神经网络学习笔记9——循环神经网络中的LSTM模型和GRU模型
系列文章目录
LSTM视频参考
GRU视频参考
文章目录
- 系列文章目录
- 前言
- 一、LSTM模型结构
- 二、GRU模型结构
- 三、GRU与LSTM的比较
前言
循环神经网络(Recurrent Neural Network,RNN)是一种用于处理序列数据的神经网络。相比一般的神经网络来说,他能够处理序列变化的数据。比如某个单词的意思会因为上文提到的内容不同而有不同的含义,RNN就能够很好地解决这类问题。
LSTM是RNN的一种,可以解决RNN长序列训练过程中的梯度消失和梯度爆炸问题,当一条序列足够长,那RNN将很难将信息从较早的时间步传送到后面的时间步,而LSTM能学习长期依赖的信息,记住较早时间步的信息,因此可以做到联系上下文。
不同与RNN,RNN是想要记住所有的信息,不在乎不关注信息是否有用是否重要,而LSTM则设计了一个记忆细胞,起到筛选功能,具备选择记忆的功能,用于选择记忆重要的信息,过滤噪音与非重要信息以减轻记忆负担。它的出现解决了梯度失真的问题。而且使得RNN的收敛速度比普通的RNN要快上不少。
LSTM 的核心概念在于细胞状态以及“门”结构。细胞状态相当于信息传输的路径,让信息能在序列连中传递下去。你可以将其看作网络的“记忆”。理论上讲,细胞状态能够将序列处理过程中的相关信息一直传递下去。
GRU(Gate Recurrent Unit)是循环神经网络(RNN)的一种,可以解决RNN中不能长期记忆和反向传播中的梯度等问题,与LSTM的作用类似,不过比LSTM简单,容易进行训练。它与 LSTM 非常相似,与 LSTM 相比GRU 去除掉了细胞状态,使用隐藏状态来进行信息的传递。它只包含两个门:更新门和重置门。
GRU是LSTM的一个变种,也是为了解决长期记忆和反向传播中的梯度等问题而提出来的。GRU和LSTM在很多情况下实际表现上相差无几,但是GRU计算更简单,更易于实现。
一、LSTM模型结构
RNN结构
LSTM结构
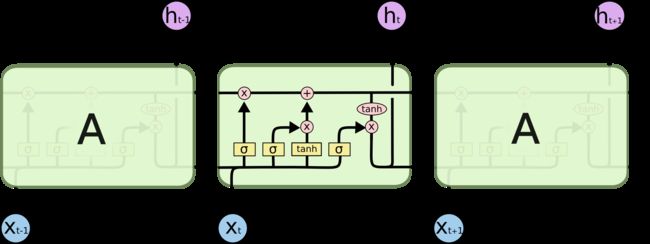
LSTM模型与RNN模型进行对比:
- X t X_t Xt位置的模型结构复杂程度差别比较大
- LSTM有两个输出,RNN只有一个输出

把 X t X_t Xt单独拎出来,其中
C C C表示记忆细胞,公式是Cell State
h h h表示状态
X X X表示新内容
σ σ σ表示门单元
f t f_t ft遗忘门,公式是Forget Gate
i t i_t it输入门,公式是Input Gate
o t o_t ot输出门,公式是Output Gate
对比 f t f_t ft, i t i_t it, o t o_t ot的公式可以发现它们的规律都是 σ ( W × X t + W × h t − 1 + b ) σ(W×X_t+W×{h_{t-1}}+b) σ(W×Xt+W×ht−1+b)类型。根据上面的模型结构图可以发现 ( X t , h t − 1 ) (X_t,h{_t-1}) (Xt,ht−1)都会输入到σ门里,所以三个门的X和h值都是一样的。通过 ( X t , h t − 1 ) (X_t,h{_t-1}) (Xt,ht−1)可以计算得到四个值 f t f_t ft, i t i_t it, C ~ \widetilde{C} C 和 o t o_t ot。其中 t a n h tanh tanh是激活函数其输出向量的每个元素均在-1~1之间, W , b W,b W,b是各个门神经元的参数,是要在训练过程中学习得到的。
- 遗忘门:决定应丢弃或保留哪些信息。来自前一个隐藏状态的信息和当前输入的信息同时传递到 sigmoid 函数中去,输出值介于 0 和 1 之间,越接近 0 意味着越应该丢弃,越接近 1 意味着越应该保留。将得到的 f t f_t ft与输入的 C t − 1 C_{t-1} Ct−1相乘,也就是向量乘法。
- 输入门:输入门用于更新细胞状态。首先将前一层隐藏状态的信息和当前输入的信息传递到 sigmoid 函数中去。将值调整到 0~1 之间来决定要更新哪些信息。0 表示不重要,1 表示重要,得到 i t i_t it值。其次还要将前一层隐藏状态的信息和当前输入的信息传递到 tanh 函数中去,创造一个新的侯选值向量,得到 C ~ \widetilde{C} C 值。最后将 sigmoid 的输出值与 tanh 的输出值 i t i_t it和 C ~ \widetilde{C} C 相乘,也就是向量乘法,其中sigmoid 的输出值将决定 tanh 的输出值中哪些信息是重要且需要保留下来的。而需要保留的信息将会与遗忘门得到的输出进行相加,最终得到新的记忆细胞 C t = ( f t ⨀ C t − 1 ) + ( i t ⨀ C ~ ) {C_t} = ({f_t}⨀{C_{t-1}})+({i_t}⨀{\widetilde{C}}) Ct=(ft⨀Ct−1)+(it⨀C )
- 输出门:输出门用来确定下一个隐藏状态的值,隐藏状态包含了先前输入的信息。首先,我们将前一个隐藏状态和当前输入传递到 sigmoid 函数中,然后将新得到的细胞状态传递给 tanh 函数。最后将 tanh 的输出与 sigmoid 的输出相乘,也就是向量乘法,以确定隐藏状态应携带的信息。再将隐藏状态作为当前细胞的输出,把新的细胞状态和新的隐藏状态 h t h_t ht传递到下一个时间步长中去。也就是将新得到的记忆细胞 C t {C_t} Ct传入tanh进行权重计算 m t = t a n h ( C t ) {m_t} = tanh({C_t}) mt=tanh(Ct),再将 o t o_t ot根据权重 m t {m_t} mt计算新的隐藏状态 h t = o t ⨀ m t {h_t} = {o_t}⨀{m_t} ht=ot⨀mt,从而达到控制哪部分需要输出,哪部分是我们所需要的答案。
二、GRU模型结构
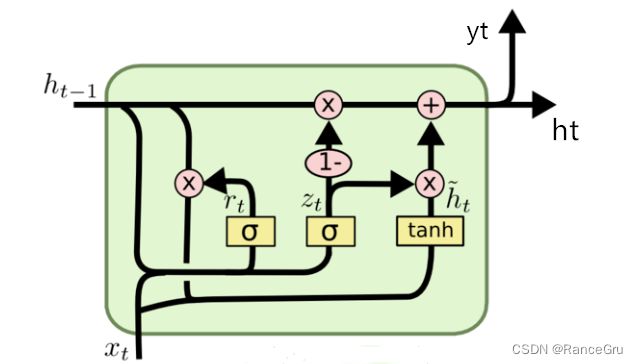
公式表达:
z t = σ ( W x z × X t + W h z × h t − 1 + b z ) z_t = σ(W_{xz}×X_t+W_{hz}×{h_{t-1}}+b_z) zt=σ(Wxz×Xt+Whz×ht−1+bz)
r t = σ ( W x r × X t + W h r × h t − 1 + b r ) r_t = σ(W_{xr}×X_t+W_{hr}×{h_{t-1}}+b_r) rt=σ(Wxr×Xt+Whr×ht−1+br)
h ~ t = t a n h ( W x h × X t + W h h × ( r t ⨀ h t − 1 ) + b h ) \widetilde{h}_t = tanh(W_{xh}×X_t+W_{hh}×(r_t⨀{h_{t-1}})+b_h) h t=tanh(Wxh×Xt+Whh×(rt⨀ht−1)+bh)
h t = ( 1 − z t ) ⨀ h t − 1 + z t ⨀ h ~ t h_t = (1-z_t)⨀h_{t-1}+z_t⨀\widetilde{h}_t ht=(1−zt)⨀ht−1+zt⨀h t
GRU只有两个门,将LSTM中的输入门和遗忘门合二为一的称为更新门(update gate)公式为 z t z_t zt,而另一个称为重置门(reset gate)公式为 r t r_t rt。
可以观察到两个门的公式也都是 σ ( W × X t + W × h t − 1 + b ) σ(W×X_t+W×{h_{t-1}}+b) σ(W×Xt+W×ht−1+b)类型,但是这里的 h ~ t \widetilde{h}_t h t和LSTM的 C ~ \widetilde{C} C 不同,LSTM的 C ~ \widetilde{C} C 是由 h t − 1 , X t h_{t-1},X_t ht−1,Xt组成的,而GRU的 h ~ t \widetilde{h}_t h t是由 ( r t ⨀ h t − 1 ) , X t (r_t⨀h_{t-1}),X_t (rt⨀ht−1),Xt组成的。其中 t a n h tanh tanh是激活函数其输出向量的每个元素均在-1~1之间, W , b W,b W,b是各个门神经元的参数,是要在训练过程中学习得到的。
- 更新门 z t z_t zt:起到关注作用的机制,用于控制前一时刻的状态信息被带入到当前状态中的程度,也就是更新门帮助模型决定到底要将多少过去的信息传递到未来,简单来说就是用于更新记忆。
- 重置门 r t r_t rt:起到遗忘作用的机制,决定了如何将新的输入信息与前面的记忆相结合 ,控制要遗忘多少过去的信息,令隐藏状态遗忘任何在未来发现与预测不相关的信息,同时也允许构建更加紧致的表征。
三、GRU与LSTM的比较
优点:
- GRU相比于LSTM少了输出门,其参数比LSTM少,计算量要比LSTM少,更简单,容易实现,可以更快速的训练模型;
- GRU只有两个门,LSTM有三个门,GRU更容易控制参数,更容易调整;
缺点:
- GRU没有LSTM那么强大的记忆能力,对于长时间依赖的问题, LSTM比GRU严格来说更强,因为它可以很容易地进行无限计数,而GRU却不能。这就是GRU不能学习简单语言的原因,而这些语言是LSTM可以学习的;
- GRU没有LSTM那么多的参数,容易出现欠拟合的情况。