Lesson 16.16&16.17 残差网络:思想与具体框架&ResNet的复现(1):架构中的陷阱_batch&卷积块、残差块、瓶颈架构_batc&完整的残差网络
自从2012年AlexNet登场之后,卷积网络在ILSVRC上的错误率就逐年下降,在Inception和GoogLeNet诞生之后,CNN在ImageNet数据集上能够达到的水平已经非常接近人类识别的表现(约5%)。然而,即便算法已经基本达到人类水平,有两个瓶颈一直没有被突破:第一,网络能够达到的最大深度依然很浅,VGG是19层,GoogLeNet也没有超过25层,从理论上来说,CNN应该还有巨大的潜力。第二,深度网络的训练难度太大,虽然强行堆叠卷积层或inception让网络加深非常容易,但加深后的网络往往收敛困难,损失很高,精度很低。在2012年之后,众多研究都在“帮助深度神经网络收敛”这一部分取得了巨大的成效——学者们对神经网络的各个训练流程都做出了改变,现在我们可以通过参数初始化、学习率调度、Batch Normalization、动量法、随机梯度下降等手段来帮助神经网络更好地收敛。然而,让深度网络取得更好的精度这一方面却进展缓慢。
根据理论,深度网络可以令权重空间上的损失函数图像变得更加平滑,因此经过适当的训练,应该更容易找到好的局部最小值,达成更高的精度。但在实际应用中,深层网络的精度往往更容易达到“饱和”状态(saturated)。在20层以下时,深度越深网络的学习能力越强,精度越高,但当网络的深度超过20层后,随着深度的增加,网络的精度不仅没有持续升高,反而趋近于平缓,甚至出现下降的趋势。网络深度加深,精度却在降低,这种现象在深度网络的训练中被称为“退化”(degradation),退化现象的存在导致深度网络在实际任务上的表现常常会不如浅层网络。可见,训练一个很深的神经网络比创造一个很深的神经网络架构难得多,GoogLeNet和VGG都没有无限加深网络,也是因为在实验中,更深的网络无法被训练出有效的结果。如果不能突破深度网络的训练瓶颈,CNN的性能就无法进一步提升,VGG保持特征图不变的重复架构、以及GoogLeNet用密集去近似稀疏的并联架构都只能算是“曲线救国”,虽然解决了很多问题、也取得了了不起的成果,但还是没有解决根本的训练问题。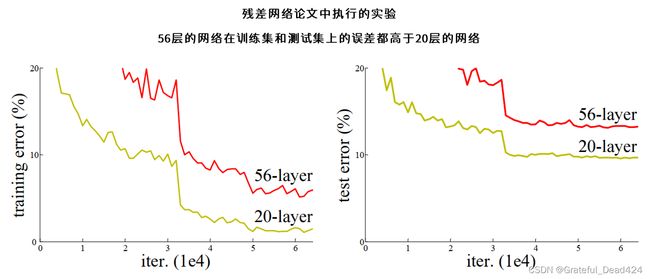
为什么深度网络在现有训练流程下会退化呢?一种广泛的猜测是,随着网络加深,网络的学习能力逐渐增强,从而引起了过拟合,导致测试集上的误差上升。但这个观点很快就被否认了。如果深层网络的问题是过拟合,那深层网络应该只在测试集上表现糟糕,并且在训练集上表现出非凡的精度,但事实上,从上图的实验结果来看,深度网络的训练误差和测试误差都高于浅层网络,其训练集和测试集的精度表现都很糟糕。这说明深度网络的损失更高、精度更低并不是过拟合造成的。更合理的推测是,深层网络中的函数关系本质上就比浅层网络中的函数关系更复杂、更难拟合(fit),因此深层网络本质上就比浅层网络更难优化和训练。
这其实不难理解。对于任意的卷积架构而言,假设其输入值是 x x x,标签 y y y与输入值之间客观存在的函数关系是 y = H ( x ) y=H(x) y=H(x)。输入数据后,卷积网络的职责就是拟合出 H ( x ) H(x) H(x)这个映射关系,拟合程度越高,卷积网络的精度就越高。“训练”,或者“优化”,本质就是帮助卷积网络实现关系拟合的手段,因此,如果需要拟合的关系 H ( x ) H(x) H(x)越复杂,训练或优化的难度就会越高。在神经网络中,深度越深,输入值 x x x所在的权重空间的维度就会越高,其对应的函数关系也会越复杂。在数学上,高维函数关系的拟合本来也不是一个容易的课题。根据实验的结果来看,当权重空间的维度升高到一定程度之后,现有的训练流程就不能恰当地找到这个高维空间中较为理想的局部最小值了,因此很难恰当地拟合出 H ( x ) H(x) H(x)。难以拟合、难以训练、难以优化,这让深度神经网络的精度一直非常尴尬。
如果我们希望在不削弱精度的情况下加深网络,可以怎么做呢?假设现在有一个准确率很高的浅层网络 N N N,它大约有20层,经过训练后它得到的输出结果是 σ \sigma σ。由于它准确率很高, σ \sigma σ和真实标签的值非常接近。对于网络 N N N,一种简单粗暴地加深它的方式就是在它的后面添加众多只包含恒等函数(Identity function)的层。恒等函数是输入值和输出值完全一致的函数,可表示为 f ( σ ) = σ f(\sigma)=\sigma f(σ)=σ,这个函数本身不具备任何的学习能力。我们将添加了恒等函数的网络称为深层网络 N ′ N^{\prime} N′,它大约有60层,它的输出应该与浅层网络 N N N一模一样,则它在训练集、测试集上的精度表现应该也与浅层网络 N N N一模一样。如此,我们就实现了在不削弱准确率的情况下加深网络的深度。
直觉上来说,倘若我们将 N ′ N^{\prime} N′中的恒等函数更换为任意具备学习能力的层(任何可以对数据进行线性或非线性转化的层,比如,卷积层)得到网络 N ′ ′ N^{\prime \prime} N′′,那 N ′ ′ N^{\prime \prime} N′′网络整体的学习能力应该是强于网络 N ′ N^{\prime} N′的,且 N ′ ′ N^{\prime \prime} N′′网络得到的结果应该比 σ \sigma σ更接近真实值,或至少和 σ \sigma σ一样接近真实值。然而经过大量实验,研究者们发现 N ′ ′ N^{\prime \prime} N′′总是无法被训练到和 N ′ N^{\prime} N′一样的程度,比起 σ \sigma σ, N ′ ′ N^{\prime \prime} N′′的结果几乎总是离真实值更远(或者, N ′ ′ N^{\prime \prime} N′′需要花巨量的时间,才能够收敛到与 σ \sigma σ相似的结果)。这说明了一个惊人的、与直觉相悖的事实:在现有优化算法、优化思路下,在浅层网络后增加恒等函数很可能就是最优的(optimal)加深网络深度的方式。即便这种方式看起来是无效的操作,但我们确实无法通过实验找出比这种操作效果更好的架构,而从理论上来证明这一点就更加不可能。
从学术的角度来看,在浅层网络后增加恒等函数可以说是一个重要的“灵感”,我们无法证明它的正确性,却可以一定程度上理解这个现象为何会发生——如果增加深度就会因无法训练导致精度下降,那能够让精度不下降的恒等函数可能真的就是最好的选择。2015年,基于这样的实验和结论,微软AI研究中心提出了全新的深度网络架构:残差网络ResNet,其基本思想可以如下概括:假设增加深度用的最优结构就是恒等函数,利用恒等函数的性质,将用于加深网络深度的结构向更容易拟合和训练的方向设计,从根源上降低深度网络的训练难度。
具体怎么操作呢?VGG用来加深网络的结构是重复的卷积层,GoogLeNet用来加深网络的结构是Inception块,而在残差网络中,这个结构块是“残差块”(Residual unit),也可以译作残差单元。在残差网络中,我们将众多残差单元与普通卷积层串联,以实现“在浅层网络后堆叠某种结构、以增加深度”的目的。
无论残差单元拥有怎样的结构,它一定也存在输入值 x x x和必须拟合的关系 H ( x ) H(x) H(x)。假设我们使用 F ( x ) F(x) F(x)来表示输入值 x x x与输出的函数关系 H ( x ) H(x) H(x)之间的差异,则有 F ( x ) = H ( x ) − x F(x)=H(x)-x F(x)=H(x)−x,此时 F ( x ) F(x) F(x)就是残差(Residual)。不难发现,如果恒等函数真的就是最优的增加深度的结构,那在得到适当训练后,残差块本身应该会非常接近于一个恒等函数,因此,其输入值 x x x与 H ( x ) H(x) H(x)之间的客观关系就是 x = H ( x ) x=H(x) x=H(x),残差 F ( x ) F(x) F(x)的取值就会为0。拟合0与 x x x的关系,比拟合一个未知的函数 H ( x ) H(x) H(x)与 x x x的关系要容易太多了,所以残差是一个比原始函数关系更容易优化的数学对象。如果能够让网络拟合 F ( x ) F(x) F(x),而不去拟合原始的 H ( x ) H(x) H(x),那深度网络所面临的拟合难度、优化难度就会大大降低。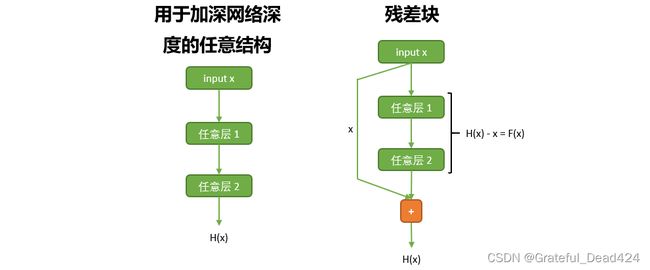
无论我们对卷积网络如何调整、让内部如何拟合,卷积网络的输出都必须是特征与标签之间的客观关系 H ( x ) H(x) H(x),否则精度就无从谈起。在这种情况下,我们如何让网络去拟合残差呢?如上图所示,一个残差单元中的输出分为两部分:一部分是输入 x x x,我们在不做任何操作的情况下将其输出,另一部分是经过残差单元中的卷积结构输出的拟合结果,而整个残差单元最终的输出是两部分输出的加和,即拟合结果 H ( x ) = x + H(x)=x+ H(x)=x+ 拟合结果 。在这个结构中,直接从输入到输出的 x x x被称为是快捷连接(shortcut connection)或跳跃连接(skip connection),残差单元就是令跳跃连接和普通卷积层并联、并加和其结果的结构。由于 H ( x ) = x + H(x)=x+ H(x)=x+ 拟合结果 ,拟合结果就等于 H ( x ) − x H(x)-x H(x)−x,也就是我们之前定义的残差 F ( x ) F(x) F(x)。在这个结构中,与拟合过程有关、与权重 w w w有关的就只有 F ( x ) F(x) F(x)的值,因此使用这个架构,我们能强迫卷积网络去拟合 。理想状况下,残差块会非常接近恒等函数,所以 H ( x ) H(x) H(x)的值应该非常接近 x x x本身,残差 F ( x ) F(x) F(x)就会很接近于0,如此,我们就强迫卷积网络向0的方向拟合了。
可以看到,残差单元使用一个很简单的技巧,实现了一个很精妙的操作。但残差单元的优势却远不止如此。
残差单元几乎实现了0负担增加深度。首先,跳跃连接不带有任何参数,普通卷积层的结构也不复杂,因此残差块的增加不会给模型带来太多额外的参数负担。同时,由于残差单元比普通网络更容易训练,并且在理论上能够保持网络的精度,因此残差网络的深度可以大幅增加,令整体架构自由享受加深深度所带来的福利。
残差单元还可以大幅加速训练和运算速度。在进行参数初始化时,我们常常使用0初始化。对残差单元而言,参数被初始为0,就意味着整个残差单元被初始化为恒等函数。如果恒等函数就是最优的加深网络深度的结构,那许多残差单元在初始化时就被设置在了自己的最优结果上,许多单元甚至不再需要被训练了,这会大大加快整体网络的训练速度。除此之外,残差单元可以在上层卷积层还未训练的时候就迅速将数据信息传递到下一层中。对于普通网络而言,如果上层网络网络还没有经过训练,信息是无法传递到下一层的,但对于残差块来说,最优状况下,训练的部分输出的结果应该非常接近0,因此即便卷积层还没有经过训练,我们直接将原始的 通过跳跃连接传递到下一层,对下一层而言应该也是一个不错的输入。因此在残差单元中,信息的传递速度会异常快速。因为卷积层接近于恒等函数,在对残差网络进行反向传播时,梯度也可以更快速地通过跳跃链接从后往前传递。

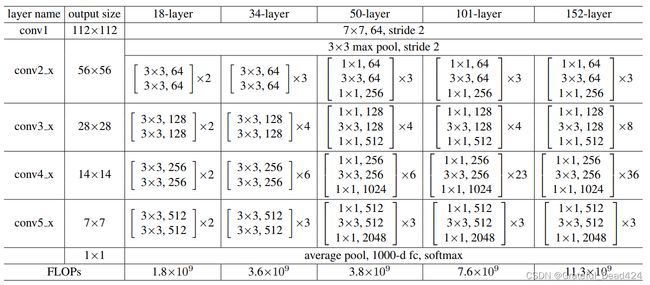
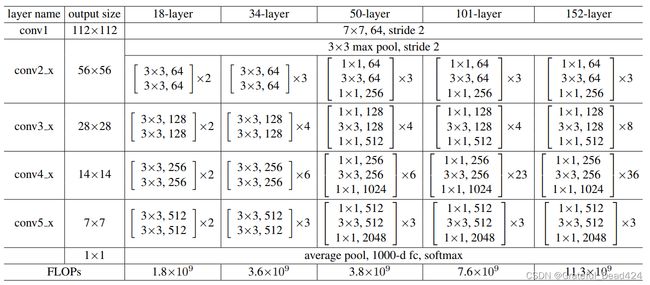
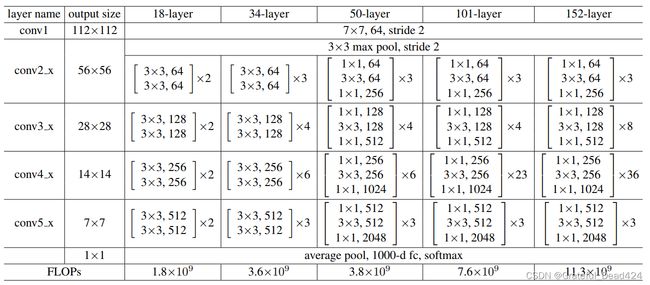
因此,无论从哪个角度来说,残差单元都是设计简单、功能精妙的架构。一个完整的残差网络,就是在普通卷积层和全局平均池化层中间插入数个残差单元的网络。如下图所示,原始论文中提出的残差网络共5种,其深度分别是18层、34层、50层、101层和152层。所有的残差网络都以一个7x7的卷积层开头,后接一个3x3,步长为2的重叠池化层,之后就在保持特征图尺寸一致的情况下重复残差单元,最后再跟上全局平均池化层,线性层以及softmax函数。对于34层及以下的残差网络,每个残差单元中至少有两个卷积层,如同conv2_x中所示的 [ 3 × 3 64 3 × 3 64 ] × 2 \left[\begin{array}{ll}3 \times 3 & 64 \\ 3 \times 3 & 64\end{array}\right] \times 2 [3×33×36464]×2表示有两个残差单元,每个残差单元中有两个核尺寸为3x3,输出为64的卷积层,且卷积层的输出尺寸是56x56。
对于50层及以上的残差网络,每个残差单元中有三个卷积层,分别是1x1卷积,3x3卷积以及1x1卷积。你应该对这个结构感觉到熟悉,因为这是我们之前在讲解1x1卷积时详细提到过的瓶颈架构bottleneck。瓶颈架构是为了降低参数量而存在的,对于50层以上的残差网络而言,瓶颈架构可以大规模降低参数,让残差网络整体的参数量得到控制。瓶颈架构中也带有跳跃连接,因此瓶颈架构也是一种残差单元,不过为了方便区分,我们统一将含有1x1卷积层的残差单元称为瓶颈架构。
从架构上来看,残差网络似乎并不是太难,毕竟网络中的所有元素都是我们曾经学过、使用过、实现过的内容。然而,残差网络的复现已经远远超出深度学习新手的水平,如果你只观察架构图、在没有任何代码参考的情况下自行对网络进行探索性构建,那理想的时间大约是3-5个工作日,因为残差网络复现过程中会有大量新手很难想象的细节问题,我们来一一说明。
- padding
首先,和其他表格类的架构图一致,残差网络的架构中也隐藏了许多默认信息,例如每个卷积层后的ReLU激活函数以及Batch Normalization,例如每一层的padding和stride。幸运的是,我们只有1x1和3x3两种卷积核,为了保持特征图的尺寸不变,1x1卷积核搭配的padding都为0,3x3卷积核搭配的padding都为1。
- stride
如图所示,随着残差网络的加深,特征图的尺寸也是在逐渐变小的。与GoogLeNet一样,当残差网络的输入图像为224x224时,特征图总共缩小了5次,每次长宽都折半,最终尺寸为7x7。这让网络的整体架构也被分成了5个部分,每个部分里重复的残差单元是一致的。在残差网络中,我们把这5个部分称为layers,每个layers中包含的残差单元或瓶颈结构是一个个block(块)。通常来说,让特征图尺寸降维的工作是池化层的任务,但残差网络中只在最初出现了一个重叠池化层,在残差单元或瓶颈结构中都不存在池化层,这说明5次降维任务中的其他4次都是由步长为2的卷积层来完成的。而这些步长为2的卷积层分别在conv1、conv3_x、conv4_x以及conv5_x中。对于conv3、4、5这三个layers来说,这个卷积层就是本层中第一个残差单元或瓶颈结构的第一个卷积层。在这些卷积层中,步长需要被设置为2。
- 跳跃连接上的卷积层
使用步长为2的卷积层来消减特征图尺寸并不是什么稀奇的操作,但基于此,初学者们常常会掉进一个陷阱:在实现了卷积层之后,大家会发现 F ( x ) F(x) F(x)与 x x x无法相加了。对于卷积网络而言, F ( x ) F(x) F(x)与 x x x都是一系列的特征图,两者相加则意味着对应特征图上对应位置的像素值一一加和。当经过瓶颈架构或残差单元,卷积层缩小了特征图尺寸,其输出的特征图 F ( x ) F(x) F(x)就无法与原始特征图 x x x相加了。因为原始特征图是直接通过跳跃连接进行输出的,所以尺寸不会发生变化,尺寸不同的矩阵自然无法加和。因此,每当卷积层缩小特征图尺寸时,也需要在跳跃连接上加入核为1x1、步长为2的卷积层用于缩小原始特征图的尺寸。特别的,我们使用虚线来表示含有1x1卷积层的跳跃连接。
同样需要注意的还有特征图数量的变化,这是整个架构中最让人头疼的部分。同样是 x x x和 F ( x ) F(x) F(x)相加的问题,如果特征图数量不同,矩阵也无法相加。对于任意残差网络而言, x x x的结构都必须与当前块输出的 F ( x ) F(x) F(x)结构相一致,因此无论特征图尺寸是否发生变化,我们都需要确保跳跃连接上1x1卷积层的输出数量与该block内部最后一个卷积层的输出数量一致。对于残差单元而言,一个块内部的特征图数量都是一致的,因此 x x x的特征图数量不总是需要进行转换(事实上,在非必要的时候,我们不对跳跃连接进行任何卷积操作,因为卷积操作会改变 x x x的数值,会削弱整个块作为恒等函数的效应)。但对于瓶颈架构而言,前两个卷积层共享输出的特征图数量middle_out,而最后一个卷积层输出的特征图数量是middle_out的四倍。因此在瓶颈架构中,无论特征图的尺寸是否发生变化,跳跃连接上都一定要有1x1卷积层来确保 x x x被整理为与 F ( x ) F(x) F(x)相同的结构。
- BN层与ReLU激活函数在哪里?
另一个还需要注意的点是BN层与ReLU激活函数的位置。对于不缩减特征图尺寸的残差单元而言,卷积核拟合出的 F ( x ) F(x) F(x)需要BN来调整数据分布,但通过跳跃连接被直接传到输出口的原始数据 x x x则不需要BN,但对于跳跃连接上存在1x1卷积层的情况来说,1x1卷积层后也需要BN。原则上来说,ReLU会出现在每一个BN层的后面,但对于残差单元或瓶颈架构来说,整体输出应当是 H ( x ) H(x) H(x),因此ReLU函数需要被放置在 x x x和F(x)相加之后。
- 参数初始化在哪里实现?
在学习神经网络的优化流程时,我们曾经学过不少参数初始化的相关知识。通常我们在初始化参数时,是遵循某种分布的初始化参数能够帮助模型更好地收敛,因此我们会使用循环对每层的参数进行初始化设置。但在残差网络中,我们初始化参数的目的是令残差单元或瓶颈架构尽量与恒等函数相似,因此普通的初始化方式并不适合我们。观察残差单元与瓶颈架构,如果我们希望整个块与恒等函数尽量相似,我们就需要尽量让 F ( x ) F(x) F(x)的值为0。对于两种块而言,最后一个能够作用于 F ( x ) F(x) F(x)的值的架构是最后一个卷积层后的BN层。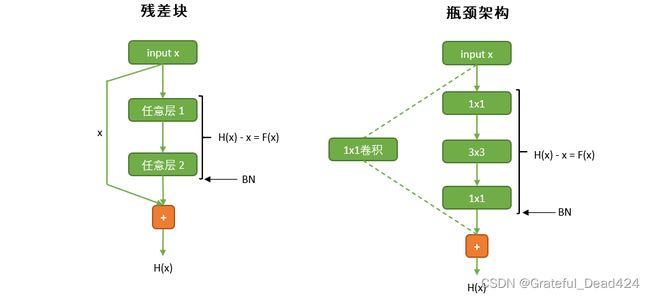
作为归一化手段,Batch Normlization通过以下公式对数据产生影响。其中 γ \gamma γ和 β \beta β是需要学习的参数。不难发现,如果我们将 γ \gamma γ和 β \beta β都设置为0,那任何经过BN层的数据都会为0。而nn.BatchNorm2d中默认 β \beta β为0,所以我们只需要将残差单元或瓶颈架构中最后一个卷积层后的BN层上的 γ \gamma γ参数设置为0,就可以让 F ( x ) F(x) F(x)的输出结果为0了。
output = x − E [ x ] Var [ x ] + ϵ ∗ γ + β \text { output }=\frac{x-E[x]}{\sqrt{\operatorname{Var}[x]+\epsilon}} * \gamma+\beta output =Var[x]+ϵx−E[x]∗γ+β论文《Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour》指出,使用这种初始化方式可以让残差网络的精度提升0.2~0.3%,在PyTorch中我们也是使用这样的方式来初始化参数。至于卷积层的参数,我们依然使用PyTorch默认的、高斯分布下的随机数。
- 特征图数量频繁、多样地变化
在之前我们学习的任意网络中,特征图的尺寸都会发生一定的变化,但没有一种架构的特征图变化像残差网络这样频繁和多样。之前我们遇见过的、最常见的变化是“翻倍”,随着网络深度加深,特征图的数量由128翻倍至256,在至512,最终可达2048。之前,无论一个网络架构中有多少相似的层或相似的元素,我们都通过从输入到输出向下罗列层的方式将网络进行呈现,以求网络架构与架构图尽量相似。因此,特征图数量的变化可以被详细地展现在每个卷积层的连接上。我们唯一需要保证的,就是上个卷积层的输出特征图数量与下个卷积层的输入特征图数量一致。然而这种方式在残差网络上并行不通。残差网络比我们之前复现过的任何网络都要深得多,虽然我们可能列举几个相连的层,但我们不可能列举101或者152层网络。因此,我们必须使用具有一定通用性的代码来实现不同的层。这意味着,我们不能按照每层的输入、输出的方式来控制卷积的输入和输出,而不同的卷积层需要共享我们输入的超参数,同时,超参数的数量不能很多。
当网络结构是高度重复时,通用性代码往往会比较简单。然而,在特征图频繁、多样变化的情况下,事情就变得复杂了,因为我们必须要想办法区别不同场景下的特征图数量的变化规律。对于50层以下的残差网络来说,增加深度的结构是残差单元,因此特征图数量会存在以下2种情况:
- 1、保持不变。conv1与conv2_x连接时,每个layers内部不同的残差单元在连接时,特征图数量是不变的
- 2、翻倍。在不同的layers之间连接时,下一个layers输出的特征图数量是上一个layers输出数量的2倍。
对于50层以上的残差网络来说,事情会更复杂。深层残差网络中用来增加深度的结构是带有跳跃连接的瓶颈架构,一个瓶颈架构中涉及到3个卷积层,特征图数量会存在如下4种情况:
- 1、保持不变。conv1与conv2_x连接时,一个瓶颈架构内嵌两个卷积层连接时,特征图数量保持不变。
- 2、变成上层输出数量的四倍。在一个瓶颈架构内,前两个卷积层共享特征图数目(如我们之前所说,使用middle_out进行表示),但是第三个1x1卷积层的输出特征图数量是4 *middle_out。
- 3、变成上层输出数量的1/4。在一个layers内,上一个瓶颈架构与下一个瓶颈架构连接时,特征图数目需要从 middle_out恢复成middle_out。
- 4、变成上层输出数量的1/2。在不同的layers之间连接时,上一个瓶颈架构输出的特征图数量是下一个瓶颈架构输出特征图数量的2倍。
在代码中,我们必须想办法区别上述所有不同场景中不同的特征图数量变化。在这些数量变化中,只要有一层报错,整个残差网络就无法运行。同时,我们的代码还必须考虑到以上提到的padding、stride、初始化、BN等所有的因素。理想状况下,我们还希望不同层的残差网络可以共享一个类,在一个类的基础上,我们使用不同的参数来控制内部结构及所有卷积层上的变化,并且代码要尽量简洁和清晰。现在你知道为什么复现残差网络有点超出初学者的能力范围了吧,在这个过程中想要整理出清晰的逻辑并不是一件容易的事儿。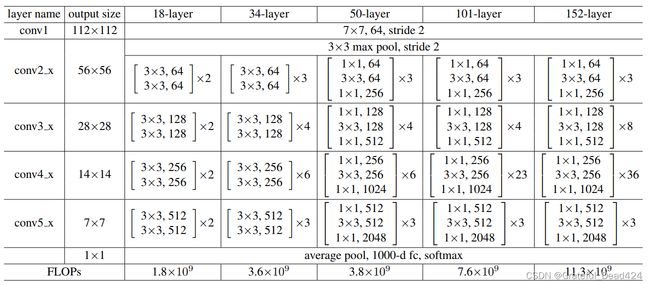
现在我们就来复现一下残差网络,我们将创造一个通用的类,在这个类上输入相关的参数,就可以实现上图中展现的五种残差网络。和复现GoogLeNet时一样,我们先从简单的、可以打包的元素开始定义。残差网络中的卷积层虽然变化多端,但其实只有两种:3x3卷积层与1x1卷积层,并且我们知道,每个卷积层后面都需要跟上BN层,而BN层上可以完成参数初始化。我们就从这里开始写:
#basicconv - conv2d + BN + ReLU (→ conv3x3, conv1x1)
#Residual Unit, Bottleneck
#导入需要的库
import torch
import torch.nn as nn
from typing import Type, Union, List, Optional
from torchinfo import summary
def conv3x3(in_, out_, stride=1, initialzero = False):
bn = nn.BatchNorm2d(out_)
#需要进行判断:要对BN进行0初始化吗?
#最后一层就初始化,不是最后一层就不改变gamma和beta
if initialzero == True:
nn.init.constant_(bn.weight, 0)
return nn.Sequential(nn.Conv2d(in_, out_
, kernel_size=3,padding=1, stride = stride
, bias = False)
,bn)
conv3x3(2,10)
#Sequential(
# (0): Conv2d(2, 10, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (1): BatchNorm2d(10, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
#)
def conv1x1(in_, out_, stride=1, initialzero = False):
bn = nn.BatchNorm2d(out_)
#需要进行判断:要对BN进行0初始化吗?
#最后一层就初始化,不是最后一层就不改变gamma和beta
if initialzero == True:
nn.init.constant_(bn.weight, 0)
return nn.Sequential(nn.Conv2d(in_, out_
, kernel_size=1,padding=0, stride = stride
, bias = False)
,bn)
conv1x1(2,10,1,True)[1].weight #请帮我执行0初始化
#Parameter containing:
#tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.], requires_grad=True)
conv1x1(2,10,1)[1].weight #没有执行0初始化
#Parameter containing:
#tensor([1., 1., 1., 1., 1., 1., 1., 1., 1., 1.], requires_grad=True)
有了架构中的最小单位“卷积层”,我们就可以来写由卷积层构成的残差单元和瓶颈架构了。这两个架构块都需要定义成类,因为数据需要从中流过。
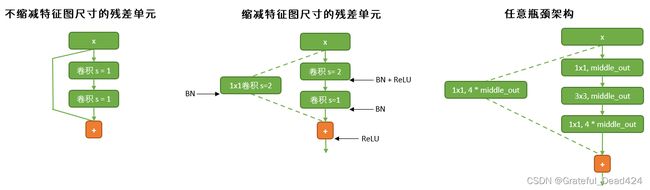
我们先来看残差单元。一个残差单元中只包含两个卷积层和一个加和功能。参照这张图,我们先将最基础的结构(不缩减特征图尺寸的残差单元)写出来。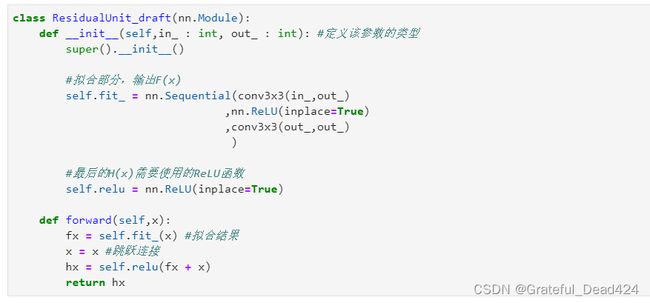
在写foward函数时我们习惯于让x = self.function,但在残差单元中我们需要原始x的值,因此千万别将原始x进行覆盖。如果你担心自己会不小心覆盖掉原始x,也可以在foward函数一开始就添加类似于identity = x的语句,先将x的值保存在另一个变量当中,方便后续调用。
【1 初始化】在上面所写的结构的基础上,我们来考虑初始化的存在。根据初始化的相关理论,初始化只会发生在每个残差单元最后一个卷积层的bn层上,因此我们将最后一个层的参数initialzero设置为True,其他地方不做修改,因此其他卷积层中的0初始化功能并未开启。
【2 步长】接下来考虑步长stride的存在。残差网络使用stride=2的卷积层来给特征图降维,并且每次降维都发生在layers与layers之间。无论是残差单元还是瓶颈架构,一旦降维之后,一个layers内部的特征图尺寸是不变的,这说明降维任务是由每个layers中第一个残差单元或瓶颈架构上的第一个卷积层完成的。基于这个理解,我们将残差单元中第一个卷积层上的步长定义为参数stride1,并且让这个参数只影响架构中的第一个卷积层,也就是第一个conv3x3层。当stride1=1时,任何卷积层都不执行降维操作。当stride1=2时,只有第一个卷积层执行降维操作。后续的卷积层的stride参数不受stride1的影响,因为他们受到conv3x3和conv1x1中定义的默认值stride=1的控制。
还记得我们之前说过的F(x)与x相加的问题吗?每当卷积网络将特征图尺寸减半,跳跃连接上也需要存在1x1卷积层令x的尺寸减半,因此我们需要添加单独的skipconv。这个卷积层的步长与第一个conv3x3的步长一致,只有当第一个conv3x3的步长为2时,skipconv上的步长才需要为2,因此我们让skipconv的步长也等于stride1。同时,skipconv不是随时都需要存在的,只有当stride1=2的时候才需要skipconv,因此我们需要将forward函数中的内容改写为一个if条件:如果stride1不等于1,则执行skipconv,否则不执行。为此,还需要在__init__函数中设置属性self.stride1。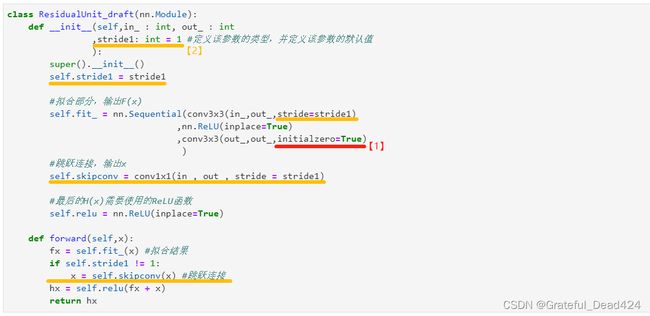
【3 特征图数量的变化】如我们之前所提到的,在使用残差单元的浅层残差网络里,每当我们利用步长=2来缩小特征图尺寸,特征图的数量也会翻倍。
观察18或34层的浅层残差网络,我们可以总计出如下规律:在layers与layers连接之处,步长总是为2,此时本层输出的特征图数量out_就等于上层的特征图数量in_ * 2。在conv1和conv2_x连接之处,以及一个layers内部不同的残差单元连接时,步长总是为1,此时本层输出的特征图数量out_就等于上层特征图数量in_。简单来说,在知道步长取值的前提下,我们只需要out_或in_中的任意一个参数,就可以计算另外一个参数。这可以帮助我们削减类的参数量。那究竟要保留out_还是in_作为输入的参数呢?答案是保留out_。你是否发现,深层和浅层残差网络在每个layers中共享的唯一数字就是卷积层上输出的特征图数目,如果保留out_,我们就有可能将现在正在写的残差单元类和之后要写的瓶颈架构类打包在一个类中,让他们共享参数out_。基于这个理解,我们将参数中的in_删除,并将代码改写为下图所示的样子: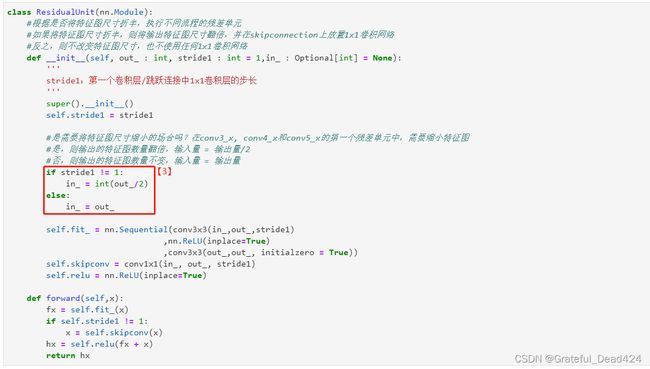
代码如下:
class ResidualUnit(nn.Module):
#这是残差单元类
#stride1是否等于2呢?如果等于2 - 特征图尺寸会发生变化
#需要在跳跃链接上增加1x1卷积层来调整特征图尺寸
#如果stride1等于1,则什么也不需要做
def __init__(self,out_: int
,stride1: int = 1 #定义该参数的类型,并且定义默认值
,in_ : Optional[int] = None
):
super().__init__()
self.stride1 = stride1
#当特征图尺寸需要缩小时,卷积层的输出特征图数量out_等于输入特征图数量in_的2倍
#当特征图尺寸不需要缩小时,out_ == in_
if stride1 !=1:
in_ = int(out_/2)
else:
in_ = out_
#拟合部分,输出F(x)
self.fit_ = nn.Sequential(conv3x3(in_,out_,stride=stride1)
,nn.ReLU(inplace=True)
,conv3x3(out_,out_,initialzero=True)
)
#跳跃链接,输出x(1x1卷积核之后的x)
self.skipconv = conv1x1(in_,out_,stride = stride1)
#单独定义放在H(x)之后来使用的激活函数ReLU
self.relu = nn.ReLU(inplace=True)
def forward(self,x):
fx = self.fit_(x) #拟合结果
if self.stride1 != 1:
x = self.skipconv(x) #跳跃链接
hx = self.relu(fx + x)
return hx
#ResidualUnit(out_,stride1)
data = torch.ones(10,64,56,56)
conv3_x_18_0 = ResidualUnit(out_=128,stride1 = 2)
#0号残差单元 - 需要特征图折半,特征图数量加倍
conv3_x_18_0(data).shape
#torch.Size([10, 128, 28, 28])
conv2_x_18_0 = ResidualUnit(out_ = 64)
conv2_x_18_0(data).shape
#torch.Size([10, 64, 56, 56])
基于上面的流程,你可以自己试着写写看瓶颈架构的代码,其流程与关键点都与上述代码非常相似,只不过瓶颈架构在特征图数量变化上的情况更加复杂。同样的,我们可以试着先复原最基础、最简单的瓶颈架构,并且将步长、初始化这些和残差单元一模一样的情况考虑进去。在参考残差单元代码的基础上,你应该至少能将瓶颈架构的代码还原到这个程度:

这段代码中有两处值得一提的地方:
- 1、瓶颈架构中有三种特征图数量,一种是整体架构的输入特征图数目in_,一种是瓶颈架构最终的特征图输出数量out_,还有一种是前两个卷积层所输出的特征图数量middle_out。意识到middle_out和in_以及out_都不同是正确复现瓶颈架构的关键。
- 2、对瓶颈架构而言,输入x和输出F(x)的特征图数量一定不一致,因此x必须要经过1x1卷积层的转化,因此skipconv是必须要存在的。
在此基础上,我们来看瓶颈架构中【1 特征图数量变化的问题】。与残差单元不同,瓶颈架构内部存在特征图数量的变化,不过由于我们能够将三个层串联起来写,通过给卷积层输出参数,我们可以完美规避掉串联的层之间输入输出不符导致出错的问题。因此更关键的还是瓶颈架构与瓶颈架构之间、layers与layers之间连接时的特征图数量变化。在conv3_x, conv4_x和conv5_x三个layers相互连接时,我们需要缩小特征图。若以middle_out为基准,每次缩小特征图时,上层特征图数量in_就等于本层middle_out的2倍。在一个layers中,不同的瓶颈架构在相互连接时,需要放大特征图,此时上层特征图数量in_就等于本层middle_out的4倍。还有一个特例是conv1与conv2_x连接的时候,此时特征图的大小不变,上层特征图数量in_就等于本层middle_out的值。围绕着唯一的参数middle_out,我们有数种方法可以实现这个逻辑。在这里,我采用了较为简单的一种方法:使用两个条件判断。
首先,我设置了选填参数in_,这个参数可以不填写,默认值为None。只有当瓶颈架构是conv1与conv2_x连接时,我才填写这个参数,并令这个参数等于64。除此之外,in_都等于None,且默认不是conv1与conv2_x之间的连接。当in_等于None时,一切就只分为两种情况了:当stride1=2,特征图尺寸下降时,或其他。基于此逻辑,我将代码改写为下图所示: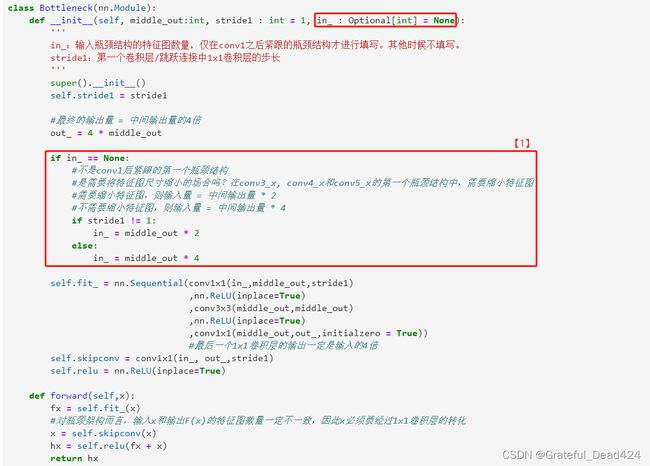
代码如下:
class Bottleneck(nn.Module):
#是需要将特征图尺寸缩小的场合吗?
#conv2_x - conv3_x - conv4_x - conv5_x 相互链接的时候
#每次都需要将特征图尺寸折半,同时卷积层上的middle_out = 1/2in_
def __init__(self, middle_out
, stride1: int = 1
, in_: Optional[int] = None):
super().__init__()
out_ = 4 * middle_out
#我希望使用选填参数in_来帮助我们区别,这个架构是不是在conv1的后面
#如果这个架构不是紧跟在conv1后,就不填写in_
#如果是跟在conv1后,就填写in_ = 64
if in_ == None:
if stride1 !=1: #缩小特征图的场合,即这个瓶颈结构是每个layers的第一个瓶颈结构
in_ = middle_out * 2
#不缩小特征图的场合,即这个瓶颈结构不是这个layers的第一个瓶颈结构
#而是跟在第一个瓶颈结构后的重复的结构
else:
in_ = middle_out * 4
self.fit_ = nn.Sequential(conv1x1(in_,middle_out,stride=stride1)
,nn.ReLU(inplace=True)
,conv3x3(middle_out,middle_out)
,nn.ReLU(inplace=True)
,conv1x1(middle_out,out_,initialzero=True))
self.skipconv = conv1x1(in_, out_, stride=stride1)
self.relu = nn.ReLU(inplace=True)
def forward(self,x):
fx = self.fit_(x)
#跳跃链接
x = self.skipconv(x)
hx = self.relu(fx + x)
return hx
#测试
data1 = torch.ones(10,64,56,56) #conv2x的输入
#假设,我是conv1后紧跟的第一个瓶颈结构
conv2_x_101_0 = Bottleneck(in_ = 64, middle_out=64)
conv2_x_101_0(data1).shape #特征图尺寸不变,输出翻四倍
#torch.Size([10, 256, 56, 56])
#不是conv1后紧跟的第一个瓶颈结构,但是需要缩小特征图尺寸
data2= torch.ones(10,256,56,56)
conv3_x_101_0 = Bottleneck(middle_out=128,stride1=2)
conv3_x_101_0(data2).shape #输出翻两倍,特征图尺寸缩小一半
#torch.Size([10, 512, 28, 28])
#不是conv1后的第一个瓶颈结构,也不需要缩小特征图
data3 = torch.ones(10,512,28,28)
conv3_x_101_1 = Bottleneck(128)
conv3_x_101_1(data3).shape #输出数量不变,特征图尺寸也不变
#torch.Size([10, 512, 28, 28])
为了让残差单元和瓶颈架构的参数保持一致,我为残差单元的类也添加了可选参数in_,这样可以保证将ResidualUnit和Bottleneck两个类合并在一起时不会报错。不过根据残差单元的代码,这个in_的存在不会对类产生任何的影响,因为残差单元的执行代码中并没有任何会使用in_输入值或原始值的地方。一旦残差单元的代码运行,对象in_就会被重新赋值。
除了我们所使用的选填参数、if条件之外,还有许多其他写法都可以处理特征图数量变化引起的问题。最容易想到的一种就是让每个残差单元或瓶颈架构输出自己的out_值,再将这个值直接作为下层网络的输入值。当然,采取这种方法时,我们保留在ResidualUnit和Bottleneck两个类中的参数就不能是out_了(根据经验,如果采用这种思路,则必须同时保留in_和out_),同时在包装好的残差网络类中我们也需要写明提取上层out_并放入下层的代码。
现在,我们已经完成了残差单元和瓶颈架构的类(如下所示)。不难发现,虽然每个类内部的逻辑需要进行一些梳理,但我们完成的类只有3个参数:这个块中的输出的特征图数量/中间输出量,这个块中第一个卷积层的步长,以及选填的输入特征图数量。对于同一个layer,残差块中的输出特征图数目 = 瓶颈架构中的中间输出量,而步长其实隐性地决定了这个block在架构中是否位于需要降低特征图尺寸的位置。现在,我们需要将这两个类打包到一个更高级的类中,用来生成每个layers中所有的blocks。
class Bottleneck(middle_out, stride1, in_(optional))
class ResidualUnit(out_, stride1, in_(optional))
观察架构图。残差网络的每个layers中都存在大量重复的元素,在深层残差网络中,conv4_x中甚至将瓶颈架构重复了30次以上,如果能够使用代表数量的参数和for循环来对重复的部分进行控制,我们就可以大幅提高生成网络的效率。我们为新类命名为make_layers,具体代码如下:
def make_layers(block: Type[Union[ResidualUnit, Bottleneck]]
, middle_out: int
, blocks: int
, afterconv1: bool = False):
'''
构建残差网络中layers的类
block: 架构块的类型,可选ResidualUnit或Bottleneck。依据选择的架构块类型,可判断该残差
网络的深浅
middle_out: ResidualUnit中输出的特征图数目/Bottleneck中的中间输出量,对两个block可混
用
blocks:这个layer中的block数量
afterconv1:这个layer是否紧接在conv1之后?
'''
layers = []
#整个残差块或瓶颈结构的第一层
#是conv1后的第一个block吗?
if afterconv1 == True:
#输入为64,middle_out也为64,且不改变特征图尺寸
layers.append(block(middle_out, in_ = 64))
else:
#需要改变特征图尺寸,步长为2
layers.append(block(middle_out, stride1 = 2))
#重复的残差单元/瓶颈架构
for _ in range(blocks-1):
layers.append(block(middle_out))
return nn.Sequential(*layers) #python常见用法,星号解析列表/储存器
这段代码非常简单易懂,需要重点说明一下的有两点:
- 1、从架构图上可以看出,每个layers中存在两种blocks,一种是影响特征图尺寸的、每个layers中的第一个块:0号block,另一种是0号block之后不断重复、并无变化的其他blocks。很明显,无论是特征图尺寸变化、衔接上一个block传出的输出数据,还是衔接普通卷积层conv1,0号block上可能存在各种各样的变化,因此需要单独处理。而其他重复的blocks,则可以使用for循环来一笔带过。
- 2、对于0号block,我们也有两种情况:紧跟在conv1后的、位于conv2_x上的block0,以及在conv2_x、3_x、4_x、5_x之间进行链接的block0。对于紧跟在conv1后的block,它不影响特征图尺寸,它的输入特征图数量一定等于64。而其他block0则都是步长为2的、可以将特征图尺寸折半的block0。
基于这个逻辑,我们可以对代码进行测试:
layer_34_conv4_x = make_layers(ResidualUnit,
256,
6,
False)
#34层网络,conv2_x,紧跟在conv1后的首个架构
#不缩小特征图尺寸,每层的输出都是64,3个块
conv2_x_34 = make_layers(ResidualUnit,
64,
3,
afterconv1 = True)
datashape = (10,64,56,56)
summary(conv2_x_34,datashape,depth=1,device="cpu")
#==========================================================================================
#Layer (type:depth-idx) Output Shape Param #
#==========================================================================================
#├─ResidualUnit: 1-1 [10, 64, 56, 56] 78,208
#├─ResidualUnit: 1-2 [10, 64, 56, 56] 78,208
#├─ResidualUnit: 1-3 [10, 64, 56, 56] 78,208
#==========================================================================================
#Total params: 234,624
#Trainable params: 234,624
#Non-trainable params: 0
#Total mult-adds (M): 291.59
#==========================================================================================
#Input size (MB): 8.03
#Forward/backward pass size (MB): 0.00
#Params size (MB): 0.94
#Estimated Total Size (MB): 8.97
#==========================================================================================
datashape = (10,64,56,56)
conv2_x_101 = make_layers(Bottleneck,
64,
3,
afterconv1 = True)
summary(conv2_x_101,datashape,depth=3,device="cpu")
# ==========================================================================================
# Layer (type:depth-idx) Output Shape Param #
# ==========================================================================================
# ├─Bottleneck: 1-1 [10, 256, 56, 56] --
# | └─Sequential: 2-1 [10, 256, 56, 56] --
# | | └─Sequential: 3-1 [10, 64, 56, 56] 4,224
# | | └─ReLU: 3-2 [10, 64, 56, 56] --
# | | └─Sequential: 3-3 [10, 64, 56, 56] 36,992
# | | └─ReLU: 3-4 [10, 64, 56, 56] --
# | | └─Sequential: 3-5 [10, 256, 56, 56] 16,896
# | └─Sequential: 2-2 [10, 256, 56, 56] --
# | | └─Conv2d: 3-6 [10, 256, 56, 56] 16,384
# | | └─BatchNorm2d: 3-7 [10, 256, 56, 56] 512
# | └─ReLU: 2-3 [10, 256, 56, 56] --
# ├─Bottleneck: 1-2 [10, 256, 56, 56] --
# | └─Sequential: 2-4 [10, 256, 56, 56] --
# | | └─Sequential: 3-8 [10, 64, 56, 56] 16,512
# | | └─ReLU: 3-9 [10, 64, 56, 56] --
# | | └─Sequential: 3-10 [10, 64, 56, 56] 36,992
# | | └─ReLU: 3-11 [10, 64, 56, 56] --
# | | └─Sequential: 3-12 [10, 256, 56, 56] 16,896
# | └─Sequential: 2-5 [10, 256, 56, 56] --
# | | └─Conv2d: 3-13 [10, 256, 56, 56] 65,536
# | | └─BatchNorm2d: 3-14 [10, 256, 56, 56] 512
# | └─ReLU: 2-6 [10, 256, 56, 56] --
# ├─Bottleneck: 1-3 [10, 256, 56, 56] --
# | └─Sequential: 2-7 [10, 256, 56, 56] --
# | | └─Sequential: 3-15 [10, 64, 56, 56] 16,512
# | | └─ReLU: 3-16 [10, 64, 56, 56] --
# | | └─Sequential: 3-17 [10, 64, 56, 56] 36,992
# | | └─ReLU: 3-18 [10, 64, 56, 56] --
# | | └─Sequential: 3-19 [10, 256, 56, 56] 16,896
# | └─Sequential: 2-8 [10, 256, 56, 56] --
# | | └─Conv2d: 3-20 [10, 256, 56, 56] 65,536
# | | └─BatchNorm2d: 3-21 [10, 256, 56, 56] 512
# | └─ReLU: 2-9 [10, 256, 56, 56] --
# ==========================================================================================
# Total params: 347,904
# Trainable params: 347,904
# Non-trainable params: 0
# Total mult-adds (G): 12.78
# ==========================================================================================
# Input size (MB): 8.03
# Forward/backward pass size (MB): 963.38
# Params size (MB): 1.39
# Estimated Total Size (MB): 972.80
# ==========================================================================================
conv4_x_101 = make_layers(Bottleneck,256,23)
datashape = (10,512,28,28)
summary(conv4_x_101, datashape, depth=1, device='cpu')
# ==========================================================================================
# Layer (type:depth-idx) Output Shape Param #
# ==========================================================================================
# ├─Bottleneck: 1-1 [10, 1024, 14, 14] 1,512,448
# ├─Bottleneck: 1-2 [10, 1024, 14, 14] 2,167,808
# ├─Bottleneck: 1-3 [10, 1024, 14, 14] 2,167,808
# ├─Bottleneck: 1-4 [10, 1024, 14, 14] 2,167,808
# ├─Bottleneck: 1-5 [10, 1024, 14, 14] 2,167,808
# ├─Bottleneck: 1-6 [10, 1024, 14, 14] 2,167,808
# ├─Bottleneck: 1-7 [10, 1024, 14, 14] 2,167,808
# ├─Bottleneck: 1-8 [10, 1024, 14, 14] 2,167,808
# ├─Bottleneck: 1-9 [10, 1024, 14, 14] 2,167,808
# ├─Bottleneck: 1-10 [10, 1024, 14, 14] 2,167,808
# ├─Bottleneck: 1-11 [10, 1024, 14, 14] 2,167,808
# ├─Bottleneck: 1-12 [10, 1024, 14, 14] 2,167,808
# ├─Bottleneck: 1-13 [10, 1024, 14, 14] 2,167,808
# ├─Bottleneck: 1-14 [10, 1024, 14, 14] 2,167,808
# ├─Bottleneck: 1-15 [10, 1024, 14, 14] 2,167,808
# ├─Bottleneck: 1-16 [10, 1024, 14, 14] 2,167,808
# ├─Bottleneck: 1-17 [10, 1024, 14, 14] 2,167,808
# ├─Bottleneck: 1-18 [10, 1024, 14, 14] 2,167,808
# ├─Bottleneck: 1-19 [10, 1024, 14, 14] 2,167,808
# ├─Bottleneck: 1-20 [10, 1024, 14, 14] 2,167,808
# ├─Bottleneck: 1-21 [10, 1024, 14, 14] 2,167,808
# ├─Bottleneck: 1-22 [10, 1024, 14, 14] 2,167,808
# ├─Bottleneck: 1-23 [10, 1024, 14, 14] 2,167,808
# ==========================================================================================
# Total params: 49,204,224
# Trainable params: 49,204,224
# Non-trainable params: 0
# Total mult-adds (T): 1.01
# ==========================================================================================
# Input size (MB): 16.06
# Forward/backward pass size (MB): 0.00
# Params size (MB): 196.82
# Estimated Total Size (MB): 212.87
# ==========================================================================================
现在我们已经具备了构建layers的能力,可以开始构建自己的残差网络了。定义残差网络的类ResNet可能是所有复现步骤中最简单的一个,它与我们之前熟悉的其他网络的定义方式非常类似。参照架构图,定义残差网络的代码如下:
class ResNet(nn.Module):
def __init__(self,block: Type[Union[ResidualUnit, Bottleneck]]
,layers: List[int]
,num_classes : int):
super().__init__()
'''
block:要使用的用来加深深度的基本架构是?可以选择残差单元或瓶颈结构,两种都带有skip connection
layers:列表,每个层里具体有多少个块呢?可参考网络架构图。例如,34层的残差网络的layers = [3,4,6,3]
num_classes:真实标签含有多少个类别?
'''
#layer1:卷积+池化的组合
self.layer1 = nn.Sequential(nn.Conv2d(3,64
,kernel_size=7,stride=2
,padding=3,bias = False)
,nn.BatchNorm2d(64)
,nn.ReLU(inplace=True)
,nn.MaxPool2d(kernel_size=3
,stride=2
,ceil_mode = True))
#layer2 - layer5:残差块/瓶颈结构
self.layer2_x = make_layers(block,64,layers[0],afterconv1=True)
self.layer3_x = make_layers(block,128,layers[1])
self.layer4_x = make_layers(block,256,layers[2])
self.layer5_x = make_layers(block,512,layers[3])
#全局平均池化
self.avgpool = nn.AdaptiveAvgPool2d((1,1))
#分类
if block == ResidualUnit:
self.fc = nn.Linear(512,num_classes)
else:
self.fc = nn.Linear(2048,num_classes)
def forward(self,x):
x = self.layer1(x) #layer1,普通卷积+池化的输出
x = self.layer5_x(self.layer4_x(self.layer3_x(self.layer2_x(x))))
x = self.avgpool(x) #特征图尺寸1x1 (n_samples, fc, 1, 1)
x = torch.flatten(x,1)
x = self.fc(x)
完成定义之后,即可进行测试:
#ResNet(block,layers,num_classes)
datashape = (10,3,224,224) #ImageNet数据集的结构
res34 = ResNet(ResidualUnit,[3,4,6,3],num_classes = 1000)
res101 = ResNet(Bottleneck,[3,4,23,3],num_classes = 1000)
summary(res34,datashape,depth=2,device="cpu")
# ==========================================================================================
# Layer (type:depth-idx) Output Shape Param #
# ==========================================================================================
# ├─Sequential: 1-1 [10, 64, 56, 56] --
# | └─Conv2d: 2-1 [10, 64, 112, 112] 9,408
# | └─BatchNorm2d: 2-2 [10, 64, 112, 112] 128
# | └─ReLU: 2-3 [10, 64, 112, 112] --
# | └─MaxPool2d: 2-4 [10, 64, 56, 56] --
# ├─Sequential: 1-2 [10, 64, 56, 56] --
# | └─ResidualUnit: 2-5 [10, 64, 56, 56] 78,208
# | └─ResidualUnit: 2-6 [10, 64, 56, 56] 78,208
# | └─ResidualUnit: 2-7 [10, 64, 56, 56] 78,208
# ├─Sequential: 1-3 [10, 128, 28, 28] --
# | └─ResidualUnit: 2-8 [10, 128, 28, 28] 230,144
# | └─ResidualUnit: 2-9 [10, 128, 28, 28] 312,064
# | └─ResidualUnit: 2-10 [10, 128, 28, 28] 312,064
# | └─ResidualUnit: 2-11 [10, 128, 28, 28] 312,064
# ├─Sequential: 1-4 [10, 256, 14, 14] --
# | └─ResidualUnit: 2-12 [10, 256, 14, 14] 919,040
# | └─ResidualUnit: 2-13 [10, 256, 14, 14] 1,246,720
# | └─ResidualUnit: 2-14 [10, 256, 14, 14] 1,246,720
# | └─ResidualUnit: 2-15 [10, 256, 14, 14] 1,246,720
# | └─ResidualUnit: 2-16 [10, 256, 14, 14] 1,246,720
# | └─ResidualUnit: 2-17 [10, 256, 14, 14] 1,246,720
# ├─Sequential: 1-5 [10, 512, 7, 7] --
# | └─ResidualUnit: 2-18 [10, 512, 7, 7] 3,673,088
# | └─ResidualUnit: 2-19 [10, 512, 7, 7] 4,983,808
# | └─ResidualUnit: 2-20 [10, 512, 7, 7] 4,983,808
# ├─AdaptiveAvgPool2d: 1-6 [10, 512, 1, 1] --
# ├─Linear: 1-7 [10, 1000] 513,000
# ==========================================================================================
# Total params: 22,716,840
# Trainable params: 22,716,840
# Non-trainable params: 0
# Total mult-adds (G): 266.86
# ==========================================================================================
# Input size (MB): 6.02
# Forward/backward pass size (MB): 128.53
# Params size (MB): 90.87
# Estimated Total Size (MB): 225.42
# ==========================================================================================
summary(res101,datashape,depth=2,device="cpu")
# ==========================================================================================
# Layer (type:depth-idx) Output Shape Param #
# ==========================================================================================
# ├─Sequential: 1-1 [10, 64, 56, 56] --
# | └─Conv2d: 2-1 [10, 64, 112, 112] 9,408
# | └─BatchNorm2d: 2-2 [10, 64, 112, 112] 128
# | └─ReLU: 2-3 [10, 64, 112, 112] --
# | └─MaxPool2d: 2-4 [10, 64, 56, 56] --
# ├─Sequential: 1-2 [10, 256, 56, 56] --
# | └─Bottleneck: 2-5 [10, 256, 56, 56] 75,008
# | └─Bottleneck: 2-6 [10, 256, 56, 56] 136,448
# | └─Bottleneck: 2-7 [10, 256, 56, 56] 136,448
# ├─Sequential: 1-3 [10, 512, 28, 28] --
# | └─Bottleneck: 2-8 [10, 512, 28, 28] 379,392
# | └─Bottleneck: 2-9 [10, 512, 28, 28] 543,232
# | └─Bottleneck: 2-10 [10, 512, 28, 28] 543,232
# | └─Bottleneck: 2-11 [10, 512, 28, 28] 543,232
# ├─Sequential: 1-4 [10, 1024, 14, 14] --
# | └─Bottleneck: 2-12 [10, 1024, 14, 14] 1,512,448
# | └─Bottleneck: 2-13 [10, 1024, 14, 14] 2,167,808
# | └─Bottleneck: 2-14 [10, 1024, 14, 14] 2,167,808
# | └─Bottleneck: 2-15 [10, 1024, 14, 14] 2,167,808
# | └─Bottleneck: 2-16 [10, 1024, 14, 14] 2,167,808
# | └─Bottleneck: 2-17 [10, 1024, 14, 14] 2,167,808
# | └─Bottleneck: 2-18 [10, 1024, 14, 14] 2,167,808
# | └─Bottleneck: 2-19 [10, 1024, 14, 14] 2,167,808
# | └─Bottleneck: 2-20 [10, 1024, 14, 14] 2,167,808
# | └─Bottleneck: 2-21 [10, 1024, 14, 14] 2,167,808
# | └─Bottleneck: 2-22 [10, 1024, 14, 14] 2,167,808
# | └─Bottleneck: 2-23 [10, 1024, 14, 14] 2,167,808
# | └─Bottleneck: 2-24 [10, 1024, 14, 14] 2,167,808
# | └─Bottleneck: 2-25 [10, 1024, 14, 14] 2,167,808
# | └─Bottleneck: 2-26 [10, 1024, 14, 14] 2,167,808
# | └─Bottleneck: 2-27 [10, 1024, 14, 14] 2,167,808
# | └─Bottleneck: 2-28 [10, 1024, 14, 14] 2,167,808
# | └─Bottleneck: 2-29 [10, 1024, 14, 14] 2,167,808
# | └─Bottleneck: 2-30 [10, 1024, 14, 14] 2,167,808
# | └─Bottleneck: 2-31 [10, 1024, 14, 14] 2,167,808
# | └─Bottleneck: 2-32 [10, 1024, 14, 14] 2,167,808
# | └─Bottleneck: 2-33 [10, 1024, 14, 14] 2,167,808
# | └─Bottleneck: 2-34 [10, 1024, 14, 14] 2,167,808
# ├─Sequential: 1-5 [10, 2048, 7, 7] --
# | └─Bottleneck: 2-35 [10, 2048, 7, 7] 6,039,552
# | └─Bottleneck: 2-36 [10, 2048, 7, 7] 8,660,992
# | └─Bottleneck: 2-37 [10, 2048, 7, 7] 8,660,992
# ├─AdaptiveAvgPool2d: 1-6 [10, 2048, 1, 1] --
# ├─Linear: 1-7 [10, 1000] 2,049,000
# ==========================================================================================
# Total params: 76,981,288
# Trainable params: 76,981,288
# Non-trainable params: 0
# Total mult-adds (T): 2.98
# ==========================================================================================
# Input size (MB): 6.02
# Forward/backward pass size (MB): 128.53
# Params size (MB): 307.93
# Estimated Total Size (MB): 442.48
# ==========================================================================================
到这里,我们就已经复现了整个残差网络。这段代码可能是我们目前为止完成的逻辑最复杂的代码。就代码本身来看,我们还有非常多的优化空间,但代码的核心框架以及基本逻辑已经非常接近PyTorch源码中所呈现的内容。还有许多精巧的方法可以用在残差网络的实现上,我们可以将这段代码保存,日后不断继续完善和修改它。
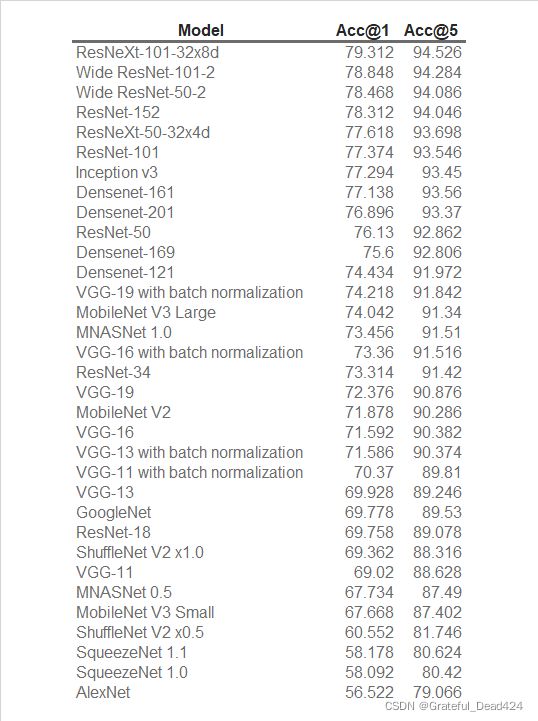
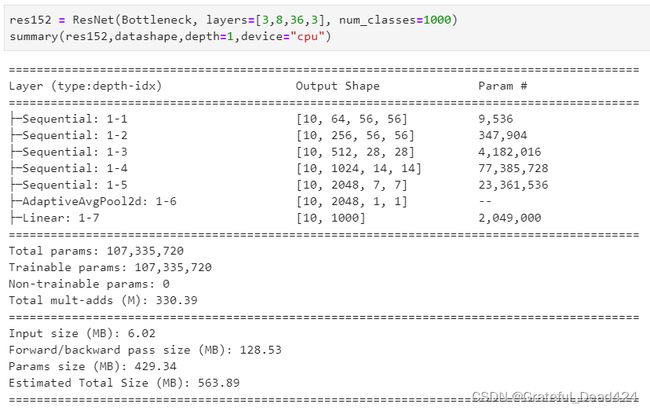
来看残差网络的模型大小和参数量。即便ResNet现在可以达到的深度非常深,但从参数和计算量的角度来看,它并不算是“巨型”的模型。34层的残差网络的参数量为2200万,152层的残差网络参数量也才刚刚过一个亿,比起VGG16和19超过1.4亿左右的参数,只能算是小巫见大巫。值得注意的是,残差网络的计算量很小,整体的mult-adds都在500MB以下,参数利用率高得令人惊奇。

从模型效果来看,残差网络毫无疑问是现有的最顶尖的模型之一,几乎所有大型数据集的跑分榜单前几名都是残差网络占据。除了我们已经学习的基本网络,残差网络还有许多有效、强大的变体,如ResNeXt(在残差网络上加入了并联结构),WideResNet(目前为止最强大的模型)等。同时,InceptionV4是结合了GoogLeNet与ResNet思路的强大架构,这些内容都非常值得一学。限于有限的篇幅,我们对于前沿网络的介绍不得不暂时止步于此,但还有非常多的内容可以供大家探索。在这里,我为大家提供ImageNet数据集上排名前列的架构名称(PyTorch官方提供),感兴趣的小伙伴可以顺着架构名称找到相关论文、持续学习(一个很好的参考:https://towardsdatascience.com/illustrated-10-cnn-architectures-95d78ace614d#b4ed)。在课程的下一部分,我们将把实现从具体的架构转向构建整个计算机视觉项目的流程。