关于 Deformable DETR 中的 valid_ratio
前一阵有社区小伙伴提问,有关 Deformable DETR 中的 valid_ratio 的问题。我也曾经有非常相似的疑问,在这里码字做一些整理,希望能帮到一些朋友理解这个问题,也欢迎大家一起讨论。
DETR中为什么会有特征mask
DETR允许输入的 batch 中的图片具有不同的尺寸,如下图,我们选择coco train中的000000000009.jpg(640x480) 和 000000000078.jpg(612x612) 两张图像作为输入
DETR特制的 collate_fn 会在两张图的右侧和下侧 padding (padding到640x612),来对齐两张图的尺寸,相关逻辑在此。
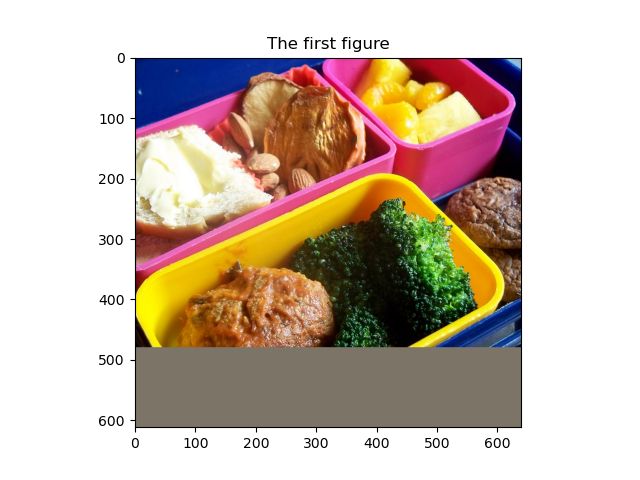
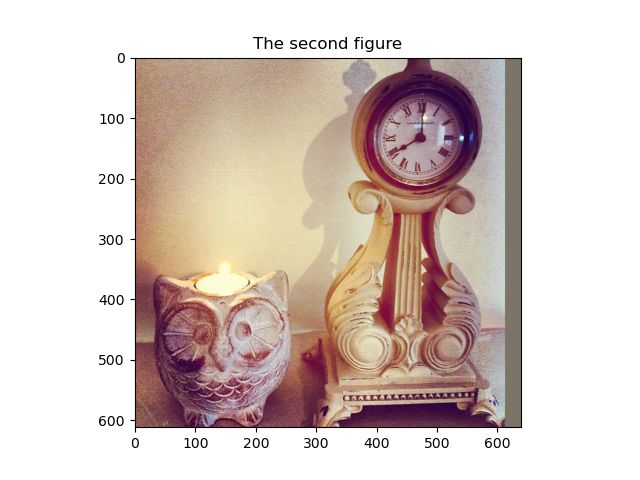
但是 padding 的部分毕竟不是图像部分,且DETR需要对图像进行位置编码,如果不知道哪里是padding的部分可能会影响位置编码。在计算attention的时候,Transformer也不应该关注这些padding的部分。
所以 DETR 用 掩码 mask 记录了 padding 的位置,并设计了 NestedTensor 让每个 tensor 都附带着自己对应的 padding mask。在 mmdet 的实现(目前仍在refactor-detr分支中)中,我们没有沿用 NestedTensor 的设计,而是在 pre_encoder() 中根据 batch_data_samples 的信息构建了这个 mask。
要注意,不光输入的images是有对应的mask的,每层特征也是有对应mask的。DETR在 backbone 中直接对特征图用F.interpolate 进行下采样,相关逻辑在此。所以backbone的每个特征都具有对应的mask,也就是代码里的 mlvl_masks。mask中的每个值与特征图的像素点(也是sequence的一个token)一一对应,True就表明这里是padding的部分,不应该参与attention的计算,False就表明这里是图像的部分,应当被用于计算attention。
什么是valid_ratio,为什么会有valid_ratio
valid_ratio 的 定义:
|---> valid_W <---|
---+-----------------+-----+---
A | | | A
| | | | |
| | | | |
valid_H | | | |
| | | | H
| | | | |
V | | | |
---+-----------------+ | |
| | V
+-----------------------+---
|---------> W <---------|
The valid_ratios are defined as:
r_h = valid_H / H, r_w = valid_W / W
这里这张图可以是 batch_input,也可以是任意一个 level 的 feature。如果用 real_feat 表示没有被 padding 的部分,用 padded_feat 表示整个padding后的图。那么valid_ratio 可以理解为 real_feat 的宽高比 padded_feat 的宽高。
例如上述的图像中(480, 640 & 612, 612 ---- padding ----> 612, 640):
假设用backbone后 3 层 feature map,两张图在各个level的padded_feat的尺寸都分别为 : (77, 80), (39, 40), (20, 20)。这三层的下采样倍率一般是 8x, 16x, 32x,因为无法整除,所以真实的下采样倍率是要看卷积过程的。
(480, 640) 图中,各个level的 real_feat 的尺寸实际是 (61, 80), (31, 40), (16, 20);
计算后 valid_ratios 分别为: [1.0000, 0.7922], [1.0000, 0.7949], [1.0000, 0.8000]],
(612, 612) 图中,各个level的 real_feat 的尺寸实际是 (77, 77), (39, 39), (20, 20);
计算后 valid_ratios 分别为: [0.9625, 1.0000], [0.9750, 1.0000], [1.0000, 1.0000]
可以看到 不同 level 的 feature 的 valid_ratios 是不同的,这是 两个real_feat_shape 和 一个padded_feat_shape的下采样过程不完全同步造成的。你会发现,在大多数情况下,所有的valid_ratio的值中会有一半是1,因为padded_feat总是贴合某个real_feat的长或者某个real_feat的宽。
所以,一定要注意,valid_ratio 一定是某个level和某个样本所特有的。
Deformable DETR 对于 reference points 的先验认识 的 讨论(个人理解):
-
Deformable DETR 预测的box坐标是相对坐标的格式!其取值范围通常为0~1。
预测的 boxes 应当是相对 real_feat 归一化的,因为之后这些bboxes会与 相对 real_feat 归一化的gt_bboxes对比计算loss。
decoder 所输入的和输出的 reference_points 直接对应于预测的boxes (with_box_refine=True时,inter_reference_points本身和预测的box是等值的,只是计算图可能不同)。
所以这部分的 reference_points 是相对于 real_feat 归一化的。
-
MSDeformAttn 所需要输入的 sampling location 应当是相对于 padding_feat 的。
-
MSDeformAttn 需要从不同level找到同一个位置,来实现多尺度特征融合。这里的“同一个位置”代表它们对应在原图上应当具有相同的相对坐标,因此它们相对 real_feat 的相对坐标 应当是对齐的,而不是相对于 padded_feat。
Decoder 的 reference points 过程
decoder 输入的 reference points 是对应于每个 object query 的,可以理解为每个query预测的目标的一个anchor。
注意:它在 as_two_stage 为 True 的时候是 4d 的框,反之为 2d的点。
而中间层输出的 reference points 在 with_box_refine 为 Ture 的时候为 4d 的 框,反之为 2d 的点。
if reference_points.shape[-1] == 4:
reference_points_input = \
reference_points[:, :, None] * \
torch.cat([valid_ratios, valid_ratios], -1)[:, None]
else:
assert reference_points.shape[-1] == 2
reference_points_input = reference_points[:, :, None] * valid_ratios[:, None]
reference_points 为 decoder 的输入,是相对 real_feat 归一化的。reference_points_input 是输入给 layer 里的 attention 的,它应当是相对于 padded_feat 归一化的。所以乘了对应的 valid_ratio。即 absolute_coord / valid_H_or_W * valid_H_or_W / H_or_W,就变成了相对 padded_feat 初始化的啦!~
注意,这里这个归一化 factor 转换的过程是在 decoder_layer 的 for 循环中进行的,每层之间可能进行着的 box_refine,也一定是以 real_feat 为 factor 归一化的,所以每次送进 layer 的 attention 之前,都要进行 归一化因子的转换。
Encoder 的 reference points 过程
encoder 输入的 reference_points 是对应于每个特征像素点的,每个特征本身就是图上的一点,因此其横纵坐标就是其参考点。
注意:encoder 的 reference_points 一直是 2d 的 点。
我把这里的代码改动了一下:
def get_encoder_reference_points(
spatial_shapes: Tensor, valid_ratios: Tensor,
device: Union[torch.device, str]) -> Tensor:
"""
spatial_shapes has shape (num_level, 2).
valid_ratios has shape (batch_size, num_level, 2).
"""
# SECTION A
reference_points_list = []
for lvl, (H_lvl, W_lvl) in enumerate(spatial_shapes):
# STEP 1
ref_y, ref_x = torch.meshgrid(torch.linspace(0.5, H_lvl - 0.5, H_lvl, dtype=torch.float32, device=device),
torch.linspace(0.5, W_lvl - 0.5, W_lvl, dtype=torch.float32, device=device))
# STEP 2
ref = normalize_reference_points(ref_x, ref_y, valid_ratios[:, lvl, :], spatial_shapes[lvl, :])
reference_points_list.append(ref)
reference_points = torch.cat(reference_points_list, 1)
# SECTION B
reference_points = reference_points[:, :, None] * valid_ratios[:, None] # (bs, sum(HW_lvl), num_level, 2)
return reference_points
def normalize_reference_points(ref_x, ref_y, lvl_valid_ratios, lvl_spatial_shape):
H_lvl, W_lvl = lvl_spatial_shape
# valid_ratios: (bs, 2) (newaxis, num_ref) / (bs, newaxis) -> (bs, num_ref), num_ref = HW_lvl
ref_y = ref_y.reshape(-1)[None] / (lvl_valid_ratios[:, None, 1] * H_lvl)
ref_x = ref_x.reshape(-1)[None] / (lvl_valid_ratios[:, None, 0] * W_lvl)
ref = torch.stack((ref_x, ref_y), -1)
return ref
我们把 get_encoder_reference_points 分成两部分,把 SECTION A 又分成了 两个步骤。
SECTION A 中,是在每个 level 下的特征图上,生成每个像素对应的位置的相对坐标。STEP 1 中生成绝对坐标,即 0.5, 1.5, 2.5, …。STEP 2 中将它们归一化,这次归一化的 factor 是它们对应的当前level的 valid_H_or_W * H_or_W,也就是该特征图的 real_feat 的宽高。
有趣的是,对于超出 real_feat 的 zero_padding 的点,该归一化坐标值是 大于 1 的。我认为,**大于1意味着该点对应着 zero_padding 的,本身是没有意义的,因此不需要考虑。**而所有有意义的特征值都是小于1的。
SECTION A 获得了和 decoder_reference_point 一样被 real_feat 归一化的坐标。因此在 SECTION B 中,用 和 decoder 中对2d坐标相同的处理方式(encoder一定是2d)将 reference_points 转换成 以 padded_feat 为 factor 归一化的坐标。
这里看起来容易误解成,在 step 2 中 先除以valid_ratios,又在 SECTION B中乘 valid_ratios,好像是一乘一除会抵消一样,聪明的我们似乎能做的比作者更高效。
实际上我们在SECTION B下面这句话前后打断点就能发现,它们并不是能抵消掉的一乘和一除。前者除的 valid_H_or_W 一定是与参考点对应的哪个 valid_ratio,因为要获取相对坐标,是同 level 相除。但是后者是将获得的位置转化为各个 level 上的归一化坐标,大部分是跨 level 相乘,只有在对角线位置(在当前 level 上)是可以抵消的。所以其实作者在这里的实现非常合理且高效。
一些代码
我在编写回答的过程中编写了一些有关该问题的代码,调试和观察,来帮助我整理思绪进行回答。
给大家分享一下
# By Li-Qingyun (https://github.com/Li-Qingyun) 2022/10/29
from typing import List, Tuple, Union
import numpy as np
import matplotlib.pyplot as plt
import torch
from torch import Tensor, nn
import torchvision.transforms as T
from torchvision.transforms.functional import to_pil_image
import torch.nn.functional as F
from mmcv import imread, imshow
from mmdet.models import build_backbone
@torch.no_grad()
def main():
img1 = imread('000000000009.jpg', channel_order='rgb')
img2 = imread('000000000078.jpg', channel_order='rgb')
backbone = MMDetResNet50BackboneWrapper()
batch_input_tensor, batch_input_mask = get_batch_input([img1, img2])
show_one_tensor(batch_input_tensor[0], 'The first figure', 'The_first_figure.png')
show_one_tensor(batch_input_tensor[1], 'The second figure', 'The_second_figure.png')
show_one_mask(batch_input_mask[0], 'The first mask', 'The_first_mask.png')
show_one_mask(batch_input_mask[1], 'The second mask', 'The_second_mask.png')
feat, feat_mask = backbone(batch_input_tensor, batch_input_mask)
# (bs, num_level, 2)
valid_ratios = torch.stack([get_valid_ratio(m) for m in feat_mask], 1)
# (num_level, 2)
spatial_shapes = torch.stack([torch.as_tensor(f.shape[2:]) for f in feat], dim=0)
print(f'Feat spatial shapes: {spatial_shapes}')
print(f'Valid ratios: {valid_ratios}')
# ENCODER
# (bs, num_reference_points, num_level, 2)
encoder_reference_points = get_encoder_reference_points(
spatial_shapes, valid_ratios, device=feat[0].device)
# DECODER (300 queries)
refpoint_embed = nn.Embedding(300, 2).weight
refpoint_embed = refpoint_embed.unsqueeze(0).repeat(len(batch_input_tensor), 1, 1)
decoder_input_reference_points = refpoint_embed.sigmoid()
decoder_reference_points = decoder_process_reference_points(decoder_input_reference_points, valid_ratios)
return
def get_encoder_reference_points(
spatial_shapes: Tensor, valid_ratios: Tensor,
device: Union[torch.device, str]) -> Tensor:
"""Get reference point for the Deformable Detr Transformer encoder.
Modified from mmdet/models/layers/transformers/deformable_detr_transformer.py
of OpenMMLab 2.0.
spatial_shapes has shape (num_level, 2).
valid_ratios has shape (batch_size, num_level, 2).
"""
# 获取各层特征图中每个像素点相对于Valid值的相对坐标作为reference_points
reference_points_list = []
for lvl, (H_lvl, W_lvl) in enumerate(spatial_shapes):
# Each has shape (H_lvl, W_lvl).
ref_y, ref_x = torch.meshgrid(
torch.linspace(
0.5, H_lvl - 0.5, H_lvl, dtype=torch.float32, device=device),
torch.linspace(
0.5, W_lvl - 0.5, W_lvl, dtype=torch.float32, device=device))
ref = normalize_reference_points(
ref_x, ref_y, valid_ratios[:, lvl, :], spatial_shapes[lvl, :])
reference_points_list.append(ref)
reference_points = torch.cat(reference_points_list, 1)
# 在各个level将上面获得的valid归一化的坐标转化为相对于当前level的padded feature的相对坐标
# 默认认为,各个level的valid部分是aligned。
# (bs, sum(HW_lvl), num_level, 2)
reference_points = reference_points[:, :, None] * valid_ratios[:, None]
return reference_points
def normalize_reference_points(ref_x, ref_y, lvl_valid_ratios, lvl_spatial_shape):
H_lvl, W_lvl = lvl_spatial_shape
# The ref_xy of
# valid_ratios: (bs, num_level, 2)
# (newaxis, num_ref) / (bs, newaxis) -> (bs, num_ref), num_ref = HW_lvl
ref_y = ref_y.reshape(-1)[None] / (
lvl_valid_ratios[:, None, 1] * H_lvl)
ref_x = ref_x.reshape(-1)[None] / (
lvl_valid_ratios[:, None, 0] * W_lvl)
ref = torch.stack((ref_x, ref_y), -1)
return ref
def decoder_process_reference_points(reference_points, valid_ratios):
# reference_points 是相对于valid图的特征
if reference_points.shape[-1] == 4:
reference_points_input = \
reference_points[:, :, None] * \
torch.cat([valid_ratios, valid_ratios], -1)[:, None]
else:
assert reference_points.shape[-1] == 2
reference_points_input = reference_points[:, :, None] * valid_ratios[:, None]
return reference_points_input
def get_batch_input(imgs: List[np.ndarray]):
pre_process = T.Compose([
T.ToTensor(),
T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
imgs = [pre_process(img) for img in imgs] # List[Tensor]
batch_input_tensor, batch_input_mask = nested_tensor_from_tensor_list(imgs)
img_shape_list = [img.shape[1:] for img in imgs]
batch_input_shape = batch_input_tensor.shape[:2]
return batch_input_tensor, batch_input_mask
def nested_tensor_from_tensor_list(tensor_list: List[Tensor]):
# Modified from https://github.com/fundamentalvision/Deformable-DETR/util/misc.py
for tensor in tensor_list:
assert tensor.ndim == 3
def _max_by_axis(the_list: List[List[int]]) -> List[int]:
maxes = the_list[0]
for sublist in the_list[1:]:
for index, item in enumerate(sublist):
maxes[index] = max(maxes[index], item)
return maxes
max_size = _max_by_axis([list(img.shape) for img in tensor_list])
batch_shape = [len(tensor_list)] + max_size
b, c, h, w = batch_shape
dtype = tensor_list[0].dtype
device = tensor_list[0].device
tensor = torch.zeros(batch_shape, dtype=dtype, device=device)
mask = torch.ones((b, h, w), dtype=torch.bool, device=device)
for img, pad_img, m in zip(tensor_list, tensor, mask):
pad_img[: img.shape[0], : img.shape[1], : img.shape[2]].copy_(img)
m[: img.shape[1], :img.shape[2]] = False
return tensor, mask
class MMDetResNet50BackboneWrapper(nn.Module):
def __init__(self) -> None:
super().__init__()
config = dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=False),
norm_eval=True,
style='pytorch',
init_cfg=dict(type='Pretrained',
checkpoint='torchvision://resnet50'))
self.backbone = build_backbone(config)
def forward(self, batch_input_tensor: Tensor,
batch_input_mask: Tensor) -> Tuple[List[Tensor], List[Tensor]]:
mlvl_feats = self.backbone(batch_input_tensor)
mlvl_masks = [
F.interpolate(batch_input_mask[None].float(),
size=feat.shape[-2:]).to(torch.bool).squeeze(0)
for feat in mlvl_feats]
return mlvl_feats, mlvl_masks
def show_one_mask(bool_mask: Tensor, title: str = None,
save_path: str = None) -> None:
assert bool_mask.ndim == 2
color_map = np.array([[255, 244, 210], [244, 239, 255]])
float_mask_ndarray = bool_mask.numpy().astype(np.float64)
float_inv_mask_ndarray = (~bool_mask).numpy().astype(np.float64)
colorful_mask = np.matmul(float_mask_ndarray[..., None], color_map[0][None]) + \
np.matmul(float_inv_mask_ndarray[..., None], color_map[1][None])
colorful_mask = colorful_mask.astype(np.uint8)
plt.imshow(colorful_mask)
if title is not None:
plt.title(title)
if save_path is not None:
plt.savefig(save_path)
else:
plt.show()
def show_one_tensor(normed_tensor: Tensor, title: str = None,
save_path: str = None) -> None:
normed_tensor = normed_tensor.clone()
def _inv_normalize(tensor: Tensor, mean:List[float] = [0.485, 0.456, 0.406],
std: List[float] = [0.229, 0.224, 0.225]) -> Tensor:
assert len(mean) == 3 and len(std) == 3
dtype = tensor.dtype
mean = torch.as_tensor(mean, dtype=dtype, device=tensor.device)
std = torch.as_tensor(std, dtype=dtype, device=tensor.device)
if mean.ndim == 1:
mean = mean.view(-1, 1, 1)
if std.ndim == 1:
std = std.view(-1, 1, 1)
return tensor.mul_(std).add_(mean)
img_tensor = _inv_normalize(normed_tensor)
img = to_pil_image(img_tensor)
plt.imshow(img)
if title is not None:
plt.title(title)
if save_path is not None:
plt.savefig(save_path)
else:
plt.show()
def get_valid_ratio(mask: Tensor) -> Tensor:
"""
Copied from mmdet/models/detectors/deformable_detr.py of OpenMMLab 2.0.
Get the valid radios of feature map in a level.
.. code:: text
|---> valid_H <---|
---+-----------------+-----+---
A | | | A
| | | | |
| | | | |
valid_W | | | |
| | | | W
| | | | |
V | | | |
---+-----------------+ | |
| | V
+-----------------------+---
|---------> H <---------|
The valid_ratios are defined as:
r_h = valid_H / H, r_w = valid_W / W
They are the factors to re-normalize the relative coordinates of the
image to the relative coordinates of the current level feature map.
Args:
mask (Tensor): Binary mask of a feature map, has shape (bs, H, W).
Returns:
Tensor: valid ratios [r_w, r_h] of a feature map, has shape (1, 2).
"""
_, H, W = mask.shape
valid_H = torch.sum(~mask[:, :, 0], 1)
valid_W = torch.sum(~mask[:, 0, :], 1)
valid_ratio_h = valid_H.float() / H
valid_ratio_w = valid_W.float() / W
valid_ratio = torch.stack([valid_ratio_w, valid_ratio_h], -1)
print(f"Valid_H & H & Valid_W & W: {valid_H} {H} {valid_W} {W}")
return valid_ratio
if __name__ == '__main__':
main()