图像识别—极端天气下基于YOLOX的交通标志识别
摘要
随着机器学习和深度学习的兴起,近年来计算机视觉方向的交通标志识别精度和速度不断提高,但大多数文献和研究都是基于清晰通畅的。本文研究了雨雪天气、雾霾天气下以及车辆行驶速度过快等交通标志识别模糊的问题。新提出的YOLOX模型用于训练和测试数据集。最终的实验结果表明,使用YOLOX模型识别去模糊后的图片的准确率有所提高,优于其他模型,但图像类型不够丰富。与真实交通场景的相似度有待提高。
1 引言
安全交通一直是大家关心的热点问题,交通标志识别作为安全交通的保障被提出。近年来,关于交通标志识别的研究论文层出不穷。2019年Cao,JW [l]等提出一种改进的智能汽车交通标志检测与识别算法;2021 Zhou, k[2]等提出的基于区域注意力网络学习的交通标志识别;2022 Zhu, YZ[3]等提出了基于深度学习的交通标志识别。但是,交通标志识别的研究是基于自然天气,准确率已经达到很高的水平,不容易继续提高。事实上,关于特殊情况下的交通标志已经有很多论文了。Deng Xy[4] 针对许多交通标志因老化而变形或失真的问题,提出了一种提升交通标志边缘特征的方法,解决了交通标志变形的问题,实现了高效识别。W. Min[5]等人针对现有方法侧重于提取交通标志特征,而忽略了交通标志与场景中其他物体空间关系的约束,提出了一种基于语义场景理解和结构交通标志定位的交通标志识别方法,测试正确率达到99。对德国交通标志检测基准数据集进行了90%的检测,优于其他方法。Cao J[6]等人针对传统交通标志检测易受环境影响、基于深度学习的交通标志识别方法实时性差的问题,提出了一种改进的智能车辆交通标志检测识别算法。准确率和实时性显著提高,泛化能力强,训练效率高,准确识别率和平均处理时间显著提高。本文所做的实验是针对极端天气下的交通标志识别,即拍摄的照片由于天气原因或车速过快而模糊时的交通标志识别。
2 数据集来源和处理
本文使用的数据集来自论文[7],利用10万张腾讯街景全景图创建大尺度交通标志库。这个基准是清华腾讯100K (TT100K)。在提供的10万张图片中,有3万张包含交通标志。对其中的交通标志进行分类,并对每幅图像的交通标志进行标注,给出边界框和标志类别。
A.数据集混淆
由于本文实验针对的是极端天气,因此首先通过调用opencv2、numpy和os模块对数据集进行模糊处理,生成任意角度的运动模糊核矩阵,其中设置参数degree。数值越大,图像越模糊。在本实验中,对单幅图像进行参数设置后,观察模糊程度,最后设置degree= 13,最后对所有数据集进行批量处理。图1显示了模糊处理前后的对比。

图1 模糊前后对比。
B.数据集分类过滤
由于原始数据集中类别太多,本文采用过滤掉一些出现频率较低的交通标志来提高训练速度和准确率。如图2所示,本次实验所选择的类别是被正确标注的类别所占数量,虽然有一些类别数量较少,但由于与数据量较大的类型数据进行比较,保留了一些出现次数较少的类别。
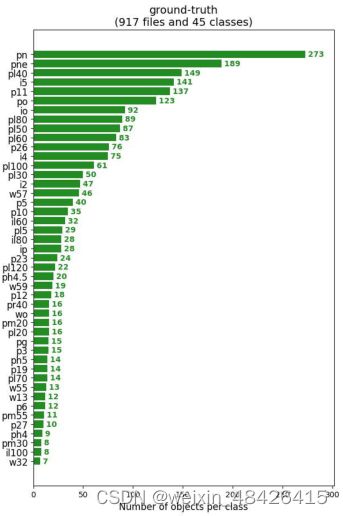
图2 每一类真实值的比例
3 实验结果和分析
A YOLOX方法简介
YOLOX是由Zheng Ge[8]等人在2021年7月提出的,对YOLO系列进行了一些有经验的更新,它形成了一种高性能的无锚探测器YOLOX,YOLOX配备了一些最新的先进检测技术,即走耦合头,无锚和先进的标签分配策略,它在速度和精度之间实现了比其他同类产品在所有型号都高。YOLOX方法除了使用CSPDarknet53特征提取结构外,还增加了一个特征图金字塔网络FPN (feature pyramid Networks)层。采用FPN层作为YoloX的增强特征提取网络,如图3所示。YOLOX的网络结构图,从图中可以看出,YOLOX在特征利用部分提取了多个特征层用于目标检测,共提取了三个特征层。如图所示,三个特征层分别位于中间层、中下层和底层的不同位置,分别命名为featurerel、feature2和feature3。在获得三个有效特征层后,使用这三个有效特征层。构建FPN层。
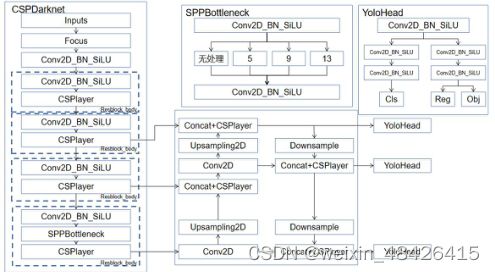
图3。YOLOX网络结构图。
B 实验流程
由于YOLOX采用了马赛克和Mixup数据增强方法,如图4所示是马赛克实现的思想。 从图中可以看出,每次读取四张图片,并对四张图片进行翻转、缩放和色域。更改和其他操作,并将它们放置在图中第二列的左上、右上、左下和右下位置。完成四张图片的放置后,使用矩阵法截取四张图片的固定区域。然后将它们拼接成一个新的图像,新的图像包含一系列的盒子等内容,即图中最右边的合成图像。最后,将整个合成图像作为图像输入,然后执行下一步。

图4。马赛克实现思想图。
当图片传输到网络时,首先调整为416* 416的尺寸。为了防止失真,我们会在图像边缘加一条灰色条,然后yolov将图像分成13* 13,26 * 26,52 *52,由于图像经过多次卷积压缩后,小物体的特征容易消失,所以使用52*52的网格来检测小物体,使用13*13的网格来检测大物体。在本次实验中,如图4.4所示,识别出的交通标志为小物体,因此使用52*52网格。
C 结果分析
在分析实验结果之前,我们先来了解一下mAP、AP、f1评分、recall等的具体含义。
TP (True Positives):图片被预测为正样本,最终的预测结果也是正样本。按照惯例,在检测一张图片时,如果IOU(交并比)>为0.5,则认为检测结果为阳性样本。所以这个实验中引用的指数是0.5。
FP (False Positives):将图像预测为正样本,最终的预测结果也是一个错误的样本,即将一个负样本预测为正样本。该指标反映误检率。在实验中,指标越低越好。
FN(假阴性):预测结果为阴性样本,但预测结果错误,即本应检测的阳性样本未被检测为阴性样本。该指标反映漏检率。指标越小越好。
TN (True Negative):预测结果正确,即将该反面例作为反面例进行预测。
精度:表示预测的阳性样本中有多少是真阳性样本。对于预测结果,就是要找出结果中的阳性样本。计算公式如下:

召回率(Recall):表示样本中有多少正例被预测是正确的。计算公式如下:

AP:平均不同召回点的精度(即PR曲线下的面积)。PR曲线是Precision和recall组成的曲线。计算公式如下:

mAP (Mean Average Precision):即分别取出每个类别的AP,然后计算所有类别AP的平均值,这代表了对被检测目标的平均精度的综合考虑。计算公式如下:

图5为本次实验得到的各类mAP图。从图中我们可以看到,虽然所有类别的平均mAP值只有60.13%,但我们可以看到,类别数量较多的类别的准确率高于图2。它比数量少的分类效果更好,所以我们可以推想mAP值低是因为它的数量少。

图5 每个类别的mAP图。
我们选取效果较好的pne类,如图6和图7所示,分别为pne类的准确率和召回率。从图中可以看出,效果还是很好的。
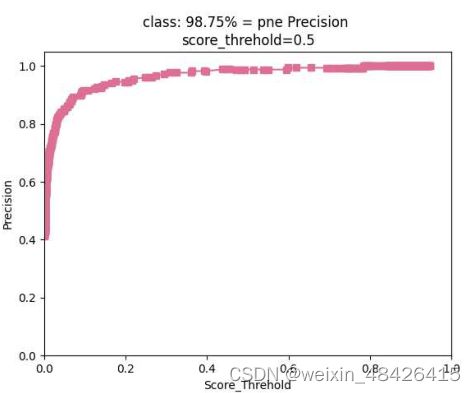
图6 分类png的准确性。
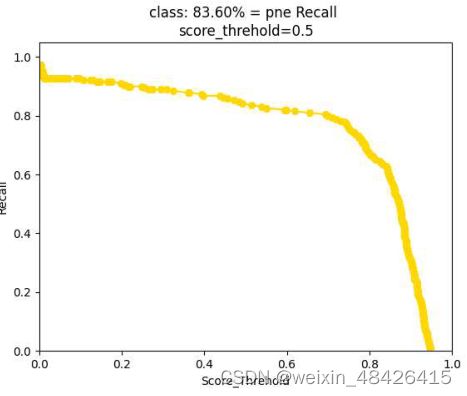
图7 召回类别png。

图8 召回类别w32。

图9 w32类精度。
取类别较少的w32类数据图,如图8和图9所示,我们将数据与pne类进行对比,发现由于pne的每张图中类别较多,所记录的数据图也相对完整,其中召回率随着置信度的不断增加,以置信度越高为标准,召回值会降低,因为召回率代表的是真阳性与真阳性和假阴性之和的比率。同时,被判断为真实的样本会越来越少,基数保持不变,因此召回率越来越低,但平均召回率达到88.89%。召回值越大,预测过程中阴性样本的比例越小,这意味着当模型识别该类别时,准确率较高。在w32的召回图中,由于样本较少,在识别过程中,该类别中存在的数据集不足以训练模型,因此召回值很低。类似地,分析准确率图表。通过对这两个类别的比较分析,我们加强了之前的推论。
4 结论
通过分析本文的实验结果,我们得出以下结论。即通过训练数据集中图片的数量来提高识别的准确率,在特定条件下,模型识别交通标志的准确率可以达到98.75%。同时,对精度较低的图像进行去模糊处理,可以提高识别精度。我们希望训练后的模型能够接近真实的交通场景,处理超速或极端天气导致的交通标志识别,从而提高汽车的安全系数。目前,图片场景的真实性还有待提高,因此本文的研究方向仍有很大的发展空间。