机器学习:线性(Fisher)判别分析
文章目录
- 前言
- 一、散度矩阵
- 二、目标函数与权重向量
- 三、总结
- 参考资料
本文属于我的机器学习/深度学习系列文章,点此查看系列文章目录
前言
线性(Fisher)判别分析(Linear Discriminant Analysis, LDA)也属于线性分类方法的一种,由(Fisher,1936)提出,所以也叫Fisher判别分析。
LDA的基本思想是:对于给定的训练数据样本,将样本投影到一条直线上,让同类的样例的投影点尽可能近,异类样例投影点尽可能远,这样就区分开了两类样本。当对新的样本预测时,将其投影到这条直线上,看其离哪个分类近来确定它的类别。
将上面的思想转化成对目标函数的优化,就得到了:
max w J ( w ) = 类 间 平 均 距 离 类 内 平 均 距 离 \max_{\mathbf w}J(\mathbf w) = \frac{类间平均距离}{类内平均距离} wmaxJ(w)=类内平均距离类间平均距离
下图是LDA的二维示意图:
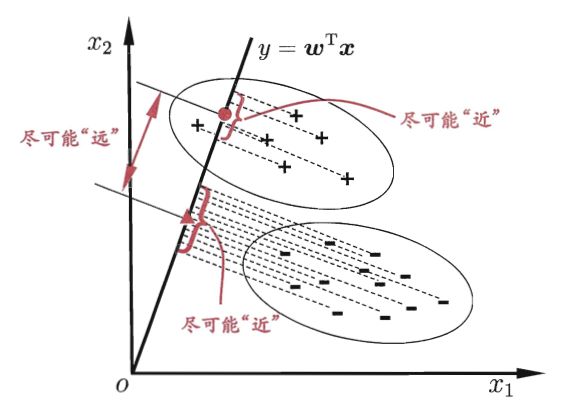
一、散度矩阵
首先设给定数据集 D = { ( x i , y i ) i = 1 m , y i ∈ { 0 , 1 } } D=\{(\mathbf x_i,y_i)_{i=1}^m, y_i\in \{0,1\}\} D={(xi,yi)i=1m,yi∈{0,1}},我们需要用给定数据去刻画类间和类内距离。
-
类间距离
两类样本的类间距离怎么刻画?这么多点,只能通过找两个代表性的点来计算距离,显然是均值向量点。将两个均值向量( μ 1 , μ 2 \mu_1,\mu_2 μ1,μ2)投影到直线上,得到投影点( m 1 , m 2 m_1,m_2 m1,m2)之间的距离平方 ( m 1 − m 2 ) 2 (m_1-m_2)^2 (m1−m2)2。 向量 μ \mu μ在另一向量 w \mathbf w w上的投影为 w T μ \mathbf w^T \mu wTμ(忘了的可以看机器学习:线性分类问题(基础知识))。

由此我们有
类 间 距 离 的 平 方 = ( m 1 − m 2 ) 2 = [ w T ( μ → 1 − μ → 2 ) ] 2 = [ w T ( μ → 1 − μ → 2 ) ] [ w T ( μ → 1 − μ → 2 ) ] T = w T ( μ → 1 − μ → 2 ) ( μ → 1 − μ → 2 ) T w = w T S b w S b = ( μ → 1 − μ → 2 ) ( μ → 1 − μ → 2 ) T , 类 间 散 度 矩 阵 类间距离的平方= (m_1-m_2)^2 \\ = [\mathbf w^T(\overrightarrow \mu_1-\overrightarrow \mu_2)] ^2\\ = [\mathbf w^T(\overrightarrow \mu_1-\overrightarrow \mu_2)][\mathbf w^T(\overrightarrow \mu_1-\overrightarrow \mu_2)]^T\\ = \mathbf w^T(\overrightarrow \mu_1-\overrightarrow \mu_2)(\overrightarrow \mu_1-\overrightarrow \mu_2)^T\mathbf w\\ = \mathbf w^T S_b \mathbf w\\ S_b = (\overrightarrow \mu_1-\overrightarrow \mu_2)(\overrightarrow \mu_1-\overrightarrow \mu_2)^T,类间散度矩阵 类间距离的平方=(m1−m2)2=[wT(μ1−μ2)]2=[wT(μ1−μ2)][wT(μ1−μ2)]T=wT(μ1−μ2)(μ1−μ2)Tw=wTSbwSb=(μ1−μ2)(μ1−μ2)T,类间散度矩阵 -
类内距离
所谓类内距离刻画的就是同类中各个样本的松散程度,只要看每个点和均值点的距离平方和类内散裂度(类似方差)即可。类内散列度越小,意味着样本靠的越近。

由此,记类内散列度为 S c 2 S_c^2 Sc2有
S c 2 = ∑ i ∈ C ( w T x i − m c ) 2 = ∑ i ∈ C ( w T ( x i − μ → c ) 2 ) = ∑ i ∈ C [ w T ( x i − μ → c ) ] [ w T ( x i − μ → c ) ] T = ∑ i ∈ C w T ( x i − μ → c ) ( x i − μ → c ) T w = w T [ ∑ i ∈ C ( x i − μ → c ) ( x i − μ → c ) T ] w S_c^2 = \sum_{i\in C}(\mathbf w^T\mathbf x_i - m_c)^2 \\ = \sum_{i\in C}(\mathbf w^T(\mathbf x_i - \overrightarrow \mu_c)^2)\\ = \sum_{i\in C}[\mathbf w^T(\mathbf x_i - \overrightarrow \mu_c)][\mathbf w^T(\mathbf x_i - \overrightarrow \mu_c)]^T\\ = \sum_{i\in C}\mathbf w^T(\mathbf x_i-\overrightarrow \mu_c)(\mathbf x_i-\overrightarrow \mu_c)^T\mathbf w\\ = \mathbf w^T[\sum_{i\in C}(\mathbf x_i-\overrightarrow \mu_c)(\mathbf x_i-\overrightarrow \mu_c)^T]\mathbf w Sc2=i∈C∑(wTxi−mc)2=i∈C∑(wT(xi−μc)2)=i∈C∑[wT(xi−μc)][wT(xi−μc)]T=i∈C∑wT(xi−μc)(xi−μc)Tw=wT[i∈C∑(xi−μc)(xi−μc)T]w
但这只是一个分类的,要同时考虑两个分类的类内散列度,如下
S 1 2 + S 2 2 = w T [ ∑ i ∈ C 1 ( x i − μ → 1 ) ( x i − μ → 1 ) T ] w + w T [ ∑ i ∈ C 2 ( x i − μ → 2 ) ( x i − μ → 2 ) T ] w = w T [ ∑ j = 1 , 2 ∑ i ∈ C j ( x i − μ → j ) ( x i − μ → j ) T ] w = w T S w w S w = ∑ j = 1 , 2 ∑ i ∈ C j ( x i − μ → j ) ( x i − μ → j ) T , 类 内 散 度 矩 阵 S_1^2 + S_2^2 = \mathbf w^T[\sum_{i\in C_1}(\mathbf x_i-\overrightarrow \mu_1)(\mathbf x_i-\overrightarrow \mu_1)^T]\mathbf w \\+ \mathbf w^T[\sum_{i\in C_2}(\mathbf x_i-\overrightarrow \mu_2)(\mathbf x_i-\overrightarrow \mu_2)^T]\mathbf w \\ = \mathbf w^T[\sum_{j=1,2}\sum_{i\in C_j} (\mathbf x_i-\overrightarrow \mu_j)(\mathbf x_i-\overrightarrow \mu_j)^T]\mathbf w \\ = \mathbf w^T S_w\mathbf w \\ S_w = \sum_{j=1,2}\sum_{i\in C_j} (\mathbf x_i-\overrightarrow \mu_j)(\mathbf x_i-\overrightarrow \mu_j)^T,类内散度矩阵 S12+S22=wT[i∈C1∑(xi−μ1)(xi−μ1)T]w+wT[i∈C2∑(xi−μ2)(xi−μ2)T]w=wT[j=1,2∑i∈Cj∑(xi−μj)(xi−μj)T]w=wTSwwSw=j=1,2∑i∈Cj∑(xi−μj)(xi−μj)T,类内散度矩阵推导过程其实不难,仔细一点就能理解
二、目标函数与权重向量
有了类间距离和类内距离的刻画后, 依据上文的定义,可以得到我们的目标函数如下:
max w J ( w ) = 类 间 距 离 类 内 距 离 = ( m 1 − m 2 ) 2 S 1 2 + S 2 2 = w T S b w w T S w w \max_{\mathbf w} J(\mathbf w) = \frac{类间距离}{类内距离} \\ = \frac{(m_1-m_2)^2}{S_1^2+S_2^2} \\ = \frac{ \mathbf w^T S_b \mathbf w}{ \mathbf w^T S_w\mathbf w} wmaxJ(w)=类内距离类间距离=S12+S22(m1−m2)2=wTSwwwTSbw
理解该公式中 S b , S w S_b,S_w Sb,Sw都是根据训练数据确定的值,我们的目标是找到使得 J J J最大的 w \mathbf w w,利用拉格朗日乘子法,原问题可转变为
max w L ( w , λ ) = w T S b w − λ ( w T S w w − C ) \max_{\mathbf w} L(\mathbf w, \lambda) = \mathbf w^T S_b \mathbf w - \lambda(\mathbf w^T S_w \mathbf w-C) wmaxL(w,λ)=wTSbw−λ(wTSww−C)
对 w \mathbf w w求偏导可得,
∂ L ( w , λ ) ∂ w = S b w − λ S w w = 0 ⟹ S b w = λ S w w ⟹ S w − 1 S b w = λ w \frac{\partial L(\mathbf w, \lambda)}{\partial \mathbf w} = S_b\mathbf w- \lambda S_w\mathbf w = 0\\ \implies S_b\mathbf w = \lambda S_w\mathbf w \\ \implies S_w^{-1}S_b\mathbf w = \lambda \mathbf w ∂w∂L(w,λ)=Sbw−λSww=0⟹Sbw=λSww⟹Sw−1Sbw=λw
实际上到这已经发现 w \mathbf w w是 S w − 1 S b S_w^{-1}S_b Sw−1Sb的特征向量了,用求特征向量的方法即可得到 w \mathbf w w。但是可以利用 S b = ( μ → 1 − μ → 2 ) ( μ → 1 − μ → 2 ) T S_b = (\overrightarrow \mu_1-\overrightarrow \mu_2)(\overrightarrow \mu_1-\overrightarrow \mu_2)^T Sb=(μ1−μ2)(μ1−μ2)T对其进一步化简,如下
S b w = ( μ → 1 − μ → 2 ) ( μ → 1 − μ → 2 ) T w = ( μ → 1 − μ → 2 ) [ ( μ → 1 − μ → 2 ) T w ] , [ ] 内 是 个 标 量 = β ( μ → 1 − μ → 2 ) S_b \mathbf w = (\overrightarrow \mu_1-\overrightarrow \mu_2)(\overrightarrow \mu_1-\overrightarrow \mu_2)^T\mathbf w \\= (\overrightarrow \mu_1-\overrightarrow \mu_2)[(\overrightarrow \mu_1-\overrightarrow \mu_2)^T\mathbf w],[]内是个标量\\ = \beta (\overrightarrow \mu_1-\overrightarrow \mu_2) Sbw=(μ1−μ2)(μ1−μ2)Tw=(μ1−μ2)[(μ1−μ2)Tw],[]内是个标量=β(μ1−μ2)
将结果带入上面得到
S w − 1 β ( μ → 1 − μ → 2 ) = λ w ⟹ w = β λ S w − 1 ( μ → 1 − μ → 2 ) ⟹ w = S w − 1 ( μ → 1 − μ → 2 ) , β λ 相 当 于 对 w 放 缩 , 可 以 省 略 S_w^{-1}\beta (\overrightarrow \mu_1-\overrightarrow \mu_2) = \lambda \mathbf w \\ \implies \mathbf w = \frac{\beta}{\lambda} S_w^{-1}(\overrightarrow \mu_1-\overrightarrow \mu_2)\\ \implies \mathbf w = S_w^{-1}(\overrightarrow \mu_1-\overrightarrow \mu_2),\frac{\beta}{\lambda} 相当于对\mathbf w放缩,可以省略 Sw−1β(μ1−μ2)=λw⟹w=λβSw−1(μ1−μ2)⟹w=Sw−1(μ1−μ2),λβ相当于对w放缩,可以省略
至此,我们就将所需直线的方向向量 w \mathbf w w(也是样本的权重向量)计算出来了。实际上当直线的方向确定后,各类样本在直线上投影的相对位置就确定了,即类间距离和类内距离确定。但是为了方便决策,我们希望在投影之后有一个明确的数值分解,例如0,投影结果大于0是一类,投影结果小于0是一类,而这个就是决策函数 g ( x ) = w T x + w 0 g(\mathbf x) = \mathbf w^T\mathbf x +w_0 g(x)=wTx+w0的偏置 w 0 w_0 w0决定。考虑两类均值向量的中心点 1 2 ( μ → 1 + μ → 2 ) \frac{1}{2}(\overrightarrow \mu_1+\overrightarrow \mu_2) 21(μ1+μ2),这个点样本讲道理应该可以任意分入两类,也可以两边都不分入,所以作为分界点最合适,我们的决策函数应该要通过该点,因此有
w 0 = − 1 2 ( w T μ → 1 + w T μ → 2 ) g ( x ) = w T x + w 0 w_0 = -\frac{1}{2}(\mathbf w^T\overrightarrow \mu_1+\mathbf w^T\overrightarrow \mu_2) \\ g(\mathbf x ) = \mathbf w^T\mathbf x + w_0 w0=−21(wTμ1+wTμ2)g(x)=wTx+w0
三、总结
线性鉴别分析的主要思想还是很好理解的,就是一个类间距离和一个类内距离,让类间距离尽可能大,分类界限更清晰,类内距离尽可能小,同类更紧密。由上面的思想可以将Fisher鉴别分成如下几步:
-
根据正反例求各类均值 μ → 1 , μ → 2 \overrightarrow \mu_1,\overrightarrow \mu_2 μ1,μ2,作为类别间最大方向
-
求类内散度矩阵 S w S_w Sw
S w = ∑ i = 1 2 ∑ x ∈ C i ( x − μ i ) ( x − μ i ) T S_w = \sum_{i=1}^2 \sum_{x\in C_i}(x-\mu_i)(x-\mu_i)^T Sw=i=1∑2x∈Ci∑(x−μi)(x−μi)T -
求类内散度矩阵的逆 S w − 1 S_w^{-1} Sw−1
-
求权重向量 w \mathbf w w
w = S w − 1 ( μ 1 − μ 2 ) \mathbf w = S_w^{-1}(\mu_1-\mu_2) w=Sw−1(μ1−μ2) -
计算两类投影中心 u 1 , u 2 u_1,u_2 u1,u2
u i = w T μ i , i = 1 , 2 u_i = \mathbf w^T \mu_i, i=1,2 ui=wTμi,i=1,2 -
得到决策函数
g ( x ) = w T x − 1 2 ( u 1 + u 2 ) g(\mathbf x ) = \mathbf w^T\mathbf x -\frac{1}{2}(u_1+u_2) g(x)=wTx−21(u1+u2)
参考资料
- 周志华. 机器学习. 2016
- 周晓飞. Fisher线性鉴别推导过程