2018年蓝桥杯B组真题详解
2018年蓝桥杯B组真题详解
- 第一题:第几天
-
- 代码
- 第二题:明码
-
- 代码
-
-
- 科普:
-
- 第三题:乘积尾零
-
-
- 分析题目得:
- 代码
-
- 第四题:测试次数
-
-
- 思路
- 代码
- 总结
-
- 第五题:快速排序
-
- 源代码
- 第六题:递增三元组
-
- 代码
- 第七题:螺旋折线
-
-
- 思路
- 代码
-
- 第八题:日志统计
-
- 代码
- 第九题:全球变暖
-
-
- 分析
- 代码
-
- 第十题:乘积最大
-
- 代码
第一题:第几天
2000年的1月1日,是那一年的第1天。
那么,2000年的5月4日,是那一年的第几天?
注意:需要提交的是一个整数,不要填写任何多余内容。
这一题可以直接计算写答案
代码
#include第二题:明码

先阅读题目,由题可知:这段信息共有10行,每一行代表一个汉字(一共10个汉字)又一行有32个数字所以32个汉字分别代表32个字节,根据文中布局知这32个数字的排列方式再将这些数字转换成2进制8位,那横纵就都为16,再转换为点阵就是16点阵。
语文不太好可能描述不太好
代码
#include
}
//cout<
}
long long ans=9;
for(int k=0;k<8;k++)
{
ans *=9;
}
cout << ans << endl;
return 0;
}
因题目需要所以输出只为一个答案
科普:
另外介绍一下>>这个右移符号移动一位是除以2,移动两位是除以2的2 次方再用&1判断是否为1进行改变ans数组然后输出即可
第三题:乘积尾零
如下的10行数据,每行有10个整数,请你求出它们的乘积的末尾有多少个零?
5650 4542 3554 473 946 4114 3871 9073 90 4329
2758 7949 6113 5659 5245 7432 3051 4434 6704 3594
9937 1173 6866 3397 4759 7557 3070 2287 1453 9899
1486 5722 3135 1170 4014 5510 5120 729 2880 9019
2049 698 4582 4346 4427 646 9742 7340 1230 7683
5693 7015 6887 7381 4172 4341 2909 2027 7355 5649
6701 6645 1671 5978 2704 9926 295 3125 3878 6785
2066 4247 4800 1578 6652 4616 1113 6205 3264 2915
3966 5291 2904 1285 2193 1428 2265 8730 9436 7074
689 5510 8243 6114 337 4096 8199 7313 3685 211
注意:需要提交的是一个整数,表示末尾零的个数。不要填写任何多余内容。
分析题目得:
1.要让尾数为零的话,首先尾数为零只能是2乘5才会使得尾数尾零。
2.理解这一点就可以了,对一个数进行因式分解也就是统计2和5的个数就是尾数尾零的个数,当然不能分解的就不要管它了,最后统计出有多少个2和5,输出较少的数即可。
代码
#include第四题:测试次数
x星球的居民脾气不太好,但好在他们生气的时候唯一的异常举动是:摔手机。
各大厂商也就纷纷推出各种耐摔型手机。x星球的质监局规定了手机必须经过耐摔测试,并且评定出一个耐摔指数来,之后才允许上市流通。
x星球有很多高耸入云的高塔,刚好可以用来做耐摔测试。塔的每一层高度都是一样的,与地球上稍有不同的是,他们的第一层不是地面,而是相当于我们的2楼。
如果手机从第7层扔下去没摔坏,但第8层摔坏了,则手机耐摔指数=7。
特别地,如果手机从第1层扔下去就坏了,则耐摔指数=0。
如果到了塔的最高层第n层扔没摔坏,则耐摔指数=n
为了减少测试次数,从每个厂家抽样3部手机参加测试。
某次测试的塔高为1000层,如果我们总是采用最佳策略,在最坏的运气下最多需要测试多少次才能确定手机的耐摔指数呢?
请填写这个最多测试次数。
注意:需要填写的是一个整数,不要填写任何多余内容。
思路
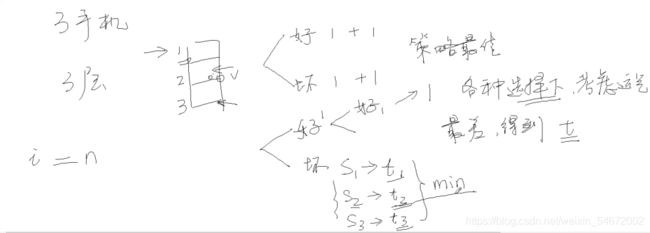
根据题目我们采用最佳策略,即从中间开始(当然“二分查找法”的目标是平均性能最佳,并不是最差性能最佳),所以我们不能直接使用二分查找,应该利用动态规划(具体情况如代码所示)。在考虑最坏的运气情况下,计算得到t。
代码
#include 总结
- climits 这个头文件里面装了很多常见的常量
- 两个变量决定一个值的时候就要考虑是不是可以dp做
- 理清思路不要慌,从1 一点点枚举过去找思路
- 重点是 摔坏了手机就要用 剩下的手机测剩下的楼层,如果没摔坏就是用当前手机数测试剩下的楼层,去最坏情况和最佳的策略就好了
第五题:快速排序
以下代码可以从数组a[]中找出第k小的元素。
它使用了类似快速排序中的分治算法,期望时间复杂度是O(N)的。
请仔细阅读分析源码,填写划线部分缺失的内容。
源代码
i++;
}
}
a[i] = x;
p = i;
if(i - l + 1 == k) return a[i];
if(i - l + 1 < k) return quick_select( _____________________________ ); //填空
else return quick_select(a, l, i - 1, k);
}
int main()
{
int a[] = {1, 4, 2, 8, 5, 7, 23, 58, 16, 27, 55, 13, 26, 24, 12};
printf("%d\n", quick_select(a, 0, 14, 5));
return 0;
}
注意:只填写划线部分缺少的代码,不要抄写已经存在的代码或符号。
根据题意补充代码为:
a, i+1, r, k-(i-l+1)
虽然填写别的答案也能过样例,但是这道题的要求是时间复杂度为O(n)。
第六题:递增三元组
给定三个整数数组
A = [A1, A2, … AN],
B = [B1, B2, … BN],
C = [C1, C2, … CN],
请你统计有多少个三元组(i, j, k) 满足:
- 1 <= i, j, k <= N
- Ai < Bj < Ck
【输入格式】
第一行包含一个整数N。
第二行包含N个整数A1, A2, … AN。
第三行包含N个整数B1, B2, … BN。
第四行包含N个整数C1, C2, … CN。
对于30%的数据,1 <= N <= 100
对于60%的数据,1 <= N <= 1000
对于100%的数据,1 <= N <= 100000 0 <= Ai, Bi, Ci <= 100000
【输出格式】
一个整数表示答案
【样例输入】
3
1 1 1
2 2 2
3 3 3
【样例输出】
27
本题重点在于将三个数组进行排序,能节省时间避免超时。
难度其实也不大 不过直接暴力枚举的时候就会超时,所以我们用B数组作为基准,在a数组中找小于B的 在c中找大于B的,而且如果 b[i] > c[i] 那么 b[i+1] >c[i] 也是成立的,所以又可以不用每一次都从头找。
代码
#include 第七题:螺旋折线

如图p1.png所示的螺旋折线经过平面上所有整点恰好一次。
对于整点(X, Y),我们定义它到原点的距离dis(X, Y)是从原点到(X, Y)的螺旋折线段的长度。
例如dis(0, 1)=3, dis(-2, -1)=9
给出整点坐标(X, Y),你能计算出dis(X, Y)吗?
【输入格式】
X和Y
对于40%的数据,-1000 <= X, Y <= 1000
对于70%的数据,-100000 <= X, Y <= 100000
对于100%的数据, -1000000000 <= X, Y <= 1000000000
【输出格式】
输出dis(X, Y)
【样例输入】
0 1
【样例输出】
3
资源约定:
峰值内存消耗(含虚拟机) < 256M
CPU消耗 < 1000ms
请严格按要求输出,不要画蛇添足地打印类似:“请您输入…” 的多余内容。
注意:
main函数需要返回0;
只使用ANSI C/ANSI C++ 标准;
不要调用依赖于编译环境或操作系统的特殊函数。
所有依赖的函数必须明确地在源文件中 #include
不能通过工程设置而省略常用头文件。
提交程序时,注意选择所期望的语言类型和编译器类型。
思路
将图中(1,1)(2,2),(3,3)作为一圈结束的标志
则可以发现
2 6 10
4 8 12
可以构成等差数列 把这个分为两部分(就是两个相同的等差数列)
则可以形成 a0=1,d=1,n为圈数2的等差数列
sum(1,2n,1)*2-d
这个就是等差数列求和公式。
代码
#include第八题:日志统计
问题
小明维护着一个程序员论坛。现在他收集了一份"点赞"日志,日志共有N行。其中每一行的格式是:
ts id
表示在ts时刻编号id的帖子收到一个"赞"。
现在小明想统计有哪些帖子曾经是"热帖"。如果一个帖子曾在任意一个长度为D的时间段内收到不少于K个赞,小明就认为这个帖子曾是"热帖"。
具体来说,如果存在某个时刻T满足该帖在[T, T+D)这段时间内(注意是左闭右开区间)收到不少于K个赞,该帖就曾是"热帖"。
给定日志,请你帮助小明统计出所有曾是"热帖"的帖子编号。
【输入格式】
第一行包含三个整数N、D和K。
以下N行每行一条日志,包含两个整数ts和id。
对于50%的数据,1 <= K <= N <= 1000
对于100%的数据,1 <= K <= N <= 100000 0 <= ts <= 100000 0 <= id <= 100000
【输出格式】
按从小到大的顺序输出热帖id。每个id一行。
【输入样例】
7 10 2
0 1
0 10
10 10
10 1
9 1
100 3
100 3
【输出样例】
13
难度不大 ,各种数据结构的使用,结构体的排序,尺取法等等。
关于尺取法可以点击以下链接或点击上一行尺取法三个字: https://blog.csdn.net/lxt_Lucia/article/details/81091597
接下来看代码以及其中注释:
代码
#include 第九题:全球变暖
问题
你有一张某海域NxN像素的照片,".“表示海洋、”#"表示陆地,如下所示:
…
.##…
.##…
…##.
…####.
…###.
…
其中"上下左右"四个方向上连在一起的一片陆地组成一座岛屿。例如上图就有2座岛屿。
由于全球变暖导致了海面上升,科学家预测未来几十年,岛屿边缘一个像素的范围会被海水淹没。具体来说如果一块陆地像素与海洋相邻(上下左右四个相邻像素中有海洋),它就会被淹没。
例如上图中的海域未来会变成如下样子:
…
…
…
…
…#…
…
…
请你计算:依照科学家的预测,照片中有多少岛屿会被完全淹没。
【输入格式】
第一行包含一个整数N。 (1 <= N <= 1000)
以下N行N列代表一张海域照片。
照片保证第1行、第1列、第N行、第N列的像素都是海洋。
【输出格式】
一个整数表示答案。
【输入样例】
7
…
.##…
.##…
…##.
…####.
…###.
…
【输出样例】
1
分析
这题可以用广搜(BFS)。
广搜:https://www.cnblogs.com/yun-an/p/11048950.html
深搜:https://blog.csdn.net/red_red_red/article/details/88979841
两种方法的比较:http://data.biancheng.net/view/39.html
代码
#include 第十题:乘积最大
给定N个整数A1, A2, … AN。请你从中选出K个数,使其乘积最大。
请你求出最大的乘积,由于乘积可能超出整型范围,你只需输出乘积除以1000000009的余数。
注意,如果X<0, 我们定义X除以1000000009的余数是负(-X)除以1000000009的余数
即:0-((0-x) % 1000000009)
【输入格式】
第一行包含两个整数N和K。
以下N行每行一个整数Ai。
对于40%的数据,1 <= K <= N <= 100
对于60%的数据,1 <= K <= 1000
对于100%的数据,1 <= K <= N <= 100000 -100000 <= Ai <= 100000
【输出格式】
一个整数,表示答案。
【输入样例】
5 3
-100000
-10000
2
100000
10000
【输出样例】
999100009
再例如:
【输入样例】
5 3
-100000
-100000
-2
-100000
-100000
【输出样例】
-999999829
资源约定:
峰值内存消耗(含虚拟机) < 256M
CPU消耗 < 1000ms
请严格按要求输出,不要画蛇添足地打印类似:“请您输入…” 的多余内容。
注意:
main函数需要返回0;
只使用ANSI C/ANSI C++ 标准;
不要调用依赖于编译环境或操作系统的特殊函数。
所有依赖的函数必须明确地在源文件中 #include
不能通过工程设置而省略常用头文件。
提交程序时,注意选择所期望的语言类型和编译器类型。
代码
#include