手撕self-attention代码_从0实现self-attention_附学习路线
一、前言
科研需要,前几天自学了transformer。在理解self-attention时,发现网上并没有一套成熟易懂的学习路线,对新手及其不友好。大多数教程只重视理论和公式的讲解,没有从零开始的代码实战。因此,我在这里整理了一条最适合新手的权威学习路线和配套的self-attention代码练习。话不多说,上正文。
二、self-attention学习方法
关于self-attention的学习直接推荐大家观看台湾大学李毅宏教授的课。对于新知识接收度低的同学不要去看其它的学习博客和视频,直接师从权威,绝对没错。
学习地址链接:
https://www.bilibili.com/video/BV1Xp4y1b7ih?p=1&vd_source=83bc2b3b7dfc04b2f755b5b425167e2d
对应ppt获取链接:
https://speech.ee.ntu.edu.tw/~hylee/ml/ml2021-course-data/self_v7.pdf
三、手撕self-attenton代码
李教授的课将的非常生动,但是没有配套的底代码练习(虽然这个课有对应的课后作业,但内容基本都是调包,做完后没啥深刻的印象)。对于算法来讲,理解它最好的方式就是手动从0实现。下面我将用两种方法教大家实现self-attention。
3.1 利用numpy实现self-attention的计算过程
本节仅使用numpy从底层模拟self-attention的矩阵计算过程,对应为李宏毅教授视频讲解时的QKV矩阵化后的计算流程。
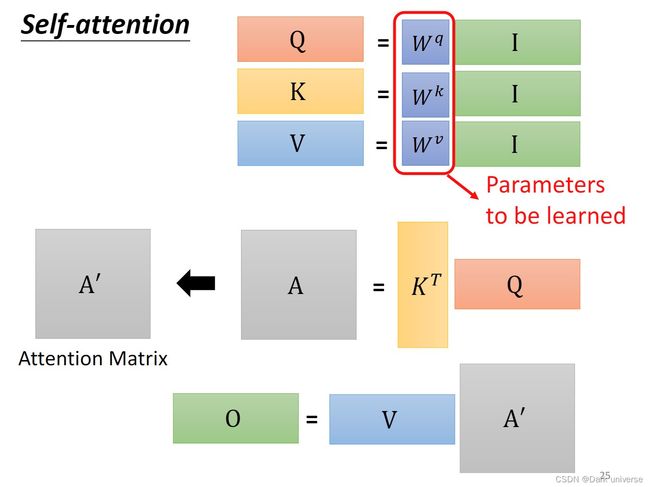
大家可以看完这里停下来自己手动码一遍下面下面的程序,有助于加深记忆。
import numpy as np
from numpy.random import randn
#1、定义输入数据a
#a表示有32个向量的输入数据,每个向量是一个256维的列向量
d = 256
n = 32
a = np.random.rand(d,n) #(256, 32)
#2、计算数据数据对应的Q,K,V
Wq = np.random.rand(d,d)
Wk = np.random.rand(d,d)
Wv = np.random.rand(d,d)
#输入a是32*256的
#wq是256*256的
Q = np.dot(Wq,a) #(256, 32)
K = np.dot(Wk,a)
V = np.dot(Wv,a)
#2、计算数据数据对应的Q,K,V
Wq = np.random.rand(d,d)
Wk = np.random.rand(d,d)
Wv = np.random.rand(d,d)
#3、计算注意力得分score,记为:A
#计算公式为;A = softmax(K^T*Q)
#定义sofmax函数
def soft_max(z):
z = np.clip(z,100,-100) #归一化至[-100,100],防止softmax时数据溢出
t = np.exp(z)
res = np.exp(z) / np.sum(t, axis=1)
return res
A = soft_max(np.dot(K.T,Q)) #(32, 32)
#4、计算self-attention的输出数据:O
# O = V * A
# O的维数和输入数据a保持一致
O = np.dot(V,A) #(256, 32)
3.2 利用pytorch实现self-attention的计算过程
相较于仅依靠numpy模拟QKV的计算过程,基于torch的self-attention实现更具有实际应用价值,也更贴合实战。
#基于pytorch的self-attention
import math
import torch
import torch.nn as nn
class SelfAttention(nn.Module):
def __init__(self,dim_input, dim_q, dim_v):
'''
参数说明:
dim_input: 输入数据x中每一个样本的向量维度
dim_q: Q矩阵的列向维度, 在运算时dim_q要和dim_k保持一致;
因为需要进行: K^T*Q运算, 结果为:[dim_input, dim_input]方阵
dim_v: V矩阵的列项维度,维度数决定了输出数据attention的列向维度
'''
super(SelfAttention,self).__init__()
#dim_k = dim_q
self.dim_input = dim_input
self.dim_q = dim_q
self.dim_k = dim_q
self.dim_v = dim_v
#定义线性变换函数
self.linear_q = nn.Linear(self.dim_input, self.dim_q, bias=False)
self.linear_k = nn.Linear(self.dim_input, self.dim_k, bias=False)
self.linear_v = nn.Linear(self.dim_input, self.dim_v, bias=False)
self._norm_fact = 1 / math.sqrt(self.dim_k)
def forward(self,x):
batch, n, dim_q = x.shape
q = self.linear_q(x) # Q: batch_size * seq_len * dim_k
k = self.linear_k(x) # K: batch_size * seq_len * dim_k
v = self.linear_v(x) # V: batch_size * seq_len * dim_v
print(f'x.shape:{x.shape} \n Q.shape:{q.shape} \n K.shape: {k.shape} \n V.shape:{v.shape}')
#K^T*Q
dist = torch.bmm(q, k.transpose(1, 2)) * self._norm_fact
#归一化获得attention的相关系数:A
dist = torch.softmax(dist, dim=-1)
print('attention matrix: ', dist.shape)
#socre与v相乘,获得最终的输出
att = torch.bmm(dist, v)
print('attention output: ',att.shape)
return att
if __name__ == '__main__':
batch_size = 2 #批量数
dim_input = 5 #句子中每个单词的向量维度,也就是每个最小样本x的维度
seq_len = 3 #句子的长度,样本的数量
x = torch.randn(batch_size, seq_len, dim_input)
self_attention = SelfAttention(dim_input, 10, 12)
print(x)
print('=' * 50)
attention = self_attention(x)
print('=' * 50)
print(attention)