首次在手机端不牺牲准确率实现BERT实时推理,比TensorFlow-Lite快近8倍,每帧只需45ms...


作者 | 王言治
出品 | AI科技大本营(ID:rgznai100)
基于Transformer的预训练模型在许多自然语言处理(NLP)任务中取得了很高的准确度。但是这些预训练模型往往需要很大的计算量和内存。由于移动平台的存储空间以及计算能力的限制,这些模型很难实现在移动端的部署。
因此,在这个边缘计算越来越重要的今天,如何有效的压缩这些大模型成为了一个重要的研究课题。
在过去的一年中,为了减少BERT模型的大小,同时保持多个下游NLP任务的准确性,很多小模型被相继提出。例如,DistilBERT 和TinyBERT是通过减少Transformer Block数量来达到减小模型的目的,然而精确度相比于BERT-base有明显下降。
MobileBERT在BERT-base的基础上,成功的将模型尺寸比减小了4倍,并且保持了较小的精度损失。有意思的是,如果我们将MobileBERT与VGG-16进行对比, MobileBERT的计算量比VGG-16小5.3倍,但计算延迟却比VGG-16的高6.2倍。
造成这种现象的原因是MobileBERT拥有超过2000个计算层(与BERT-large相同),这会在计算过程中产生大量的中间结果,最终导致严重的计算延迟。
这也成为了将拥有较深层的网络模型部署在移动端实现实时推理的另一大阻碍。
因此,我们不禁思考,是否存在一种有效的解决方案,可以在不牺牲BERT模型准确率的情况下,在移动端实现实时推理?
近日,美国东北大学王言治研究组和威廉玛丽学院任彬研究组共同提出了名为CANAO的编译器感知的神经网络结构优化框架,在保持了与BERT原模型相近的准确率的同时,他们成功的将模型大小减少了4.8倍,速度提升了5倍。
相比于TensorFlow-Lite(TFLite), CANAO框架在速度方面提升了7.8倍,延迟仅为45ms,首次实现在手机端的高准确率(几乎不牺牲准确率)、实时自然语言处理任务。

他们将CANAO与三种模型BERT-base, DistilBERT, MobileBERT在准确率和延迟上做了对比。CANAOBERT w/o distill.是直接训练的小模型,CANAOBERT是通过知识蒸馏法训练的模型,CANAOBERT是通过NAS进一步优化模型宽度得到的模型。
可以看出,三个CANAO模型的延迟都小于对比的三种模型。相比于BERT-base,他们的模型在CPU和GPU上分别快了5.2倍和4.1倍,准确率仅降了0.5-2%。相比于MobileBERT, 他们的模型在CPU和GPU上分别快了1.49倍和1.53倍,准确率仅降了0.4-1%。

上表显示了他们的编译器感知的神经网络结构优化框架在DistilBERT,BERT-base以及他们的CANAOBERT模型上取得的效果,并与TFLite框架(只支持移动端CPU)进行了比较。CANAO框架可以分别在CPU和GPU上提升2倍和2.4倍的速度。未进行任何优化的BERT-base模型在TFLite上的运行速度是382ms, 而他们的压缩模型在CANAO框架下最快能达到45ms,速度提升了7.8倍。
他们的研究最先起始于对NLP模型的深度与模型准确率关系的探究。
目前大多数预训练NLP模型都很深,从计算层数来算的话,BERT-base有1000+层,Bert-large和MobileBERT有2000层,这会导致在移动端部署时很高的计算延迟。
那么NLP模型真的需要这么多层数吗?如果需要的话,要如何解决高延迟的问题呢?
模型深度vs模型准确率
首先,对于层数问题,他们做了多组对比实验。如下表所示,在拥有相同的计算量的前提下,他们分别使用了一个深且窄的网络结构和一个浅且宽的网络结构,并进行了准确率的对比,以此来探究模型深度与准确率的关系,这些模型是通过BERT-large蒸馏得到。
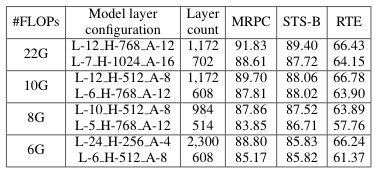
通过对比实验结果可以发现,在相同的计算量下,较深的网络确实比较浅的网络在准确率方面有更好的表现,从而也在一定程度说明了网络深度对于NLP模型的必要性。
那么要如何解决深度带来的高延迟问题呢?
他们提出了CANAO编译器感知的神经网络结构优化框架,其中包括:
1.基于轻量级多项式的层融合技术(Lightweight Polynomial-based Layer Fusion)
2.编译器感知的神经结构搜索技术(Compiler-aware Neural Architecture Search)
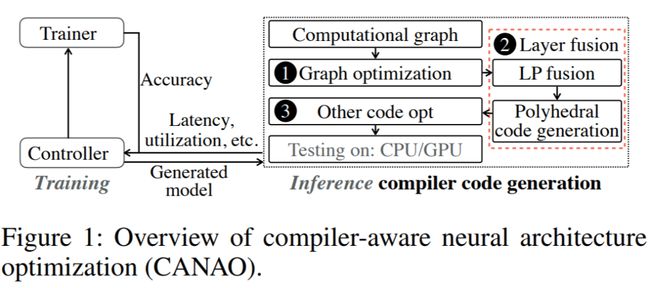
基于轻量级多项式的层融合技术
这是一种基于编译器的优化技术,通过有效的合并多个计算层,来大量减少由多次存取层间结果带来的计算延迟。
编译器感知的神经结构搜索技术
他们是首个将编译器优化信息作为反馈信息加入到神经结构搜索的循环中,来实现对网络模型的协同优化,让模型同时拥有高准确率和低延迟。
虽然使用网络延迟来优化网络结构的硬件感知神经结构搜索(hardware-aware NAS) 已经被提出,但是在NAS和编译器优化之间仍然缺少一些联系。
例如,现有的支持硬件的NAS: MnasNet、FBNet、ProxylessNAS都采用通用的、非优化的编译器。对于具有较浅层数的CV应用来说尚可达到较好的效果,但是对于具有数百甚至数千层的网络,如果没有编译器优化的协助,则很难实现低延迟的目标。
而他们提出的CANAO编译器感知的神经网络结构优化框架可以让搜索出的模型满足编译器优化后的对计算资源的高利用率,从而在保持高准确率的前提下,实现对BERT类模型在移动设备上的实时推断。
Demo视频见详见B站:
【CoCoPIE深度学习】手机实时BERT问答2 On-mobile real-time question answering using BERT
https://www.bilibili.com/video/BV1Wp4y1a7RK
更多技术细节可以查阅文章
https://arxiv.org/abs/2009.06823
结语
在移动手机普及的今天,如何在移动端等资源受限的设备上使用 BERT 模型,是一个极具挑战问题。而CANAO编译器感知的神经网络结构优化框架提供了一个有效的解决方案,它对BERT模型进行结构优化,并在编译器优化的协助下,在移动端实现了高准确率、实时自然语言处理。
作者简介:
王言治是美国东北大学电子与计算机工程系助理教授。他在清华电子系和南加州大学拿到本科和博士学位。他的主要研究方向是深度神经网络的加速与安全性。他们的CoCoPIE压缩编译协同优化框架可以实现大多数神经网络在移动端的实时推理。他的文章广泛发表于各个顶会顶刊,包括机器学习方向AAAI,CVPR,ICML,ICCV,ICLR,IJCAI,ECCV等,电路与设计自动化方向DAC,ICCAD,ISSCC,FPGA等,计算机系统方面ASPLOS,ISCA,MICRO,HPCA,CCS,VLDB,PLDI,ICS,PACT等。他的文章引用超过7200次,得过Google,Mathworks, Intel等研究奖项,得过4项最佳论文奖,另外10次提名,多次设计竞赛奖项。他的研究工作被媒体广泛报道和引用超过400次。他的多位学生已经在各个学校担任教职,包括康涅狄格大学,克莱姆森大学等,工作单位包括谷歌、脸书、腾讯、滴滴(超新星员工)。

更多精彩推荐
-
关于Python 3.9,那些你不知道的事
-
OpenCV 实现视频稳流,附Python与C++代码!| 防抖技术
-
英伟达收购,ARM也要变美国公司,国产芯出路几何?
-
张勇云栖连讲三年,阿里云十年一剑,王者归来