transformer掩码
mask在芯片制造领域应用广泛,靶材镀膜要刻成逻辑电路的结构,无需刻蚀的地方用mask掩盖。
一、padding mask
数据输入模型的时候长短不一,为了保持输入一致,通过加padding将input转成固定tensor。
一句文本输入:[1, 2, 3, 4, 5]
input size: 1* 8
加padding:[1, 2, 3, 4, 5, 0, 0, 0]
padding 引入的问题:padding填充数量不一致,导致均值计算偏离
原始均值:(1 + 2 + 3 + 4 + 5) / 5 = 3
padding后的均值: (1 + 2 + 3 + 4 + 5) / 8 = 1.875
引入mask,解决padding的缺陷:
假设 m = [1, 1 , 1, 1, 1, 0, 0, 0]

如"我 是 谁 P P"这个输入序列来说,前3个字符是正常的,后2个字符是Padding后的结果。因此,其Mask向量便为[True, True, True, False, False]。通过这个Mask向量可知,需要将权重矩阵的最后两列替换成负无穷。

encoder的输入是一行葡萄牙文本全部输入,而decoder的输入是输出反馈时序输入+encoder的输出。
decoder_input
例1
def create_padding_mask(seq):
seq = tf.cast(tf.math.equal(seq, 0), tf.float32)
# add extra dimensions to add the padding
# to the attention logits.
return seq[:, tf.newaxis, tf.newaxis, :] # (batch_size, 1, 1, seq_len)
x = tf.constant([[ 2, 125, 44, 85, 231, 84, 130, 84, 742, 16, 3]])
print(create_padding_mask(x))
tf.Tensor([[[[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]]]], shape=(1, 1, 1, 11), dtype=float32)
广播后+自注意力
mask = create_padding_mask(x)
scaled_attention_logits = tf.random.uniform((1, 8, 11, 11)) # (batch_size, num_heads, sequence_length,sequence_length)
y = scaled_attention_logits + mask* -1e9
print(y.shape)(1, 8, 11, 11)
二、look ahead mask,这类掩码是根据输入文本长度生成的
def create_look_ahead_mask(size):
mask = 1 - tf.linalg.band_part(tf.ones((size, size)), -1, 0)
return mask # (seq_len, seq_len)
例2
x = tf.constant([[2, 81]])
print(tf.shape(x))
print(create_look_ahead_mask(tf.shape(x)[1]))tf.Tensor([1 2], shape=(2,), dtype=int32)
tf.Tensor(
[[0. 1.]
[0. 0.]], shape=(2, 2), dtype=float32)
例3
x = tf.constant([[ 2, 81, 80]])
print(create_look_ahead_mask(tf.shape(x)[1]))tf.Tensor(
[[0. 1. 1.]
[0. 0. 1.]
[0. 0. 0.]], shape=(3, 3), dtype=float32)
例4,d_model=128, num_head=8, 那么单头深度16
def scaled_dot_product_attention(q, k, v, mask):
"""Calculate the attention weights.
q, k, v must have matching leading dimensions.
k, v must have matching penultimate dimension, i.e.: seq_len_k = seq_len_v.
The mask has different shapes depending on its type(padding or look ahead)
but it must be broadcastable for addition.
Args:
q: query shape == (..., seq_len_q, depth)
k: key shape == (..., seq_len_k, depth)
v: value shape == (..., seq_len_v, depth_v)
mask: Float tensor with shape broadcastable
to (..., seq_len_q, seq_len_k). Defaults to None.
Returns:
output, attention_weights
"""
matmul_qk = tf.matmul(q, k, transpose_b=True) # (..., seq_len_q, seq_len_k)
print("\033[1;032m",end="")
print("q*k")
print(q.shape)
print(k.shape)
print(mask.shape)
print(matmul_qk.shape)
print("\033[0m",end="")
# scale matmul_qk
dk = tf.cast(tf.shape(k)[-1], tf.float32)
scaled_attention_logits = matmul_qk / tf.math.sqrt(dk)
# add the mask to the scaled tensor.
if mask is not None:
scaled_attention_logits += (mask * -1e9)
print("\033[1;035m",end="")
print(mask)
print(scaled_attention_logits.shape)
print("\033[0m",end="")
# softmax is normalized on the last axis (seq_len_k) so that the scores
# add up to 1.
attention_weights = tf.nn.softmax(scaled_attention_logits, axis=-1) # (..., seq_len_q, seq_len_k)
print(attention_weights)
print(attention_weights.shape)
output = tf.matmul(attention_weights, v) # (..., seq_len_q, depth_v)
return output, attention_weights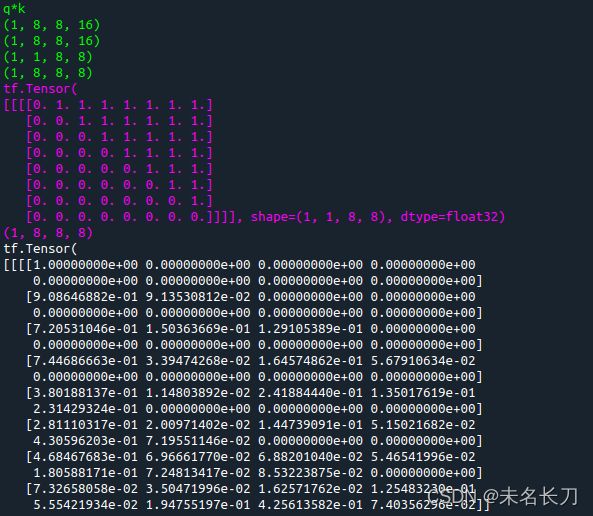
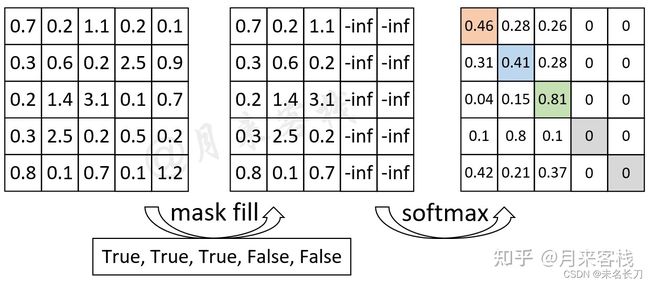
mask在值1加上一个非常大的负数,那么softmax后这些位置全为0,然后×矩阵V


look ahead mask掩码目的是为了计算文本顺序的注意力,如上图所示,计算:
我 + 我
是+我,是+是
是+我,是+是,是+谁
该矩阵右上对称部分掩盖,使得注意力在于文本的顺序,我们知道,mask shelf attention只有decoder才有,而decoder要预测我是谁后面的文字。
另一方面,回到第一节。Padding mask是假设我是谁是文本长度上限,那么PP位置对应的self attention矩阵广播为负无穷,则能够掩盖pading的部分。
参考:
This post is all you need(层层剥开Transformer) - 知乎