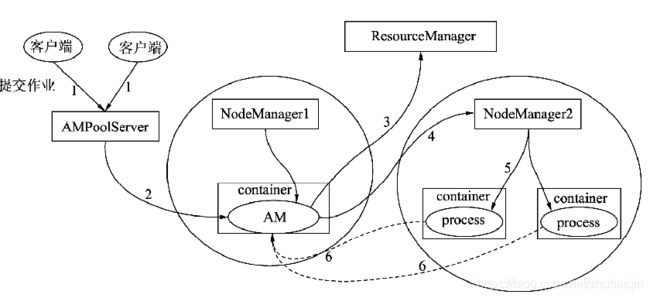
Tez作业的提交
Tez相比于MapReduce有几点重大改进:
当查询需要有多个reduce逻辑时,Hive的MapReduce引擎会将计划分解,每个Redcue提交一个MR作业。这个链中的所有MR作业都需要逐个调度,每个作业都必须从HDFS中重新读取上一个作业的输出并重新洗牌。而在Tez中,几个reduce接收器可以直接连接,数据可以流水线传输,而不需要临时HDFS文件,这种模式称为MRR(Map-reduce-reduce*)。
Tez还允许一次发送整个查询计划,实现应用程序动态规划,从而使框架能够更智能地分配资源,并通过各个阶段流水线传输数据。对于更复杂的查询来说,这是一个巨大的改进,因为它消除了IO/sync障碍和各个阶段之间的调度开销。
在MapReduce计算引擎中,无论数据大小,在洗牌阶段都以相同的方式执行,将数据序列化到磁盘,再由下游的程序去拉取,并反序列化。Tez可以允许小数据集完全在内存中处理,而MapReduce中没有这样的优化。仓库查询经常需要在处理完大量的数据后对小型数据集进行排序或聚合,Tez的优化也能极大地提升效率。
Spark计算引擎
Apache Spark是专为大规模数据处理而设计的快速、通用支持DAG(有向无环图)作业的计算引擎,类似于Hadoop MapReduce的通用并行框架,可用来构建大型的、低延迟的数据分析应用程序。
Spark具有以下几个特性。
1.高效性
Spark会将作业构成一个DAG,优化了大型作业一些重复且浪费资源的操作,对查询进行了优化,重新编写了物理执行引擎,如可以实现MRR模式。2.易用性
Spark不同于MapReducer只提供两种简单的编程接口,它提供了多种编程接口去操作数据,这些操作接口如果使用MapReduce去实现,需要更多的代码。Spark的操作接口可以分为两类:transformation(转换)和action(执行)。Transformation包含map、flatmap、distinct、reduceByKey和join等转换操作;Action包含reduce、collect、count和first等操作。
3.通用性
Spark针对实时计算、批处理、交互式查询,提供了统一的解决方案。但在批处理方面相比于MapReduce处理同样的数据,Spark所要求的硬件设施更高,MapReduce在相同的设备下所能处理的数据量会比Spark多。所以在实际工作中,Spark在批处理方面只能算是MapReduce的一种补充。
4.兼容性
Spark和MapReduce一样有丰富的产品生态做支撑。例如Spark可以使用YARN作为资源管理器,Spark也可以处理Hbase和HDFS上的数据。
扩展:Spark On YARN提供了两种提交作业的模式:YARN Client和YARN Cluster。两个模式在运行计算节点,完成数据从读入、处理、输出的过程基本一样。不同的是,YARN Client作业的监控管理放在提交作业所在的节点,YARN Cluster则是交给YARN去决定,YARN会根据集群各个节点资源的使用情况,选择最为合适的节点来存放作业监控和管理进程。YARN Client一般用于测试,YARN Cluster用于实际生产环境。