曹健老师 TensorFlow2.1 —— 第二章 神经网络优化
第一章
本章目的:学会神经网络优化过程,使用正则化减少过拟合,使用优化器更新网络参数。
2.1 预备知识
- tf.where(条件语句, 真返回A, 假返回B)
a = tf.constant([1,2,3,1,1])
b = tf.constant([0,2,3,4,5])
c = tf.where(tf.greater(a, b), a, b)
# 若 a>b ,返回 a 对应位置的元素,否则返回 b 对应位置的元素- np.random.RandomState.rand(维度) 返回一个 [0, 1) 之间的随机值,维度为空,返回标量
import numpy as np
rdm = np.random.RandomState(seed=1) # seed=常数 每次生成随机数相同 老师教学方便
a = rdm.rand() # 返回一个随机标量
b = rdm.rand(2,3) # 返回维度为 2 行 3 列随机数矩阵- np.vstack(数组1, 数组2),将两个数组按垂直方向叠加
a = np.array([1,2,3])
b = np.array([4,5,6])
c = np.vstack((a,b))- np.mgrid[起始值: 结束值: 步长, 起始值: 结束值: 步长, ... ...] ,返回若干组维度相同的等差数组(行数由 start1:end1:step1 决定,列数由 start2:end2:step2决定) [ 起始值, 结束值 )
x, y = np.mgrid[1:3:1, 2:4:0.5]
print(x, y)
# 输出结果
[[1. 1. 1. 1.]
[2. 2. 2. 2.]]
[[2. 2.5 3. 3.5]
[2. 2.5 3. 3.5]]
# x 是网格的第一维,会向第二维方向扩展
# y 是网格的第二维,会向第一维方向扩展
# 遵循 numpy 的广播机制- x.ravel() 将 x 变为一维数组,“把 x 拉直”
- np.c_[ 数组1 , 数组2 , ... ...] ,使返回的间隔数值点配对
- 以上三个函数经常一起使用,可以生成网格坐标点
x, y = np.mgrid[1:3:1, 2:4:0.5]
grid = np.c_[x.ravel(), y.ravel()]
2.2 复杂度、学习率
NN(Neural Network) 复杂度:多用 NN 层数和 NN 参数的个数表示
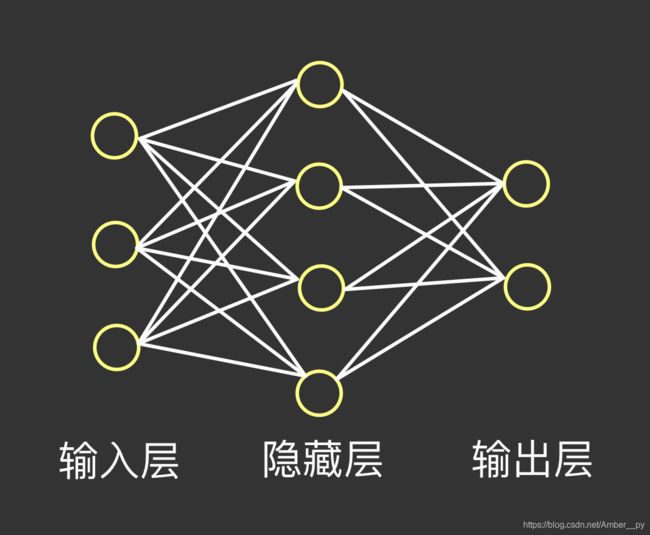
如上图所示:
- 空间复杂度:
(1)层数 = 隐藏层层数 + 1 个输出层 ( 只统计具有运算能力的层 )( 上图为 2 层 NN,一个隐藏层,一个输出层 )
(2)总参数 = 总 w + 总 b (上图第一层:3 * 4 + 4 ,第二层:4 * 2 + 2,sum = 26)
- 时间复杂度:
乘加运算的次数(上图第一层:3 * 4 ,第二层:4 * 2 ,sum = 20)
学习率( lr )
 是更新后的参数,
是更新后的参数,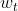 是当前参数,lr 是学习率,
是当前参数,lr 是学习率,![]() 是损失函数的梯度(偏导数)
是损失函数的梯度(偏导数)
- 训练时如何选择学习率:可以先用较大的学习率,快速得到较优解,然后逐步减小学习率,使模型在训练后期稳定。
- 指数衰减学习率 = 初始学习率 * 学习率衰减率^( 当前轮数 / 多少轮衰减一次 ) 。当前轮数是个计数器变量,可以用当前迭代了多少次数据集即 epoch 的值表示,也可以用当前一共迭代了多少次 batch 即 global_step 表示;多少轮衰减一次是迭代多少次数据集或者迭代多少次 batch 更新一次学习率,决定了学习率更新的频率。
# 在 backpropagation 基础上
EPOCH = 40
# 添加了下面三个超参数
LR_BASE = 0.2
LR_DECAY = 0.99
LR_STEP = 1
for epoch in range(EPOCH):
# 添加了下面这一个计算公式
lr = LR_BASE * LR_DECAY ** ( epoch / LR_STEP )
with tf.GradientTape() as tape:
loss = tf.square(w + 1)
grads = tape.gradient(loss, w)
w.assign_sub(lr * grads)
print("After %s epoch, w is %f, loss is %f, lr is %f" % (epoch, w.numpy(), loss, lr))2.3 激活函数
什么是激活函数以及为什么要使用激活函数 —— 百度百科
激活函数讲解参考:https://blog.csdn.net/tyhj_sf/article/details/79932893
神经网络具备两个特点,一是多输入,单输出;另一是阈值工作,达到一定的值才会触发,激活函数相当于不同的阈值,可以想象成不同型号的阀门。
期望激活函数具备恒等性,用来弥补线性函数的不足。
- Sigmoid 函数 tf.nn.sigmoid(x)

深层神经网络更新参数时,要从输出层到输入层逐层进行链式求导,而 Sigmoid 函数的导数输出的是(0,0.25)之间的小数,链式求导需要多层导数连续相乘,多个小数连乘会导致结果趋近于 0 ,导致参数无法继续更新,即梯度消失。
特点:
(1)易造成梯度消失
(2)输出为非 0 均值,收敛慢
(3)幂运算复杂,训练时间长
- Tanh 函数 tf.math.tanh(x)
![]()
特点:
(1)输出是 0 均值
(2)易造成梯度消失
(3)幂运算复杂,训练时间长
- Relu 函数 tf.nn.relu(x)
![]()
优点:
(1)在正区间内解决了梯度消失问题
(2)只需判断输入是否大于 0 ,计算速度快
(3)收敛速度远大于 Sigmoid 和 Tanh
缺点:
(1)输出非 0 均值,收敛慢
(2)Dead Relu 问题:送入激活函数是负数时,输出为 0 ,反向传播得到的梯度是 0 ,导致参数无法更新。即某些神经元可能永远不会被激活,导致相应的参数永远不能被更新。
可以改进随机初始化,避免过多的负数特征送进 Relu 函数,可以通过设置更小的学习率,减小参数分布的巨大变化,避免训练中产生过多负数特征进入 Relu 函数
-
Leaky Relu 函数 tf.nn.leaky_relu(x)
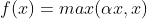
是为解决 Relu 负区间为 0 引起神经元死亡问题而设计的。
-
建议:
(1)首选 Relu 函数
(2)学习率设置较小值
(3)输入特征标准化,即让输入特征满足以 0 为均值,1 为标准差的正态分布
(4)初始参数中心化,即让随机生成的参数满足以 0 为均值,以 (2 / 当前输入特征个数) ^ (1/2) 为标准差的正态分布
2.4 损失函数
预测值 y 与已知答案 y_ 的差距.
NN 的优化目标是:loss 最小 ,三种计算方式
( 1 ) mse ( Mean Squared Error,均方误差 ) ![]()
loss_mse = tf.reduce_mean( tf.square ( y_ - y ))with tf.GradientTape() as tape:
y = tf.matmul(x, w1)
loss_mse = tf.reduce_mean(tf.square(y_ - y))
grads = tape.gradient(loss_mse, w1)
w1.assign_sub(lr * grads)( 2 ) 自定义
![]()
![]()
拿预测牛奶销量的例子,损失函数可以自定义为以上,当预测的 y 少了,不够卖了,损失利润 ( PROFIT ),预测的 y 多了,卖不出去,损失成本 ( COST )
loss_zdy = rf.reduce_sum(tf.where(tf.greater(y, y_),COST(y - y_),PROFIT(y_ - y)))( 3 ) ce ( Cross Entropy,交叉熵 ): 表征两个概率分布之间的距离,交叉熵越小,两个概率值分布越近.
![]()
tf.losses.categorical_crossentropy(y_, y)在执行分类问题时,通常先用 softmax 函数让输出结果符合概率分布,再求交叉熵损失函数,tensorflow 给出了一个可以同时将计算概率分布和交叉熵的函数:
tf.nn.softmax_cross_entropy_with_logits(y_, y)2.5 欠拟合与过拟合
欠拟合是模型不能有效拟合数据集,是对现有数据集学习地不够彻底;过拟合是模型对当前数据拟合的太好,但面对从未见过的新数据,却难以做出正确的判断,模型缺乏泛化力.
- 缓解欠拟合:
增加输入特征项
增加网络参数 ( 扩展网络规模,增加网络深度... )
减少正则化参数
- 缓解过拟合:
数据清洗 ( 减少数据集中的噪声 )
增大训练集
采用正则化
增大正则化参数
正则化缓解过拟合:正则化在损失函数中引入了模型复杂度指标,利用给 W 加权值,弱化了训练数据的噪声 ( 一般不正则化 b )
![]()
其中,loss ( y , y_ ) 是模型中所有参数的损失函数,如交叉熵、均方误差等;超参数 REGULARIZER 给出参数 w 在 loss 中的比例,即正则化的权重,loss ( w ) 中的 w 是需要正则化的参数,loss ( w ) 可以使用两种方式计算:
![]() ——— L1 正则化;
——— L1 正则化;![]() ——— L2 正则化.
——— L2 正则化.
- L1 正则化:大概率会使很多参数变为 0 ,因此该方法可通过稀疏参数,即减少参数的数量, 降低复杂度;
- L2 正则化:会使参数很接近 0 但不为 0 ,因此该方法看通过减小参数值的大小降低复杂度.
loss_mse = tf.reduce_mean(tf.square(y_train - y))
# 使用 L2 正则化
loss_regularization = []
loss_regularization.append(tf.nn.l2_loss(w1))
loss_regularization.append(tf.nn.l1_loss(w2))
# 这里假设神经网络是两层的
loss_regularization = tf.reduce_sum(loss_regularization)
loss = loss_mse + 0.03 * loss_regularization # REGULARIZATION = 0.032.7 优化器更新网络参数
优化器是引导神经网络更新参数的工具,本质是对 loss 函数求偏导,然后用偏导更新参数 w 和 b.
待优化参数 w,损失函数 loss,学习率 lr,每次迭代一个 batch ( 通常为 2^n ),t 表示当前 batch 迭代的总次数,更新参数分为四步:
1. 计算 t 时刻损失函数关于当前参数的梯度 ![]()
2. 计算 t 时刻一阶动量  和二阶动量
和二阶动量 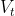 ,一阶动量是与梯度相关的函数,二阶动量是与梯度平方相关的函数.
,一阶动量是与梯度相关的函数,二阶动量是与梯度平方相关的函数.
# 不同的优化器实质上只是定义了不同的一阶动量和二阶动量公式.
# 动量:momentum,可以理解为梯度更新的时候是有惯性的,动量就表示了前面时刻梯度对当前梯度的影响.
3. 计算 t 时刻下降梯度:![]()
4. 计算 t+1 时刻参数:![]()
常用优化器:
- 随机梯度下降 ( SGD ,不含 momentum )
![]()
![]()
# 对于单层网络
w1.assign_sub(lr * grads[0])
b1.assign_sub(lr * grads[1])- SGD ( 含 momentum 的SGD ),在 SGD 的基础上增加一阶动量
![]()
这一公式表示各时刻梯度方向的指数滑动平均值, 是个超参数,接近于 1,经验值是 0.9 .
是个超参数,接近于 1,经验值是 0.9 .
m_w, m_b = 0, 0 # 第 0 时刻的一阶动量是 0
beta = 0.9
# sgd-momentun
m_w = beta * m_w + (1 - beta) * grads[0] # grads[] 当前时刻的梯度
m_b = beta * m_b + (1 - beta) * grads[1]
w1.assign_sub(lr * m_w)
b1.assign_sub(lr * m_b)- Adagrad ,在 SGD 基础上增加二阶动量 ( 可以对模型中的每个参数分配自适应学习率 )
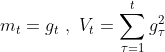 ( 二阶动量是从开始到现在梯度平方的累积和 )
( 二阶动量是从开始到现在梯度平方的累积和 )
v_w, v_b = 0, 0
# Adagrad
v_w += tf.square(grads[0])
v_b += tf.square(grads[1])
w1.assign_sub(lr * grads[0] / tf.sqrt(v_w))
b1.assign_sub(lr * grads[1] / tf.sqrt(v_b))- RMSProp,在 SGD 基础上增加二阶动量
![]() ( 二阶动量使用指数滑动平均值计算,表征过去一段时间的平均值 )
( 二阶动量使用指数滑动平均值计算,表征过去一段时间的平均值 )
v_w, v_b = 0, 0
beta = 0.9
# RMSProp
v_w = beta * v_w + (1 - beta) * tf.square(grads[0]) # grads[] 当前时刻的梯度
m_b = beta * m_b + (1 - beta) * tf.square(grads[1])
w1.assign_sub(lr * grads[0] / tf.sqrt(v_w))
b1.assign_sub(lr * grads[1] / tf.sqrt(v_b))- Adam,同时结合 SGDM 一阶动量和 RMSProp 二阶动量,并在此基础上增加了两个修正项:
![]() ,修正一阶动量的偏差:
,修正一阶动量的偏差:![]()
![]() ,修正二阶动量的偏差:
,修正二阶动量的偏差:![]()
m_w, m_b = 0, 0
v_w, v_b = 0, 0
beta1, beta2 = 0.9, 0.999
delta_w, delta_b = 0, 0
global_step = 0
# Adam
m_w = beta1 * m_w + (1 - beta1) * grads[0]
m_b = beta1 * m_b + (1 - beta1) * grads[1]
v_w = beta2 * v_w + (1 - beta2) * tf.square(grads[0])
v_b = beta2 * v_b + (1 - beta2) * tf.square(grads[1])
m_w_correction = m_w / (1 - tf.pow(beta1, int(global_step))) # global_step 是从训练开始到当前时刻所经历的总 batch 数 global_step 需要自加 1
m_b_correction = m_b / (1 - tf.pow(beta1, int(global_step)))
v_w_correction = v_w / (1 - tf.pow(beta2, int(global_step)))
v_b_correction = v_b / (1 - tf.pow(beta2, int(global_step)))
w1.assign_sub(lr * m_w_correction / tf.sqrt(v_w_correction))
b1.assign_sub(lr * m_b_correction / tf.sqrt(v_b_correction))