联合综述《Deep Learning》阅读笔记
Deep Learning 阅读笔记
文章介绍
作者:
作者:Yann LeCun、Yoshua Bengio 、Geoffrey Hinton。
三人被称为深度学习三巨头,共获2018年图灵奖。
2015年为纪念人工智能提出60周年,《Nature》杂志专门开辟了一个“人工智能 + 机器人”专题 ,发表多篇相关论文,其中包括了Yann LeCun、Yoshua Bengio和Geoffrey Hinton首次合作的这篇综述文章“Deep Learning”
文章被引用次数:24488 。访问次数:658k。
文章分几部分,我主要对 【图像理解与深度卷积网络】、【卷积神经网络】、【反向传播训练多层结构】、【监督学习 】 ,部分精读,其余部分粗略观看,待之后按需祥读。
表示学习与传统特征工程对比
机器学习技术为现代社会的许多方面提供动力: 从网络搜索到社交网络上的内容过滤,再到电子商务网站上的推荐,它越来越多地出现在摄像头和智能手机等消费产品中。机器学习系统用于识别图像中的对象,将语音转换为文本,将新闻项目、帖子或产品与用户的兴趣相匹配,并选择相关的搜索结果。这些应用程序越来越多地使用一种叫做深度学习的技术。
随着机器学习在应用上的推广,各行各业越来越多的应用和程序都采用了深度学习技术。
传统机器学习、特征工程
几十年来,传统的机器学习在处理自然数据的原始形式时通常需要大量的工程学以及专业领域知识来设计一个特征提取器,将自然数据转换为特征向量或内部表示。再通过一个分类器,从输入的特征向量得到结果。
深度学习 – 表示学习
Representation learning is a set of methods that allows a machine to be fed with raw data and to automatically discover the representations needed for detection or classification.
表示学习是借助算法让机器自动地学习有用的数据和其特征。深度学习方法是具有多层次表示的表示学习方法,通过组合简单但非线性的模块,每个模块将一个层次的表示(从原始输入开始)转换成一个更高的、稍微抽象的层次。
例如,以图像为例,图像以像素值数组的形式出现。
- 第一层表示中的习得特征通常表示图像中特定方向和位置的边缘的存在或不存在。
- 第二层通常通过识别特定的边缘排列来检测图案,而不管边缘位置的微小变化。
- 第三层可以将图案组合成更大的组合,对应于熟悉的物体的部分,接下来的层可以检测到这些部分的组合。
深度学习的关键在于,这些层次的特性不是由人类工程师设计的: 它们是通过一个通用的学习过程从数据中学习的。
优点
解决了传统机器学习难以处理自然数据的原始形式时的缺点,不需要由人手动去进行特征工程。而让机器直接学习有用的特征。
缺点
需要大量的数据集支持。
深度学习解决了阻碍人工智能领域已久的问题,它在各个领域都取得了成功且在表现上比其他机器学习技术都要好。如在图像识别、语音识别、预测潜在药物活性,分析粒子加速器领域等等。
总结:
- 传统机器学习需要精心设计特征抽取器,而这个过程往往需要大量的专业技能和丰富的邻域知识;
- 深度学习则可以避免这一繁琐的过程:特征可以通过学习算法自动学习得到;★
- 通过多个非线性层组合(例如5-20层),系统可以敏锐观察到图像中的关键部分,忽略非关键部分;
- 这正是深度学习的关键之处。
监督式学习(Supervised learning)
监督学习就是给定数据和相应的标签,神经网络可以通过数据以及相应的标签去学习数据中的特征,最终达到输出相应结果的目的。
首先设计一个待定参数(权重)的模型,以及一个衡量输出与期望之间的差距的成本函数(cost funciton)。机器学习过程中会根据损失函数不断的调整模型中的可矫正参数,即权重。
为了恰当的调整权重,可以看做求损失函数最小的参数值,主要用到梯度下降法。在实践中一般采用随机梯度下降法(stochastic gradient descent)。
非线性核(non-liner kernal)
一个深度学习框架是简单模块的多层堆叠,其所有(或大多数)的目标是学习,并且很多是在计算非线性的输入输出映射关系。这些堆叠中每个模块都在转换其输入来同时增加分离度和表达的不变性。有5到20层的多层非线性层的系统,系统可以变成既对一些细节很敏感的复杂函数——能够从白色的狼中区分出萨摩耶,又对大型的不相关变量不敏感,例如背景,姿势,光照和周围的物体。
之前在用的机器学习方法多为使用手工设计的特征来构造线性分类器,线性分类器将他们的输入空间分为非常简单的区域,也就是超平面分割的半空间。但是图像或者语音识别等问题需要输入输出函数忽视输入的无关信息,比如位置,朝向,目标的光照,或者演讲中口音或者音调的变化。但是需要对一些细微信息特别的敏感。
但为了使分类器更强大,可用通用非线性特征,如核方法( kernel methods)。
用准确的话总结就是,深度学习是机器学习的一个子领域,它使用了多层次的非线性信息处理和抽象,用于有监督或无监督的特征学习、表示、分类和模式识别。
反向传播训练多层结构 Backpropagation to train multilayer architectures
反向传播计算是链式求导法则的一个实际应用,它使得目标函数对于模型输入的求导,可以通过对模型输出的导数的回传来求得,即反向传播。反向传播的等式可以被反复应用于贯穿整个网络的从顶部的输出(模型产生预测的地方)一路到底部的输入(外部输入的地方)的梯度传播。
而在计算出这些梯度后,就可以直接计算并更新每个模块的参数。
- ReLU一般会使多层神经网络学习的更快, 可让一个深度网络直接进行有监督的训练, 而不须要无监督的pre-training.
- 隐含层的做用能够看做是使用一种非线性的方式来扭曲(distorting)数据, 使得最后一层变得线性可分.
- 在90年代, 人们广泛认为, 梯度降低方法容易陷入很差的局部极小值(local minimum), 且认为, 学习有用的、多级层次结构的、使用较少先验知识进行特征提取的方法不靠谱,仍然比较信任由特征工程来做的人工特征提取。
- 实际上,在大规模神经网络中, 局部极小值不是问题 , 不论是使用什么样的初始条件,系统老是能够获得效果差不多的解。相反, 解空间中存在着大量的鞍点, 且大多数鞍点的值都有和目标函数差不多的值。因此,即使算法陷入这些鞍点也没有太大的问题。
- 非监督式学习的初始化方法: 使用不带标签的数据, 训练出可以使得“高层的特征抽取结果能够还原出底层数据”的参数.
神经网络模型与反向传播
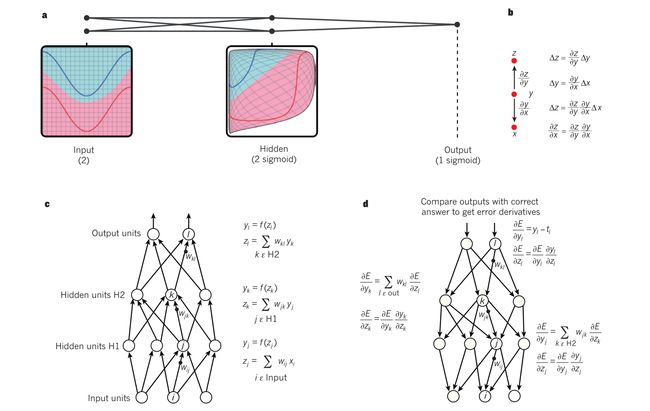
上图为多层神经网络以及反向传播
在上图中,输入节点有两个,输出节点有两个。 整个神经网络模型由一个输入层、两个隐藏层、一个输出层。
隐藏层可以被看作是以非线性方式扭曲输入空间的,所有类别就变得可以被输出层线性分离。
c c c 图介绍了神经网络的前向传播通路,为了简便叙述,作者省略了偏置项。为了之后的反向传播,每一层都有可以反向传播梯度的模块。在每一层中,我们首先计算每一个节点的总输入z,即上一层输出的加权和。然后将非线性函数作用于z就得到这个节点的输出。
KaTeX parse error: No such environment: align at position 8: \begin{̲a̲l̲i̲g̲n̲}̲ yj = f(z_j) \\…
这里的 f ( ⋅ ) f(\cdot) f(⋅) 即非线性函数,输入为上一层输出的加权和。在神经网络中使用的非线性函数包括:Relu 、sigmoids、logistic function。
Relu: f ( z ) = m a x ( 0 , z ) f(z) = max(0,z) f(z)=max(0,z)
sigmoids: f ( z ) = e x p ( z ) − e x p ( − z ) e x p ( z ) + e x p ( − z ) f(z) = \frac{exp(z) - exp(-z)}{exp(z)+exp(-z)} f(z)=exp(z)+exp(−z)exp(z)−exp(−z)
logistic function: f ( z ) = 1 1 + e x p ( − z ) f(z) = \frac{1}{1+exp(-z)} f(z)=1+exp(−z)1
反向传播:
在每一个隐藏层,我们计算误差对于每一个节点输出的偏导,它是误差对上一层输入的偏导的加权和。我们通过乘以 f ( z ) f(z) f(z)的梯度将误差对输出的偏导转换成对输入的导数。在输出层,误差对于每一个节点输出的偏导是通过对成本函数(cost function) 求导取得的。
卷积神经网络 Convolutional neural networks
卷积网络是被设计用来处理多阵列数据的,例如一张包含三通道2维彩色像素强度队列的图片。卷积网络利用自然信号的特性时背后的四个关键信息:局部连接,权值共享,池化和多层结构。
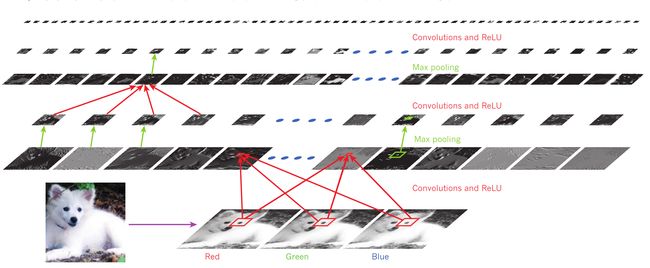
上图是对于一个萨摩耶图像的典型卷积神经网络。左下为原图,右下为其RGB三通道图像。可将其三通道看为三个输入,对应上上图神经网络模型中的 x 1 , x 2 , x 3 x_1,x_2,x_3 x1,x2,x3。
网络模型由一层带Relu的卷积层加一层池化层、一层带Relu的卷积层加一层池化层循环组成。每个矩形图像是一个特征映射(feature map),对应于在每个图像位置检测到的一个学习特征的输出。信息自底向上流动,底层特征作为定向边缘检测器,并计算输出中每个图像类的得分。
卷积神经网络的最小组成由两部分:卷积层和池化层。
每一层通过一组权值与上一层的特征图的 local path 相连。这些节点的局部加权和再通过了一个非线性函数如Relu函数。如上图是 Convolutions 加 Relu 函数。一个特征图中所有的单元都共享权值。不同的特征图使用不同的权值,即 filter banks,也叫 卷积核(Convolution Kernel)。
故一个卷积核对应一个特征图。在数学上,由特征映射(feature map)执行的滤波操作是离散卷积,因此得名卷积神经网络。
卷积层的功能:
- 是检测前一层特征的局部连接
池化层作用:
- 合并语义上相似的特征。
- 减少表达的维数,创造了对于微小唯一以及扭曲的不变性。
卷积神经网络训练方式:
卷积神经网络的训练同普通的深度网络一样使用方向传播算法即可训练卷积神经网络中所有卷积核的权重。
深度学习探究了自然信号组成特征的层级特性,高级特征由低级特征组合而成。在图片中,边缘的局部组成了图案,图案组成了部分,部分组合成了物体。
使用深度卷积网络的图像理解( Image understanding with deep convolutional networks)
这一节主要介绍了卷积神经网络在各领域上的应用,以及提到了一些应用于图像领域的技术。
卷积神经网络被应用在物体和区域检测、分割和识别上,并取得了巨大的成功。比如交通标志的识别,生物图像的识别、神经组的分割,自然图像中的人脸,文字,行人和人体的检测。其中最重要的一个成功即在人脸识别领域上的成功。在将来,卷积神经网络在自动移动机器人、自动驾驶汽车等方面也有很大前景。
2012年 AlexNet 的提出,有效使用了GPU、Relu函数,以及提出了一种称为 dropout 的规则化技术,通过扭曲和截取原有图片来获得更多训练数据的技术取得了惊人的成果,带来了一场计算机视觉领域的革命。几乎在所有检测和识别项目上卷积神经网络都是最具优势的方法,并在一些方面性能几乎接近人类。