WaveCRN: An Efficient Convolutional RecurrentNeural Network for End-to-end SpeechEnhancement
[arXiv:2004.04098v2]
Motivation
1、在建模时应该有效地考虑语音的局部性和时间序列特性。目前大多数端对端的语音增强模型要不然没有充分考虑语音的局部性和时间序列特性,要不然过于复杂难以实现,因此提出了一个有效的端对端语音增强模型,称WaveCRN。WaveCRN使用CNN模块和堆叠简单递归单元(SRU)模块来捕获语音位置特征,并对位置特征的时序特性进行建模。与传统的递归神经网络和LSTM不同,SRU在计算中可以高效并行化,模型参数更少。
2、为了更有效地抑制带噪语音中的噪声成分,提出了一种新的受限特征掩蔽方法(RMF),该方法对隐藏层中的特征映射进行增强;
Method
提出WaveCRN的语音增强系统。该体系结构是一个完全可微分的端到端神经网络,不需要预处理和人工特征。

图1 提出的wavecrn模型的体系结构。
与频谱CRN不同,WaveCRN集成了一维CNN和双向SRU。
A 1维卷积输入模块
B 时序编码
我们使用双向SRU(Bi-SRU)来捕获由输入模块在两个方向提取的特征图的时间相关性。
C 受限特征mask
采用受限特征掩模(RFM)对特征映射F进行掩模,所有元素的范围为-1 ~ 1
F′=M∘F
其中M,是RFM,F'是通过将mask M和特征图F逐元素相乘估计出来的masked特征图。
D 波形生成
由于卷积过程中的步幅,序列长度从波形的L缩减到feature map的T。长度恢复对于生成与输入长度相同的输出波形至关重要。假设输入长度Lin、输出长度Lout、步幅S和填充P,则Lin和Lout的关系可表示为
Lout =(Lin −1)×S−2×P+(K−1)+1
设Lin=T,S=K/2,P=K/2,则Lout=L即保证输出波形与输入波形具有相同的长度。
E 模型结构概述
如图1所示,我们的模型利用了CNN和SRU的优势。给定第i个带噪语音Xi,在一个batch中,一维卷积首先将Xi映射到特征映射Fi中进行局部特征提取。然后Bi-SRU计算一个RFM Mi,该Mi元素巧妙地将Fi相乘生成一个掩蔽特征映射F′。最后,转置的1D卷积层从掩蔽特征F′i恢复增强的语音波形Xi。
实验步骤
1)、语音去噪:将语音数据下采样到16 kHz进行训练和测试。在语音库中,30名说话人中有28人用于训练,2名说话人用于测试。对于训练集,在4个信噪比(0、5、10和15dB),纯净语音被10种类型的噪声污染。对于测试组,在其他4个信噪比(2.5、7.5、12.5和17.5dB),纯净的语音被5种看不见的噪声所污染。
2)、压缩(2位)语音恢复:对于压缩语音恢复任务,我们使用了TIMIT语料库[43],原始语音样本以16 kHz和16位格式记录。在这组实验中,每个样本都被压缩成2比特的格式(用−1、0或+1表示),节省了87.5%的比特,从而降低了数据传输和存储需求,我们相信这种压缩方案在现实世界的物联网场景中具有潜在的应用前景。注意,在去噪和恢复任务中使用了相同的模型架构。每个压缩样本的+1、0或−1值首先被映射到浮点表示,因此可以容易地应用波形域SE系统来恢复原始的未压缩语音。将原始语音表示为y^,压缩语音表示为sgn(y^),其中gθ表示SE过程。
![]()
实验结果
(1)语音去噪:与Wiener滤波、SEGAN、使用相同L1损耗的两个知名SE模型(即WaveNET和Wave-U-Net)、使用LPS特征作为输入的LPS-SRU以及结合CNN和BLSTM的Wave CBLSTM进行了比较。WaveCBLSTM是通过用LSTM代替图1中的SRU来实现的,可以看到WaveCRN在所有感知和信号级评估指标方面都优于其他模型。
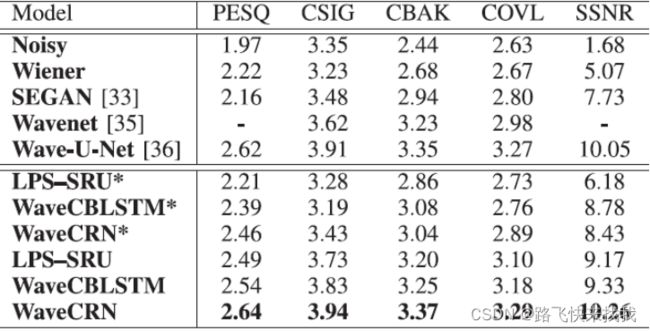
表1 语音去噪任务的结果。分数越高,表现越好,用*标记的模型不使用RFM直接生成增强语音
其次,研究了RFM的影响。如表I所示,LPS-SRU、WaveCBLSTM和WaveCRN优于不使用RFM的对应物(LPS-SRU*、WaveCBLSTM*和WaveCRN*)。
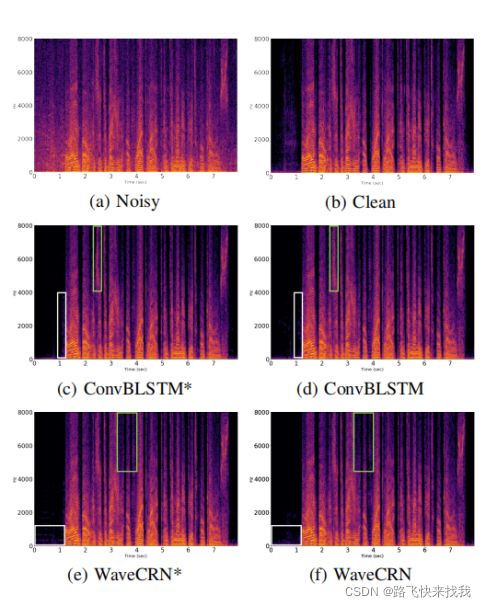
图2 ConvBLSTM,ConvBLSTM * ,WaveCRN,和 WaveCRN *的噪声、纯净和增强语音的幅度谱图,其中标有*的模型不使用RFM直接生成增强语音。
可以看到RFM在高频区域产生较少的失真。RFM显著消除了高频区域(绿色块)和静音部分(白色块)中的噪声分量。
(2)压缩语音恢复:LPS-SRU采用与WaveCRN相同的SRU结构,但输入为LPS。从表2可以看出,WaveCRN和LPS-SRU使PESQ评分从1.39分提高到2.41分和1.97分,STOI分从0.49分提高到0.86分和0.79分。这两种方法都取得了显著的改进,而WaveCRN的性能明显优于LPS-SRU。
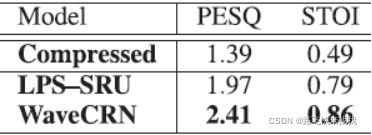
表2 压缩语音恢复任务的结果
从图3(A)和3(B)中观察到,语音质量在2比特格式中显著降低,特别是在静音部分和高频区域。然而,由WaveCRN和LPS-SRU恢复的语音谱图呈现出更清晰的结构,如图3(C)和3(D)所示。另外,挡路白区实验表明,WaveCRN比LPS-SRU能更有效地恢复语音模式而不丢失相位信息。
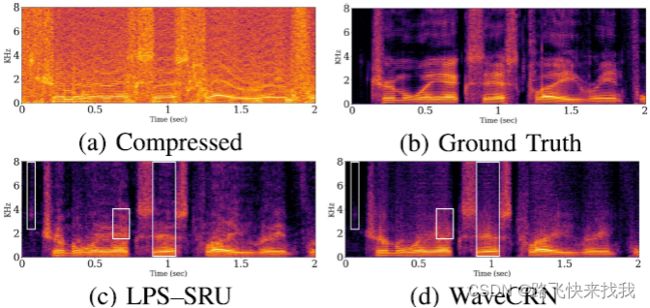 图3所示。LPS SRU和WaveCRN生成的原始、压缩和恢复语音的幅度谱图。(一)压缩。(b)Ground Truth。(c) LPS-SRU。(d) WaveCRN。
图3所示。LPS SRU和WaveCRN生成的原始、压缩和恢复语音的幅度谱图。(一)压缩。(b)Ground Truth。(c) LPS-SRU。(d) WaveCRN。

最后,我们比较 WaveCRN 和 ConvBLSTM 在推断时间和模型复杂性方面。表III 中的第一列显示了正向传递的执行时间,第二列显示了参数的数量。在相同的超参数设置(层数、隐含状态维数、通道数等)下,与ConvBLSTM相比WaveCRN的执行速度提高了 25.36 倍,参数数目仅为 ConvBLSTM 的 51% 。
总结
提出了WaveCRN E2E SE模型。WAVE-CRN采用双向结构对提取的特征的顺序相关性进行建模。实验结果表明,WaveCRN在去噪能力和计算效率上均优于相关工作。
2022.1.26