第六篇:Feedforward Networks 前向网络
目录
深度学习
前馈神经网络
神经网络单元
矩阵向量表示法
输出层
从数据中学习
主题分类
主题分类 - 改进
作者署名
语言模型(回顾,前面的几篇讲过)
作为分类器的语言模型
前馈神经网络语言模型
词嵌入
何苦?
POS 标记/词性标注
前馈神经网络来用于标记
卷积网络
卷积网络用于NLP
总结
深度学习
• 机器学习的一个分支
• 重新命名神经网络
• 神经网络:历史上受到大脑计算方式的启发
‣ 由称为神经元的计算单元组成
• 为什么深? 许多层在现代深度学习模型中链接在一起
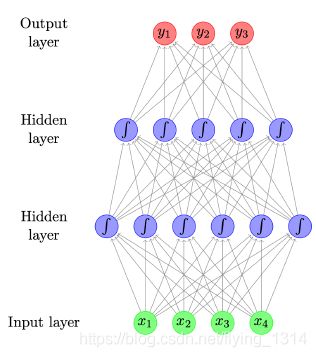
前馈神经网络
• 又名多层感知器
• 每个箭头都有重量,反映了它的重要性
• Sigmoid 函数表示非线性函数
神经网络单元
• 每个“单元”都是一个函数
‣ 给定输入 x,计算实值(标量)h
![]()
‣ 缩放输入(使用权重,w)并添加偏移量(偏差,b)
‣ 应用非线性函数,例如逻辑 sigmoid、双曲 sigmoid (tanh) 或整流线性单元relu

矩阵向量表示法
‣ 通常有多个隐藏单元,即
![]()
‣ 每个都有自己的权重 (wi) 和偏置项 (bi)
‣ 可以使用矩阵和向量运算符表示
![]()
‣ 其中 W 是包含权重向量的矩阵,而 b 是所有偏置项的向量
‣ 非线性函数按元素应用
输出层
• 二元分类问题(例如,对推文的情绪是正面还是负面进行分类):
‣ sigmoid 激活函数(又名逻辑函数)
• 多类分类问题(例如对文档的主题进行分类)
‣ softmax 确保概率 > 0 且总和为 1
从数据中学习
• 如何从数据中学习参数?
• 根据模型分配给正确输出的概率,考虑模型“拟合”训练数据的程度
‣ 想要最大化总概率,L
‣ 等效地最小化 -log L 关于参数
• 使用梯度下降训练
‣ tensorflow、pytorch、dynet 等工具使用 autodiff 自动计算梯度
主题分类
• 给定一个文档,将其分类为一组预定义的主题(例如经济、政治、体育)
• 输入:词袋
| word1 | word2 | word3 | |
| doc1 | 词频 | ||
| doc2 |
如上表就是个简单的词袋。
主题分类 - 改进
• + 一袋二元组作为输入
• 预处理文本以对单词进行词形还原并删除停用词
• 我们可以使用 TF-IDF 或指标(0 或 1 取决于单词的存在)对单词加权,而不是原始计数
作者署名
• 给定一份文件,推断其作者的身份或作者的特征(例如性别、年龄、母语)
• 在此任务中,文本的文体属性比内容词更重要
‣ 词性标签和虚词(例如on、of、the、and)
• 功能词的良好近似:大型语料库中最常用的前 300 个词
• 输入:虚词袋、词性标签袋、词性二元词袋、三元词袋
• 词权重:密度(例如一个文本窗口中虚词与实词的比例)
• 其他特征:连续功能词之间的距离分布
语言模型(回顾,前面的几篇讲过)
• 为单词序列分配概率
• 框定为句子上的“滑动窗口”,从有限的上下文中预测每个单词
例如,n = 3,一个三元组模型

• 根据频率计数进行训练(估计)
‣ 少见事件难处理需要 → 平滑
作为分类器的语言模型
LM语言模型 可以被认为是简单的分类器,例如 三元模型对序列中可能的下一个词进行分类。
前馈神经网络语言模型
• 使用神经网络作为分类器进行建模
‣ 输入特征 = 前两个词
‣ 输出类 = 下一个词
• 如何表示单词? 嵌入
词嵌入
• 将离散的词符号映射到相对低维空间中的连续向量
• 词嵌入允许模型捕捉词之间的相似性
‣ 狗与猫
‣ 步行与跑步
• 缓解数据稀疏问题
何苦?
• Ngram LM
‣ 训练成本低(仅计算计数)
‣ 稀疏和扩展到更大上下文的问题
‣ 没有充分捕捉单词的属性
(语法和语义相似性),例如,电影对电影
• NNLM 深度网络语言模型更稳健
‣ 通过低维嵌入强制词
‣ 自动捕获词属性,导致更稳健的估计
‣ 灵活:微小变化以适应其他任务(标记)
POS 标记/词性标注
•POS 标记也可以被框定为分类:
对特定单词的可能 POS 标签进行分类。
• 为什么不使用更高级的分类器? (神经网络)
• NNLM 架构可以直接适应任务
前馈神经网络来用于标记
• MEMM 标注器作为输入:
‣ 最近的单词 ![]()
‣ 最近的标签![]()
• 和输出:当前标签 ![]()
• 框架作为神经网络
‣ 5 个输入:3 个词嵌入和 2 个标签嵌入
‣ 1 个输出:大小为 |T| 的向量,使用 softmax
卷积网络
• 常用于计算机视觉
• 确定指示性本地预测变量
• 组合它们以生成固定大小的表示
卷积网络用于NLP
• 在序列上滑动窗口(例如 3 个字)
• W = 卷积滤波器(线性变换+tanh)
• max-pool 生成固定大小的表示
总结
• 神经网络
‣ 对单词变体、错别字等的鲁棒性
‣ 优秀的泛化能力
‣ 灵活——针对不同任务的定制架构
• 缺点
‣ 比经典 ML 模型慢得多,但 GPU 加速
‣ 由于词汇量大小,参数很多
‣ 数据饥渴,在小数据集上不太好
‣ 对大型语料库进行预训练有帮助
OK,辛苦大家观看,有问题欢迎评论区交流!