深度学习:01 神经网络与激活函数
目前,最广泛使用的定义是Kohonen于1988年的描述:
神经网络是由具有适应性的简单单元组成的广泛并行互连的网络,它的组织能够模拟生物神经系统对真实世界物体所做出的交互反应。
目录
对神经网络的概述
神经网络的表示
激活函数
为什么激活函数都是非线性的
sigmoid 函数
tanh 函数
ReLU 函数
Leaky Relu 函数
参考资料
对神经网络的概述
只用到高中阶段中学到的生物神经网络,我们便能知道在这个网络当中,每个神经元会与其他的神经元相连,当产生兴奋时,会向其相连的神经元发送化学信号,从而改变这些神经元内的电位,当某个神经元的电位超过了一个阈值,神经元被激活,也就是兴奋了,接着不断地传递信号给其他神经元。

而在如今地深度学习也是借鉴了这样地结构,每一个神经元接收输入x,通过带权重地w地连接进行传递,将总输入信号与神经元的阈值进行比较,最后通过激活函数来确定是否激活,并将激活后的计算结果y输出,而我们所说的训练,所训练的就是这里面的权重w。
从数学地角度来说,就是输入x,输出y,斜率w。
神经网络的表示
我们可以将神经元拼接起来,两层神经元,即输入层+输出层(M-P神经元),构成感知机。 而多层功能神经元相连构成神经网络,输入层与输出层之间的所有层神经元,称为隐藏层:

如上图所示,输入层和输出层只有一个,中间的隐藏层可以有很多层(输出层也可以多个,例如经典神经网络GoogleNet)
激活函数
在概述时已经说到,神经元会受到化学物质的刺激,当达到一定程度的时候,神经元才会兴奋,并向其他神经元发送信息。神经网络中的激活函数就是用来判断我们所计算的信息是否达到了往后面传输的条件。

为什么激活函数都是非线性的
在神经网络的计算中,无非就是矩阵相乘,输入的是线性,不论输出层有多少,相当于n个矩阵相乘,和一层相乘所获取的信息差距不大,那我们无非是要引入非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中,增加了神经网络模型泛化的特性。
早期研究神经网络主要采用sigmoid函数或者tanh函数,输出有界,很容易充当下一层的输入。 近些年Relu函数及其改进型(如Leaky-ReLU、P-ReLU、R-ReLU等),由于计算简单、效果好所以在多层神经网络中应用比较多。
下面来总结下较常见的激活函数:
# 下面内容都要有此片段
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
import numpy as np
x= torch.linspace(-10,10,60)sigmoid 函数
![]()
导数 :![]()
在sigmoid函数中我们可以看到,其输出是在(0,1)这个开区间,它能够把输入的连续实值变换为0和1之间的输出,如果是非常大的负数,那么输出就是0;如果是非常大的正数输出就是1,起到了抑制的作用。
ax = plt.gca()
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
ax.xaxis.set_ticks_position('bottom')
ax.spines['bottom'].set_position(('data', 0))
ax.yaxis.set_ticks_position('left')
ax.spines['left'].set_position(('data', 0))
plt.ylim((0, 1))
sigmod=torch.sigmoid(x)
plt.plot(x.numpy(),sigmod.numpy())
但是sigmod由于需要进行指数运算(这个对于计算机来说是比较慢,相比relu),再加上函数输出不是以0为中心的(这样会使权重更新效率降低),当输入稍微远离了坐标原点,函数的梯度就变得很小了(几乎为零)。在神经网络反向传播的过程中不利于权重的优化,这个问题叫做梯度饱和,也可以叫梯度弥散。这些不足,所以现在使用到sigmod基本很少了,基本上只有在做二元分类(0,1)时的输出层才会使用。
tanh 函数
![]()
导数:![]()
tanh是双曲正切函数,输出区间是在(-1,1)之间,而且整个函数是以0为中心的。
ax = plt.gca()
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
ax.xaxis.set_ticks_position('bottom')
ax.spines['bottom'].set_position(('data', 0))
ax.yaxis.set_ticks_position('left')
ax.spines['left'].set_position(('data', 0))
plt.ylim((-1, 1))
tanh=torch.tanh(x)
plt.plot(x.numpy(),tanh.numpy())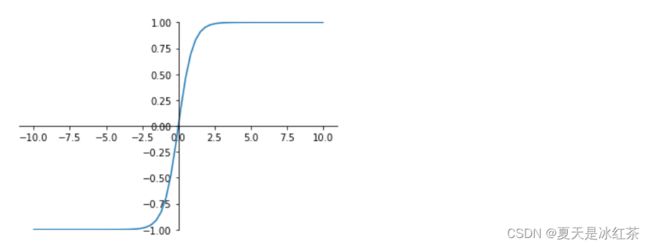
与sigmoid函数类似,当输入稍微远离了坐标原点,梯度还是会很小,但是好在tanh是以0为中心点,如果使用tanh作为激活函数,还能起到归一化(均值为0)的效果。
一般二分类问题中,隐藏层用tanh函数,输出层用sigmod函数,但是随着Relu的出现所有的隐藏层基本上都使用relu来作为激活函数了。
ReLU 函数
Relu(Rectified Linear Units)修正线性单元
a=max(0,z)a=max(0,z) 导数大于0时1,小于0时0。
也就是说: z>0时,梯度始终为1,从而提高神经网络基于梯度算法的运算速度。然而当 z<0时,梯度一直为0。 ReLU函数只有线性关系(只需要判断输入是否大于0)不管是前向传播还是反向传播,都比sigmod和tanh要快很多,当输入是负数的时候,ReLU是完全不被激活的,这就表明一旦输入到了负数,ReLU就会死掉。但是到了反向传播过程中,输入负数,梯度就会完全到0,这个和sigmod函数、tanh函数有一样的问题。 但是实际的运用中,该缺陷的影响不是很大。
ax = plt.gca()
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
ax.xaxis.set_ticks_position('bottom')
ax.spines['bottom'].set_position(('data', 0))
ax.yaxis.set_ticks_position('left')
ax.spines['left'].set_position(('data', 0))
plt.ylim((-3, 10))
relu=F.relu(x)
plt.plot(x.numpy(),relu.numpy())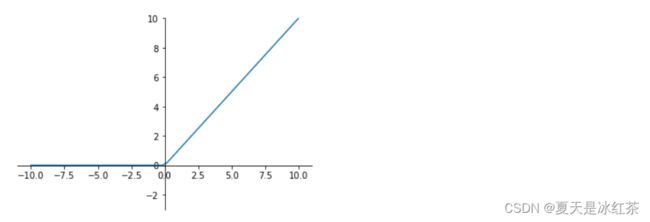
Leaky Relu 函数
为了解决relu函数z<0时的问题出现了 Leaky ReLU函数,该函数保证在z<0的时候,梯度仍然不为0。 ReLU的前半段设为αz而非0,通常α=0.01 a=max(αz,z)
ax = plt.gca()
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
ax.xaxis.set_ticks_position('bottom')
ax.spines['bottom'].set_position(('data', 0))
ax.yaxis.set_ticks_position('left')
ax.spines['left'].set_position(('data', 0))
plt.ylim((-3, 10))
l_relu=F.leaky_relu(x,0.1) # 这里的0.1是为了方便展示,理论上应为0.01甚至更小的值
plt.plot(x.numpy(),l_relu.numpy())
理论上来讲,Leaky ReLU有ReLU的所有优点,但是在实际操作当中,并没有完全证明Leaky ReLU总是好于ReLU。
ReLU目前仍是最常用的activation function,在隐藏层中推荐优先尝试!
参考资料
神经网络简介 [D. Kriesel] (dkriesel.com)
neuronalenetze-en-zeta2-1col-dkrieselcom.pdf