【从零入门人工智能】异常检测实战_数据集:anomaly_data.csv
异常检测实战
-
- 实验目标
- 导入第三方库
- 导入数据集
- 取出数据集中的每一列数据
- 数据可视化
- 可视化数据的分布情况
- 计算均值和方差
- 画出 `x1` 和 `x2` 的高斯分布图形
- 建立异常检测模型并进行预测
- 默认参数情况下对模型预测结果进行可视化
- 修改默认参数后,对模型预测结果进行可视化
- 总结
实验目标
- 基于
anomaly_data.csv数据,可视化数据分布情况、及其对应高斯分布的概率密度函数 - 建立模型,实现异常数据点预测
- 可视化异常检测处理结果
- 修改概率分布阈值
EllipticEnvelope(contamination=0.1)中的contamination,查看阈值改变对结果的影响
数据集:百度云盘链接,提取码:qp2n
导入第三方库
# 导入第三方包
import numpy as np
import pandas as pd
from scipy.stats import norm
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score
from sklearn.covariance import EllipticEnvelope
导入数据集
data = pd.read_csv("./dataset/anomaly_data.csv")
data.head()

取出数据集中的每一列数据
取出每一列的数据,方便后面的数据可视化
# 取出每一列的数据
x1 = data.loc[:,"x1"]
x2 = data.loc[:,"x2"]
print(x1.shape,x2.shape)

从运行结果中可以知道,数据集中一共含有 307 条数据
数据可视化
# 数据可视化
fig1 = plt.figure()
plt.scatter(x1,x2)
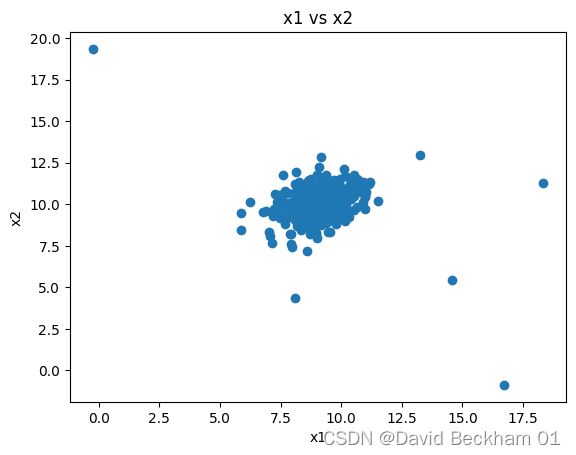
plt.title("x1 vs x2")
plt.xlabel("x1")
plt.ylabel("x2")
plt.show()
可视化数据的分布情况
# 显示数据分布情况
fig2 = plt.figure(figsize=(20,5))
plt.subplot(121)
plt.hist(x1, bins=100)
plt.title("x1 distribution")
plt.xlabel("x1")
plt.ylabel("counts")
plt.subplot(122)
plt.hist(x2, bins=100)
plt.title("x2 distribution")
plt.xlabel("x2")
plt.ylabel("counts")
plt.show()
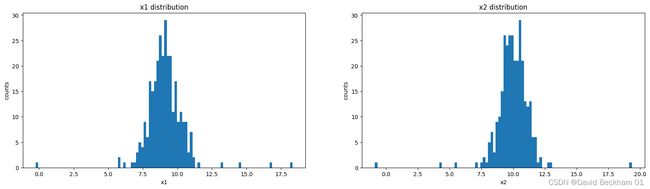
通过可视化的结果,我们可以直观的看到 x1 和 x2 的数据分布情况,其中 x1 的大部分数据都集中在7.5~11.5 这个区间之中,x2 的大部分数据都集中在8.5~11.5 这个区间之中
计算均值和方差
计算均值和方差,方便后续画出 x1 和 x2 的高斯分布
# 计算均值和标准差
x1_mean = x1.mean()
x1_sigma = x1.std()
x2_mean = x2.mean()
x2_sigma = x2.std()
print(x1_mean, x1_sigma)
print(x2_mean, x2_sigma)

画出 x1 和 x2 的高斯分布图形
# 计算高斯分布的 p(x)
fig3 = plt.figure(figsize=(20,5))
plt.subplot(121)
x1_range = np.linspace(0,20,1000)
x1_normal = norm.pdf(x1_range, x1_mean, x1_sigma)
plt.plot(x1_range, x1_normal)
plt.title("normal p(x1)")
plt.xlabel("x1")
plt.ylabel("counts")
plt.subplot(122)
x2_range = np.linspace(0,20,1000)
x2_normal = norm.pdf(x2_range, x2_mean, x2_sigma)
plt.plot(x2_range, x2_normal)
plt.title("normal p(x2)")
plt.xlabel("x2")
plt.ylabel("counts")
plt.show()
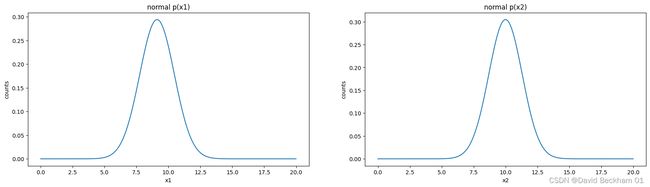
建立异常检测模型并进行预测
# 建立模型并进行预测
from sklearn.covariance import EllipticEnvelope
ad_model = EllipticEnvelope()
ad_model.fit(data)
y_predict = ad_model.predict(data)
print(pd.value_counts(y_predict))

sklearn.covariance.EllipticEnvelope 的具体参数解释参考:官方文档
contamination 表示的是异常值所占的比例,默认为 0.1,表示异常值占总体数据的 10%
运行结果中y_predict 中取值为 1 的表示正常值,取值为 -1 表示模型预测出的异常值
默认参数情况下对模型预测结果进行可视化
# 可视化预测结果
fig4 = plt.figure(figsize=(20,10))
orginal_data = plt.scatter(x1, x2, marker="x")
anomaly_data = plt.scatter(x1[y_predict == -1], x2[y_predict == -1], marker="o", facecolor="none", edgecolors="red", s=150)
plt.title("anomaly datection result")
plt.xlabel("x1")
plt.ylabel("x2")
plt.legend((orginal_data, anomaly_data),('orginal_data', 'anomaly_data'))
plt.show()
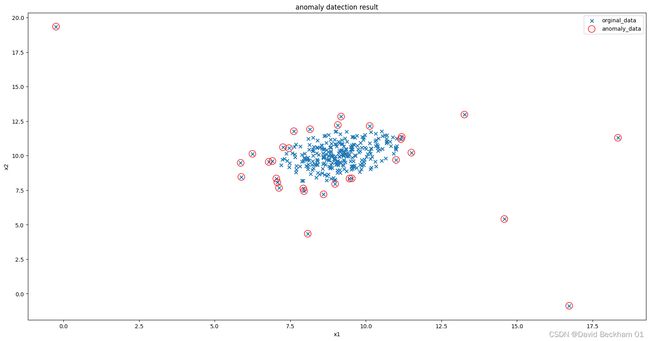
matplotlib.pyplot.scatter 的具体参数可以参考:官方文档
图中红色圈圈表示选中的异常值。从可视化的结果中我们可以看出,模型的预测结果还不够准确,将一些正确的值也标记成了异常值,所以我们需要修改默认的参数是的预测的结果更加准确。
修改默认参数后,对模型预测结果进行可视化
# 修改阈值 contamination, 阈值表示异常点的比例
ad_model = EllipticEnvelope(contamination=0.03)
ad_model.fit(data)
y_predict = ad_model.predict(data)
# print(pd.value_counts(y_predict))
# 可视化预测结果
fig5 = plt.figure(figsize=(20,10))
orginal_data = plt.scatter(x1, x2, marker="x")
anomaly_data = plt.scatter(x1[y_predict == -1], x2[y_predict == -1], marker="o", facecolor="none", edgecolors="red", s=150)
plt.title("anomaly datection result")
plt.xlabel("x1")
plt.ylabel("x2")
plt.legend((orginal_data, anomaly_data),('orginal_data', 'anomaly_data'))
plt.show()
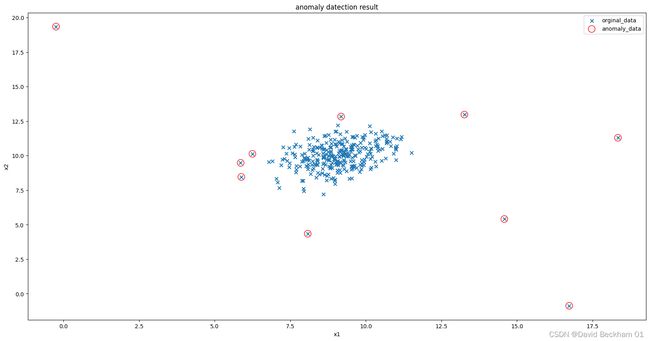
从可视化的结果中我们可以看出,模型的预测准确性已经有了不小的提升,所有异常值都被标记了出来。
总结
- 本次实验,通过计算数据各维度对应的高斯分布概率密度函数,可用于寻找到数据中的异常点;
- 通过修改概率密度阈值contamination,可调整异常点检测的灵敏度;
- 异常值的检测在实际的生活中应用的比较广泛,例如一些传感器的数据检测,如果传感器的数据出现了异常,我们需要及时的对异常进行排除,对损坏的传感器进行更换,否则会导致检测结果的准确性下降。
- 核心算法参考链接: sklearn.covariance.EllipticEnvelop