Tensorflow 自然语言处理
文章目录
- 前言
- 基本知识
-
- 使用API
- Text to sequences
- Padding
- 新闻标题数据集用于讽刺检测
前言
基本知识
使用API
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.preprocessing.text import Tokenizer
sentenses=[
'I love my dog',
'I love my cat',
'You love my dog!'
]
tokenizer=Tokenizer(num_words=100)
tokenizer.fit_on_texts(sentenses) # take in the data and encodes it
word_index=tokenizer.word_index # key:word index:the token of the word
print(word_index)
打印结果:
{'love': 1, 'my': 2, 'i': 3, 'dog': 4, 'cat': 5, 'you': 6}
- num_words:需要保留的最大词数,基于词频。只有最常出现的
num_words词会被保留。(unique word) 详情 - tokenizer.fit_on_texts():分词器方法,实现分词
tokenizer会为您自动除去标点符号(punctutation),感叹号(exclamation)并未出现在word_index中。并且大写会自动改成小写。
Text to sequences
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.preprocessing.text import Tokenizer
sentenses=[
'I love my dog',
'I love my cat',
'You love my dog!',
'Do you think my dog is amazing?'
]
tokenizer=Tokenizer(num_words=100)
tokenizer.fit_on_texts(sentenses) # take in the data and encodes it
word_index=tokenizer.word_index # key:word index:the token of the word
sequences=tokenizer.texts_to_sequences(sentenses)
print(word_index)
print(sequences)
打印结果:
{'my': 1, 'love': 2, 'dog': 3, 'i': 4, 'you': 5, 'cat': 6, 'do': 7, 'think': 8, 'is': 9, 'amazing': 10}
[[4, 2, 1, 3], [4, 2, 1, 6], [5, 2, 1, 3], [7, 5, 8, 1, 3, 9, 10]]
在上面那段代码的后面加上:
test_data=[
'I really love my dog',
'my dog loves my manatee'
]
test_seq=tokenizer.texts_to_sequences(test_data)
print(test_seq)
打印结果:
[[4, 2, 1, 3], [1, 3, 1]]
结论:我们需要训练很多数据,否则可能就会像上面一样得出my dog my,或者遗失really的句子。
如果我们用一个特殊标识来代表不认识的单词而不是忽略它,结果又会怎么样呢?
修改tokenizer:tokenizer=Tokenizer(num_words=100,oov_token="
打印结果:
{'' : 1, 'my': 2, 'love': 3, 'dog': 4, 'i': 5, 'you': 6, 'cat': 7, 'do': 8, 'think': 9, 'is': 10, 'amazing': 11}
[[5, 1, 3, 2, 4], [2, 4, 1, 2, 1]]
Padding
sequences=tokenizer.texts_to_sequences(sentenses)
padded1=pad_sequences(sequences)
padded2=pad_sequences(sequences,padding='post')
padded3=pad_sequences(sequences,padding='post',maxlen=5)
print(padded1)
print(padded2)
print(padded3)
输出结果:
[[ 0 0 0 5 3 2 4]
[ 0 0 0 5 3 2 7]
[ 0 0 0 6 3 2 4]
[ 8 6 9 2 4 10 11]]
[[ 5 3 2 4 0 0 0]
[ 5 3 2 7 0 0 0]
[ 6 3 2 4 0 0 0]
[ 8 6 9 2 4 10 11]]
[[ 5 3 2 4 0]
[ 5 3 2 7 0]
[ 6 3 2 4 0]
[ 9 2 4 10 11]]
-
pad_sequences:将多个序列截断或补齐为相同长度。详情
-
padding:字符串,‘pre’ 或 ‘post’ ,在序列的前端补齐还是在后端补齐。
-
maxlen:整数,所有序列的最大长度。
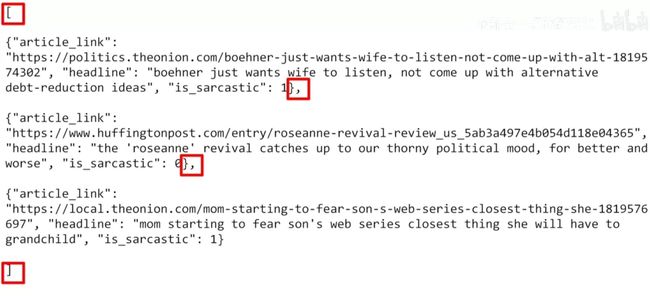
新闻标题数据集用于讽刺检测
数据集:CCO public domain dataset:sarcasm detection(嘲讽检测)
新闻标题数据集用于讽刺检测:News Headlines Dataset For Sarcasm Detection
Each record consists of three attributes:
is_sarcastic: 1 if the record is sarcastic otherwise 0headline: the headline of the news articlearticle_link: link to the original news article. Useful for collecting supplementary data
注意:Laurence为了方便把数据集稍作修改了
import json
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
with open('sarcasm.json','r') as f:
datastore=json.load(f) # 返回一个包含三种数据的列表
sentences = []
labels = []
urls = []
for item in datastore:
sentences.append(item['headline'])
labels.append(item['is_sarcastic'])
urls.append(item['article_link'])
tokenizer=Tokenizer(oov_token="" )
tokenizer.fit_on_texts(sentences)
word_index=tokenizer.word_index
sequences=tokenizer.texts_to_sequences(sentences)
padded=pad_sequences(sequences,padding='post')
print(padded[0])
print(padded.shape)
打印结果:
[ 308 15115 679 3337 2298 48 382 2576 15116 6 2577 8434
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0]
(26709, 40)
共有26709个不重复的单词,最长的标题有40个单词。这些单词按照词频从高到低排序。