贝叶斯分类器的MapReduce实现(VMware + Hadoop)
写在前面:
学校课程要求用 Hadoop 实现朴素贝叶斯分类,这里总结了下大致的操作流程,帮助大家快速入门。
使用的是 windows 10,vmware15.5,ubuntu18.04.1,hadoop2.7.7
1、安装准备
1.1 VMWare + Ubuntu 安装
VMware只是一个虚拟机,需要在其中继续安装使用的操作系统。网上很多教程使用的操作系统为 centos,但是个人感觉如果使用图形化界面的话,占空间比较大,安装也不是很简便(主要是我不熟hhh),所以使用了比较拿手的 ubuntu。
如果非常倔强地使用了centos,或许可以参考这篇?(感觉很详细,而且是从 centos 下载开始讲解的):https://blog.csdn.net/m0_46413065/article/details/114667174?spm=1001.2014.3001.5501
具体的操作步骤可以参考微信公号 软件管家 的:https://mp.weixin.qq.com/s/vuaPF25PUVywgAA0tEvr8w
在使用上述的安装教程后,发现无法联网???需要在设置界面,打开硬件选项卡,在左边选择"网络适配器",然后在右边选择"NAT模式(N):用于共享主机的IP地址",点击确定。
参考这篇:https://blog.csdn.net/zhyulo/article/details/78730009
为了之后能非常快乐地使用VMware,在它弹出什么更新?之类的(记不太清了,总之是更新语言的)就无脑同意,让它自己麻溜地赶紧操作。下面是张截图:

还有就是要安装 VMWare tools,可以解决主窗口中的虚拟机窗口太小的问题,参考这篇:https://www.jianshu.com/p/9fca51d0d120
win11好像这时候还是不能复制粘贴、拖拽文件,参考这个:https://blog.csdn.net/weixin_50406679/article/details/126112735(我只用了前两部分就可以了)
大功告成!!!这样装完以后,就可以联网,可以输入中文,可以直接从win10拖拽文件过来,还可以用复制粘贴了!!!(在 VMware 中复制粘贴的快捷键可能不同)
1.2 Hadoop 集群安装
主要是根据这篇,简单而且没有缺少步骤什么的:https://www.jb51.net/article/209042.htm#_label11
但是有的地方不是很清楚,建议使用上面的教程,如果有疑问,再学习下面这两个(这两个相当于一篇的上下):
http://dblab.xmu.edu.cn/blog/install-hadoop/、http://dblab.xmu.edu.cn/blog/install-hadoop-cluster/
下面理一下基本思路和注意点:
- 众所周知,配环境堪称玄学,所以在配置环境前,可以将装好的非常完美的系统先存一份,即克隆一份原来的系统为 master,再克隆两份原来的系统为 node,原来的保留不变。【为了避免一些不必要的错误,建议这一步就克隆好三台,然后重复操作后面的步骤。不要图省事,操作一番相同的步骤,再克隆】
- 创建Hadoop用户(在master,node1,node2执行):这里注意,虽然创建了用户,但是如果中途退出又重新登录的话,不要选新创建的Hadoop用户!!!还是登录最开始的那个用户,然后在黑框中用 su hadoop 命令,切换到hadoop用户。因为直接用 hadoop用户 登录,虽然之前已经添加了权限,但是似乎还是权力不够大(毕竟权力是头头给的hhh),印象中会出错,而且还不能使用之前账户的软件。
- 更新apt下载源;安装SSH、配置SSH免密登录(在master,node1,node2执行)
- 安装Java环境 (在master,node1,node2执行):这里注意,一定要安装 1.8 版本的!!!(具体方式参考第二篇)看到的资料里基本都是这个版本,感觉是因为原系统 win10 中,基本都是这个版本的 jdk。
- 修改主机名、修改IP映射(在master,node1,node2执行)
- SSH免密登录其他节点(在master 和 node1,node2上执行不同):这个最好一次成功,因为重复操作的话,会发现 node 存公匙的文件中,那些公匙是一直存在的,不会覆盖(本强迫症不接受!)
- 安装hadoop(在master中执行):这里我装的是hadoop2.7.7,似乎也有点影响,建议装 2.7 版本的。
- 配置hadoop环境(在master中执行):这一步需要很仔细,第一篇有些不清楚,可以综合两篇进行配置。
- 启动、关闭hadoop集群(在master上执行)
2、实验要求&基础知识
项目内容:
- 用MapReduce算法实现贝叶斯分类器的训练过程,并输出训练模型;
- 用输出的模型对测试集文档进行分类测试。测试过程可基于单机Java程序,也可以是MapReduce程序。输出每个测试文档的分类结果;
- 利用测试文档的真实类别,计算分类模型的Precision,Recall和F1值。
实验数据:
数据在 NBCorpus 文件夹中,分为 Country 和Industry 类,这两个文件夹代表不同的分类,点开后又分别为多个子文件夹(这些子文件夹就是数据使用的基本单位了),每个子文件夹代表这个方面的多篇文章,里面的每个 .txt 文件为一篇文章分词后的结果。
后续需将每个类别中的文档随机分为训练集和测试集,训练集占70%,测试集占30%(比例看个人设置)
朴素贝叶斯原理:
实验之所以设置为贝叶斯,是因为 Bayes 不需要多次迭代,而 k-means 需要。
使用朴素贝叶斯方法进行文档分类,需要从给定的类别标签集合 C={c1,c2,…,cj} 中,为待分类文档 d 选择概率最大的标签,即 p(ci | d) 得到使的最大 ci 的作为 d 的分类结果。
可利用如下的贝叶斯公式将分类问题做进一步转化,公式中 p(ci | d) 的为后验概率/条件概率,指给定文档 d 属于类 ci 的概率;p(d | ci) 为似然概率,指给定文档类别 ci,由类别 ci 产生文档 d 的概率;p(ci) 为先验概率,指待分类文档的类别为 ci 的概率;p(d) 此时可看作常量,指词组成文档的概率。
![]()
从上述公式中可以看出,p(ci | d) 只与 p(d | ci) 和 p(ci) 有关,为两者的乘积。只需在训练集数据训练得到这两个数据即可。先验概率 p(ci) 的计算公式如下:
![]()
为便于计算似然概率 p(d | ci),假设文档中的每个term都是相互独立的,文档 d 中有 nd 个term:t1,t2,…,tnd,用 tk 表示某个特定的term,则似然概率 p(d | ci) 的计算公式如下:

3、代码步骤
代码在 github 上可以找到,这里贴两个:
https://github.com/ZhangQi1996/hust_cs_bayes
https://github.com/hutushanren/hadoopTask
在main类中定义和实现整个流程,主要分为四部分(仅提供一种思路):
- 选择数据集,并将其划分为训练集和测试集。本实验使用的数据集包括四个文件夹,其中每个文件夹名即为类别标签,文件夹下的若干文档都属于该类别。根据比例随机将每个文件夹中的.txt文件分为训练集和测试集两部分。
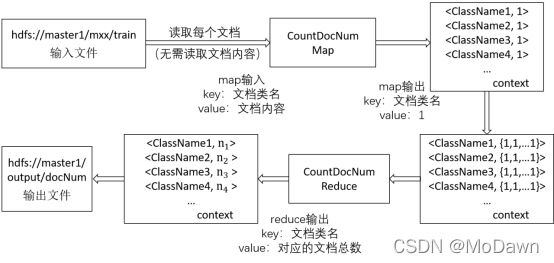
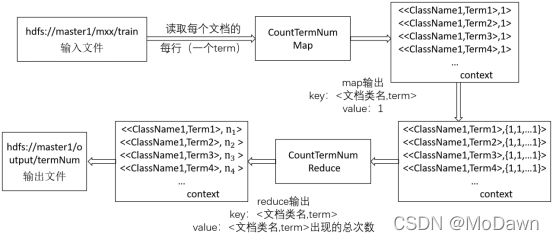
- 根据训练集中的数据,统计出每个类的文件数、每个类中各个term的数目,并将结果保存在相应文件中。这里用到了两个MapReduce Job,记为mr1,mr2。根据两个mr统计得到的数据,可以计算出分类预测所需的先验概率和每个类别中term出现的条件概率。具体的输入输出,以及各自的Data Flow示意图如下:
mr1用来统计训练集中每个类别的文档数目。输入文件是训练集的所有文档(此时不需要读取文件内容),map输出的key为文档类别,value用来计数,都设置为1,可表示为
mr2用来统计每个类别中出现的各个term的数目。输入文件也是训练集的所有文档。map输出的key为文档类别和term,value设置为1,表示该term在此文档类别中出现1次,可表示为<
- 由测试集数据进行预测。先对测试集数据进行处理,然后根据训练得到的结果,求出先验概率和似然概率,计算两者乘积,寻找使后验概率最大的值,以此作为测试集中待分类文档的类别。这里同样用到了两个MapReduce Job,记为mr3,mr4。具体的输入输出,以及各自的Data Flow示意图如下:
mr3用来处理测试集的数据。输入文件是所有测试集,需读取文档内容(每行一个term)。map的输出key为文档类别和文档名,value为对应的term,可表示为<

mr4用来预测测试集中文档的类别。在map和reduce之前,需读入mr1和mr2的输出文件,据此计算先验概率和条件概率,并将结果保存在HashMap中。mr4的输入为mr3的输出。map的输出key为文档类名和文档名,value为预测类名和概率,由公式可得其计算过程:根据mr3输出的value中的分词,获取每个term在每个类下的条件概率,然后计算其乘积,可表示为<

- 对预测结果进行评估。将预测得到的结果和预测集中文档的真实类别相比较,求出精确率precision、召回率recall和F1,据此评价模型的文档分类结果。
4、运行操作
很小白,这里查了很多才明白怎么操作。简单来说,可以有几种方式:
- 直接在 VMware 里下载 eclipse 或 idea。
- 在原系统 win 10 中,使用 eclipse 或 idea,联通 VMware 中的 hadoop。
- 在原系统 win 10 中,使用 eclipse 或 idea,直接打包,拖拽到 VMware 中设置的 master 中。
前两种似乎很难配置,所以用的最后一种。不会的直接搜索怎么 打包maven项目 就可以啦,这一步和hadoop分布式什么的没什么关系。
打包后将生成的 jar包 直接拖拽到 master 中,然后看这个B站的视频学习后面的操作,视频包括 数据的上传 和 jar包的使用(从1:40 看到4:50即可):Hadoop实战——对单词文本进行统计和排序
就是先在主机上启动 hadoop集群,然后就可以在浏览器中访问 htfs文件系统,再将数据上传到 htfs文件系统(创建文件夹后,上传训练集和测试集数据),最后执行 jar包。
因为要对 数据 和 jar包 进行操作,所以最好先进入存放这些的目录下,避免再添加所在目录。下面是我使用的命令行(仅供参考):
hadoop fs -mkdir /文件夹名称
hadoop fs -put train /文件夹名称/
hadoop fs -put test /文件夹名称/
hadoop jar bayes.jar com.bayes.Main