视频分析模型(行为识别):C3D
C3D
文章目录
-
- C3D
-
- 1. 简介
-
- 1.1 背景
- 1.2 C3D特点
- 1.3 视频描述符
- 1.4 C3D的结果
- 2. 架构
-
- 2.1 工作流程
- 2.2 网络结构
- 2.3 3D卷积和池化
- 2.4 kernel 的时间深度
- 3. 可视化
-
- 3.1 特征图
- 3.2 特征嵌入
- 4. 应用场景
-
- 4.1 动作识别
- 4.2 动作相似度标注
- 4.3 场景和目标识别
- 4.4 运行时间分析
1. 简介
论文:https://arxiv.org/abs/1412.0767v4
github:
原代码:https://github.com/facebook/C3D
TensorFlow:https://github.com/hx173149/C3D-tensorflow
1.1 背景
卷积神经网络(CNN)被广泛应用于计算机视觉中,包括分类、检测、分割等任务。
这些任务一般都是针对图像进行的,使用的是二维卷积(即卷积核的维度为二维)。而对于基于视频分析的问题,2D convolution不能很好得捕获时序上的信息,因此3D卷积就被提出来了。
3D卷积 最早应该是在 《3D convolutional neural networks for human action recognition》 这片论文中被提出并用于行为识别的,而C3D是作为一个通用的网络提出的,论文中将其用于行为识别,场景识别,视频相似度分析等领域。
1.2 C3D特点
- 3D ConvNets比2D ConvNets更适用于时空特征的学习
- 对于3D ConvNet而言,在所有层使用3×3×3的小卷积核效果最好
- 通过简单的线性分类器学到的特征名为C3D(Convolutional 3D),在4个不同的任务和6个基准上表现优秀,在2015年达到SOTA
- 特征紧凑:在UCF101数据集上得到52.8%的准确率只用了10维(PCA+SVM)
- 推断快,计算效率非常高,在论文中实验时就有300帧以上的FPS,使用 NVIDIA 1080 GPU 能达到600帧以上
- 概念简单,易于训练和使用
1.3 视频描述符
一个有效的视频描述符有四个属性:
- 通用性。可以表示不同类型的视频,同时具有可区分性。例如,网络视频可以是自然风光、运动、电视节目、电影、宠物、食物等
- 描述符必须是紧凑的。由于我们需要处理数百万的视频,一个紧凑的描述符有助于处理,存储和检索任务,更具可扩展性;
- 计算高效。因为在现实世界中,每一分钟都需要处理成千上万的视频;
- 实现简单。不使用复杂的特征编码方法和分类器,一个好的描述符即使是一个简单的模型(如线性分类器)也能很好地工作。
而C3D是好的描述符:通用、紧凑、简单、高效。
C3D描述符,就是C3D网络第一个全连接层(fc6)输出的特征经过L2标准化后的结果。
1.4 C3D的结果
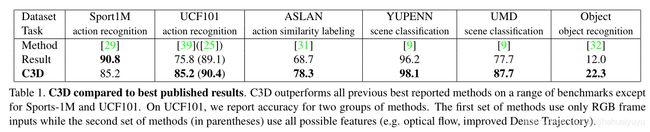
比较C3D与最好的公开结果。在一系列的基准上,C3D优于所有先前最好的报告方法,除了Sports-1M和UCF101。
在UCF101中,有2组方法:
- 只使用了RGB帧作为输入
- (括号里)使用了可能的特征(如:光流、改进的密集轨迹)
2. 架构
2.1 工作流程
数据集:Sports-1M
训练:
- 从每个训练视频中随机取出2秒长的5个片段,调整帧大小为128*171(大约为UCF-101一半分辨率)
- 随机裁剪成 16x112x112 的片段(shape:[ N, C, nframe, H, W ] -> [ N, 3, 16, 112, 112 ],16帧片段非重叠),形成抖动,以 50%的概率随机翻转
- 使用SGD优化器,batch size为30,初始学习率为0.003,每150K次迭代除以2,优化在1.9M迭代(约13epochs)停止
2.2 网络结构

基于不强的算力而设计的网络(C3D):8个卷积层、5个池化层、两个全连接层,以及一个softmax输出层
- 所有3D卷积核均为3×3×3(d x k x k ,d为时间深度),步长为1×1×1
- 为了在早期阶段保留更多的时间信息,设置pool1核大小为1×2×2、步长1×2×2(时间深度为1时,会单独在每帧上进行池化,大于1时,会在时间轴上,也就是多帧之间进行池化)
- 其余所有3D池化层均为2×2×2,步长为2×2×2
- 每个全连接层有4096个输出单元
2.3 3D卷积和池化
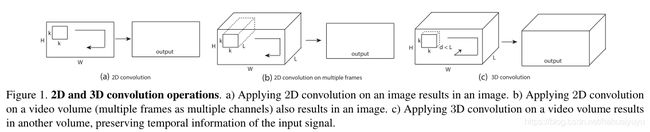
3D卷积和池化更适合学习时空特征,通过3D卷积和3D池化,可以对时间信息建模,而2D卷积只能在空间上学习特征。
2D卷积输入图像和视频时,输出的都是图像,而3D卷积输入视频后,输出的也是一个视频(3D特征图),保留了输入的时间信息。
C3D网络将完整的视频作为输入,不依赖于任何处理,可以轻松扩展到大数据集。
2.4 kernel 的时间深度
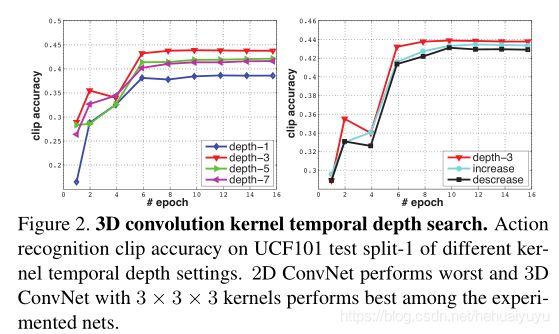
设计实验对比:
设置了4种固定尺寸的3D卷积核(左图),分别为1×3×3 、3×3×3、5x3x3、7x3x3,表明 3×3×3结果最优。
设置3种对比的网络结构,不同层的3D卷积核的时间深度分别为:
- 时间深度不变: 3−3−3−3−3
- 时间深度递增:3−3−5−5−7
- 时间深度递减:7−5−5−3−3
表明当卷积网络中所有的3D卷积核的时间深度一致,都为3×3×3时,效果最优。
综上:3x3x3 卷积核效果最优。
3. 可视化
3.1 特征图
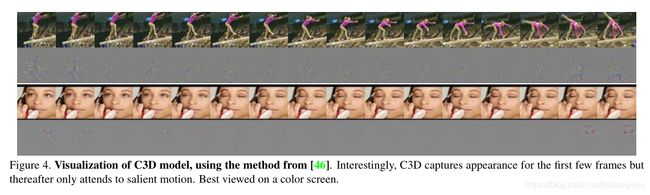
使用反卷积的方法来了解C3D内部的学习,上图为conv5b特征映射图的反卷积,最大的激活投射回图像空间的图像。
第一个例子中,特征集中在整个人身上,然后跟踪其余帧上撑杆跳表演的运动。
第二个例子中,它首先关注眼睛,然后在化妆的同时跟踪眼睛周围发生的运动。
也就是说,C3D在跟踪图像的外观特征,和视频中的运动特征,论文中有更多可视化的例子。
3.2 特征嵌入

这张图上,每一个clip为一个点,同一类别具有相同颜色。
通过从UCF-101中随机取100k个视频片段,再分别取ImageNet和C3D的特征提取片段的fc6特征,用 t-SNE 降维到2维空间进行可视化。
可以看到C3D的各类别之间更有区分度、更紧凑,并且这里没有做微调,表明其有良好的泛化能力。
4. 应用场景
4.1 动作识别
数据集:UCF-101
模型:使用C3D提取特征输入多类线性SVM
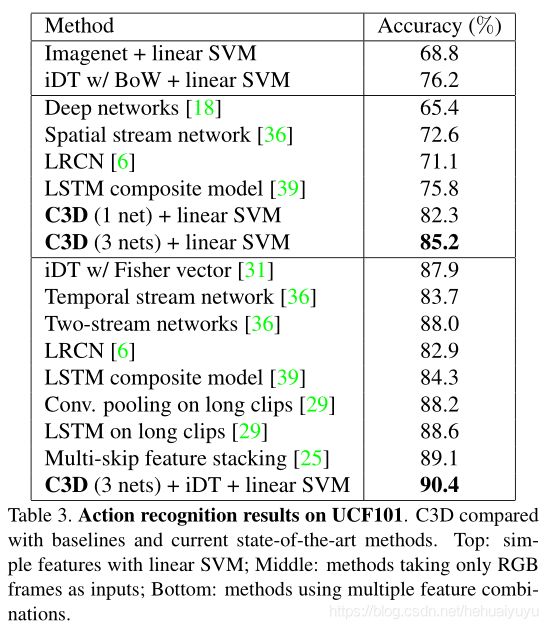
结果:C3D达到SOTA,表中为网络的一些组合和比较:
C3D (3 nets) + linear SVM 表示三组C3D的fc6同时并联,与SVM结合后能提高预测精度
4.2 动作相似度标注
动作相似度标注问题的任务是判断给出的两段视频是否属于相同的动作。
数据集:ASLAN(432个动作类的3,631个视频组成)
特征:将视频分为重叠8帧的16帧片段,提取每个片段的C3D特征,分别平均每个种类的片段特征,再L2归一化
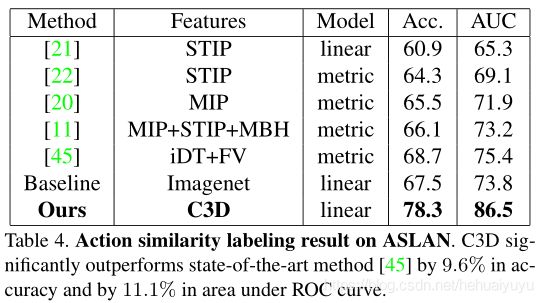
结果:在ASLAN上,C3D做到了SOTA,在ROC曲线(AUC)下显著优于最先进的方法
4.3 场景和目标识别
数据集:Maryland(14个场景类别的420个视频) 和 YUPENN(13个场景类别的130个视频)
模型:相同的特征提取体系和线性SVM进行分类
结果:同样优于其他方法,在当时做到SOTA

4.4 运行时间分析
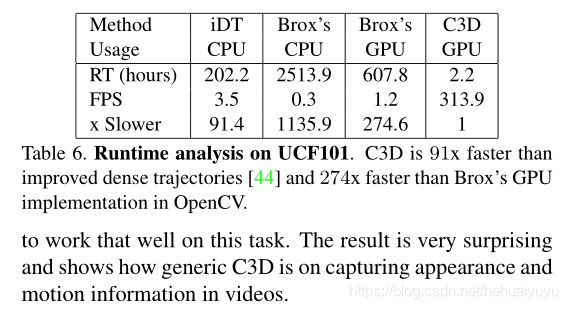
如表所示,在推理速度上,C3D显著优于其他算法,iDT是行为识别领域的非深度学习方法中效果最好的方法,Brox指Brox提出的光流计算方法。
表中C3D的速度应该是在视频帧无重叠的情况下获得的,在NVIDIA 1080 的GPU上,可以达到600帧以上的速度。