基于深度学习的恶意 URL 识别
基于深度学习的恶意 URL 识别
原文作者:陈康, 付华峥, 向勇
原文期刊:计算机系统应用,2018,27(6):27–33
原文链接:http://www.c-s-a.org.cn/1003-3254/6370.html
一、论文主要内容
在本文工作中,我们提出一种基于深度学习的恶意 URL 识别模型。本文的模型基于 URL 词法特征进行检测。首先通过正常 URL 样本训练得到 URL 中的字符的分布表示。将 URL 转化成二维图像,然后通过训练 CNN 模型对二维图像进行特征抽取,最后使用全连接层进行分类。
二、作者工作
2.1 相关工作
目前的恶意 URL 识别工作使用的主要是黑名单、启发式技术和机器学习技术。黑名单技术只能给与用户最低程度的保护,并不能及时检测出恶意网站,阻断用户对恶意网站的访问。启发式算法是对黑名单技术的一种补充算法,其主要原理是利用从恶意网址中发现的黑名单相似性规则来发现并识别恶意网页。但是启发式算法有误报率高以及规则更新难等缺点。
机器学习算法通过分析网页 URL 以及网页信息,提取域名的重要特征表示,并训练出一个预测模型。有监督算法也叫分类算法,此算法的准确率较高而且误报率相对较低,但是却对标注数据以及特征工程比较敏感,标注数据的准确率以及选择使用的特征会严重影响算法的准确率和效率。无监督机器学习方法又称聚类方法。此类方法的具体分类过程主要由特征提取、聚类、簇标记和网页判别等步骤组成。主要做法是首先将 URL 数据集划分为若干簇,使得同一簇的数据对象之间相似度较高,而不同簇的数据对象之间的相似度较低。然后,通过构造和标记数据集中的簇来区分恶意网页和良性网页。
深度学习通过学习深层非线性网络结构,逐层训练特征,将样本在原空间的特征表示逐步变换到新特征空间,最大好处是可以自动学习特征和抽象特征。
2.2 模型设计
设计思想
根据 Anh 等人,正常和恶意 URL 具有不同的词法特征,即字符出现的频率、位置、和前后字符的关系具有可以区分的特征,我们提出一种完全基于 URL 字符串的词法特征,利用深度神经网络实现的恶意 URL 识别算法。
具体实现
算法分为 3 个阶段:
首先,训练构成 URL 的字符表示为实数向量的形式;
其次,基于第一步得到的映射表,将 URL 转换成特征图像;
最后,将特征图像输入卷积神经网络 CNN 去学习特征,通过一个全连接层实现对 URL 的分类。
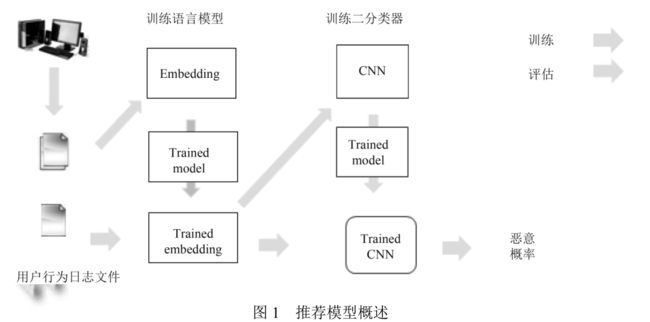
本算法共有两个部分:训练部分和预测部分。
训练流程:
- 系统监控用户浏览行为过程并生成日志;
- 使用深度学习对日志文件进行训练得到字符的嵌入式模型;
- 利用上一步得到的模型对网页URL进行特征转化;
- 使用CNN算法训练已标注的恶意/良性URL特征。
预测/评估过程:
- 使用字符的嵌入式表示对日志行为数据进行特征转化;
- 使用训练后的CNN模型进行词法特征提取;
- 再使用分类输出层进行恶意概率计算。
使用语料训练 RNN 生成字符的嵌入式表示
主要工作是将字符映射到 K 维向量空间,将其转为连续值的向量表示。
-
首先从 0 开始对 URL 中出现的所有字符进行编码。设定一个词汇表大小 v,将所有出现的字符按出现的频率从 1 到 v–2 进行编码。0 作为填充字符的编码,v–1 作为未知 (未出现在字符表中) 字符的编码 1;
-
训练一个两层的神经网络模型。构建一个[v,k]的二维向量,将正常的 URL 作为训练样本输入。例如 www.baidu.com,转换为训练序列 (w, w), (w, w), (w,w), …, (a, b), (a, i), …, (m, o),然后计算输出预测和它实际值的损失函数,训练过程中更新二维向量的值;
-
训练结束后,得到维度为[v, k]的映射表。
将 URL 转化为特征图像
确定一个 URL 最大长度 n,构建一个[n, k]大小的图像。如果 URL 长度小于 n 的,使用 0 作为填充,对于长度大于 n 的 URL 做截断。转换后图像的每一行即是 URL 中的一个字符的向量表示。如图 3 所示。
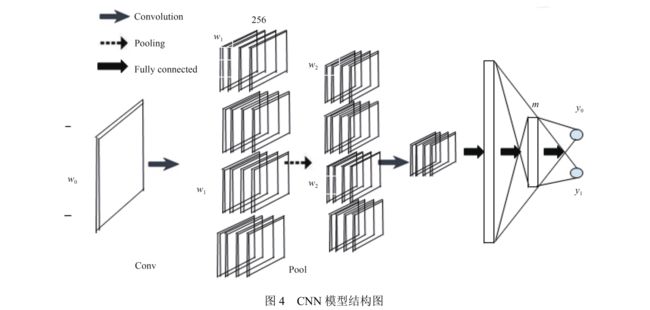
CNN 提取特征并进行分类
构建一个 CNN 分类模型,将上述得到的特征图像作为输入,通过卷积层对进行特征提取,最后通过一个全连接层进行分类,得到输出变量-即分类结果。CNN 模型如图 4 所示。
三、实验
3.1 实验数据
本次研究筛选出某个月的用户浏览记录前 50 000 的 url 作为正常的 URL;同时采用爬虫从网站 https://www.malwaredomainlist.com/mdl.php、http://www.phishtank.com/等网站中收集了 3 万多条URL 数据作为恶意网站数据。
3.2 实验结果
本次实验使用一台服务器进行, 安装了 python3.6.2,TensorFlow1.2.0, sklearn 等。服务器操作系统是 Centos 7.2 版本,内存为 512 G,核数为 40。
本研究采用十折交叉验证对 80 000 多个 URL 进行分类验证。图 5 和图 6 为算法精度和损失函数曲线
和 ROC 曲线图。
在我们的实验数据集上,模型的准确率为 0.962、召回率为 0.879、F1 值为 0.918,模型整体达到了很好的预测效果。
在本次试验数据的过程中,目前测试的样本集下,全连接层的个数会严重影响模型结果。如果在算法的最后再增加一层全连接层,模型效果精度将会降低 50% 左右,因此对类似数据量的模型训练来说,全连接层的个数至关重要。
我们使用 grid search 进行参数选择,发现卷积核分别设置为 128 和 256,批处理数量分别设置为 128 或者 256,学习率设置为 0.001 时,算法较好。
四、总结
本文提出了一种基于URL字符串转化为二维图片,利用CNN进行分类的深度学习方法。是一种学习了URL词法特征的方法,但处理的URL需要限制长度,然而攻击者常常使用很长的URL来试图掩盖可以部分。而且只考虑了单个字符出现的频率,没有考虑字符出现的位置、和前后字符的关系,或许会出现一些偏差。