知识图谱 01:知识图谱概述
前言
本内容主要介绍 知识图谱(Knowledge Graph) 的发展、定义、构建和应用。
1.1 知识图谱的发展
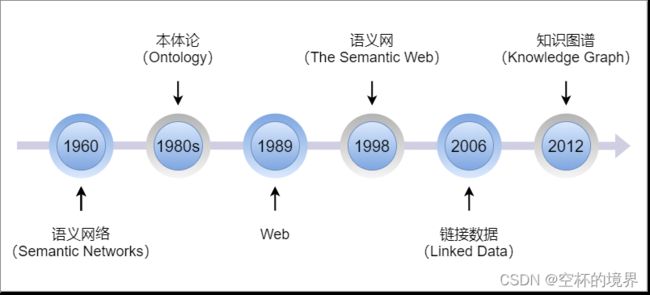
知识图谱(Knowledge Graph)的起源可以追溯到 1960 年,其发展历程如图 1-1 所示:
-
在 1960 年,语义网络(Semantic Networks) 作为知识表示的一种方法被提出,主要用于自然语言理解领域。它是一种用图来表示知识的结构化方式。在一个语义网络中,信息被表达为一组结点,结点通过一组带标记的有向直线彼此相连,用于表示结点间的关系。简而言之,语义网络可以比较容易地让我们理解语义和语义关系。其表达形式简单直白,符合自然。然而,由于缺少标准,其比较难应用于实践。在表现形式上,语义网络和知识图谱相似,但语义网络更侧重于描述概念与概念之间的关系,而知识图谱则更偏重于描述实体之间的关联。
-
1980s 出现了 本体论(Ontology),是由哲学概念引入人工智能领域的,用来刻画知识。
-
1989年,Tim Berners-Lee 在欧洲高能物理研究中心发明了 万维网(Web),人们可以通过链接把自己的文档链入其中。
-
在万维网的基础上,1998 年 Tim 又提出了 语义网(Semantic Web) 的概念,与万维网不同的是,链入网络的不止是网页,还包括客观实际的客体(如人、机构、地点等)。
-
2006 年,Tim 又提出了 链接数据(Linked Data) 的概念,进一步强调了数据之间的链接,而不仅仅是文本的数据化。
-
2012 年 5 月 16 日发布了基于 知识图谱 的搜索引擎。谷歌知识图谱本质上是语义网理念的商业化实现。
1.2 知识图谱的定义
知识图谱 是人工智能的重要分支技术,是结构化的语义知识库,用于以符号形式描述物理世界中的概念及其相互关系。知识图谱通过对错综复杂的文档的数据进行有效的加工、处理、整合,转化为简单、清晰的“实体,关系,实体”的三元组,最后聚合大量知识,从而实现知识的快速响应和推理。
本质上,知识图谱是一种揭示实体之间关系的语义网络。
1.3 知识图谱的架构
知识图谱的架构主要包括自身的 逻辑结构 和 技术架构。
知识图谱在逻辑结构上可分为模式层与数据层两个层次。数据层 主要是由一系列的事实组成,而知识将以事实为单位进行存储。如果用(实体 1,关系,实体 2)、(实体、属性、属性值)这样的三元组来表达事实,可选择图数据库作为存储介质,例如开元的 Neo4J、Twitter 的 FlockDB、JanusGraph 等。模式层 构建在数据层之上,主要是通过本体库来规范数据层的一系列事实表达。本体是结构化知识库的概念模板,通过本体库而形成的知识库不仅层次结构较强,并且冗余程度较小。
知识图谱的技术架构是指构建知识图谱的架构,我们将下一节进行详细说明。
1.4 知识图谱的构建
知识图谱有自顶向下和自底向上两种构建方式。所谓自顶向下构建是借助百科类网站等结构化数据源,从高质量数据中提取本体和模式信息,加入到知识库中。所谓自底向上构建,则是借助一定的技术手段,从公开采集的数据中提取出资源模式,选择其中置信度较高的新模式,经人工审核之后,加入到知识库中。
知识图谱的构建过程分为四个功能模块:数据获取、信息获取、知识融合和知识处理,如图 1-2 所示:
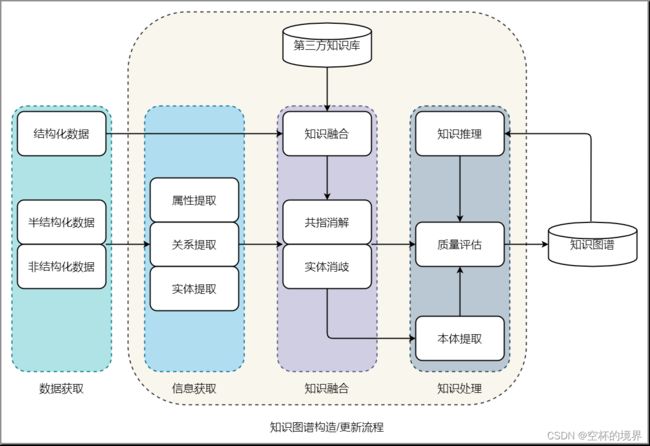
知识图谱的构建需要多种技术的支持。通过信息获取技术,从数据中提取出实体、关系和属性等知识要素。通过知识融合技术,消除实体、关系、属性等指称项与事实对象之间的歧义,形成高质量的知识库。通过知识推理技术,在已有的知识基础上进一步挖掘隐含的知识,从而丰富、扩展知识库。
1.4.1 数据获取
构建一个知识图谱首先要获取数据,这些数据就是知识的来源,它们可以是一些表格、文本、数据库等。根据数据的类型,这些数据可以分为结构化数据、非结构化数据和半结构化数据。结构化数据(Structed Data) 包括表格、数据库等按照一定格式表示的数据,通常可以直接用来构建知识图谱。非结构化数据(Semi-Structed Data) 包含文本、音频、视频和图片等,需要对它们进行信息提取才能进一步建立知识图谱。半结构化数据(UnStructed Data) 是介于结构化和非结构化之间的一种数据,比如 XML、JSON 和百科等数据,也需要进行信息获取才能建立知识图谱。
1.4.2 信息获取
针对结构化数据,知识图谱通常可以直接利用和转化,形成基础数据集,再利用知识图谱补全技术进一步扩展知识图谱。
针对文本数据这种非结构化数据以及半结构化数据,信息获取(Information Acquisition) 的方式主要包括 实体提取、关系提取 和 属性提取 等。
1.4.2.1 实体提取
实体提取(Entity Extraction) 又称为 命名实体识别(Name Entity Recognition,NER),是指从文本数据中自动识别出命名实体。由于实体是知识图谱中的最基本元素,实体提取的质量(准确率和召回率)对后续的知识获取效率和质量影响极大,因此是信息获取中最为基础和关键的部分。
1.4.2.2 关系提取
文本语料经过实体提取后,得到的是一系列离散的命名实体,为了得到语义信息,还需要从相关的语料中提取出实体之间的关联关系,即 关系提取(Relation Extraction);然后通过关联关系将实体(概念)联系起来,形成网状的知识结构。
1.4.2.3 属性提取
属性提取(Attribute Extraction) 是从不同信息源中采集特定实体的属性信息。属性提取技术能够从多种数据来源中汇集这些信息,实现对实体属性的完整勾画。由于实体的属性可以看成是实体与属性值之间的一种名称性关系,因此可以将实体属性的提取问题转换为关系提取问题。
1.4.3 知识融合
当我们构建一个知识图谱时,需要从多个来源获取数据。这些来源不同的数据可能会存在交叉、重叠,同一个概念、实体可能会反复出现,知识融合的目的就是把表示相同概念的实体进行合并,把来源不同的知识融合为一个知识库。
知识融合(Knowledge Fusion) 主要包含 实体链接 和 知识合并。
1.4.3.1 实体链接
实体链接(Entity Linking) 是指对于从文本中提取得到的实体对象,将其链接到知识库中对应的正确实体对象的操作。其基本思想是首先根据给定的实体指称项,从知识库中选出一组候选实体对象,然后通过相似度计算将指称项链接到正确的实体对象。实体链接主要包含实体消歧和共指消解。
(1)实体消歧
实体消歧(Entity Disambiguation) 专门用于解决同名实体产生歧义问题的技术。通过实体消歧,就可以根据当前的语境,准确建立实体链接。实体消歧主要采用聚类法。其实也可以看做基于上下文的分类问题,类似于词性消歧和词义消歧。
(2)共指消解
共指消解(Coreference Resolution) 主要用于解决多个指称对应同一实体对象的问题。通过共指消解,可以将这些指称项关联(合并)到正确的实体对象。
实体链接的流程:
- 从文本中通过实体提取得到实体指称项。
- 进行实体消歧和共指消解,判断知识库中的同名实体与之是否代表不同的含义,以及知识库中是否存在其他命名实体与之表示相同的含义。
- 在确认知识库中对应的正确实体对象之后,将该实体指称项链接到知识库中对应实体。
1.4.3.2 知识合并
在构建知识图谱时,可以从第三方知识库产品或已有结构化数据获取知识输入。常见的 知识合并 需求有两个,一个是合并外部知识库,另一个是合并关系数据库。
将外部知识库融合到知识图谱中,需要处理两个层面的问题:数据层的融合,包括实体的指称、属性、关系以及所属类别等,主要的问题是如何避免实例以及关系的冲突问题,造成不必要的冗余;模式层的融合,将新得到的本体融入已有的本体库中。
将关系数据库融合到知识图谱中,可以采用资源描述框架(RDF)作为数据模型。业界和学术界将这一数据转换过程形象地称为 RDB2RDF,其实质就是将关系数据库的数据转换成 RDF 三元组数据。
1.4.4 知识处理
在前面,我们已经通过信息获取,从原始语料中提取出了实体、关系和属性等知识要素,并且经过知识融合,消除实体指称项与实体对象之间的歧义,得到一系列基本的事实表达。然后事实本身并不等于知识。要想最终获得结构化、网络化的知识体系,还需要经历知识处理的过程。知识处理主要包括三个方面的内容:本体构建、知识推理和质量评估。
1.4.4.1 本体构建(Ontology Extraction)
本体(Ontology)可以采用人工编辑的方式手动构建,也可以以数据驱动的自动化方式构建本体。因为人工方式工作量巨大,且很那找到符合要求的专家,因此当前主流的全局本体库产品,都是从一些面向特定领域的现有本体库出发,采用自动化构建技术逐步扩展得到的。
1.4.4.2 知识推理
在我们完成了本体构建这一步之后,一个知识图谱的雏形便已经搭建好了。但可能在这个时候,知识图谱之间大多数关系都是残缺的,缺失值非常严重,那么这个时候,我们就可以使用 知识推理(Knowledge Inference) 技术,去完成进一步的知识发现。
推理是模拟思维的基本形式之一,是从一个或多个现有判断(前提)中推断出新判断(结论)的过程。基于知识图谱的知识推理旨在识别错误并从现有数据中推断新结论。通过知识推理可以导出实体间的新关系,并反馈以丰富知识图谱,从而支持高级应用。
1.4.4.3 质量评估
质量评估(Quality Evaluation) 也是知识库构建技术的重要组成部分,其意义在于:可以对知识的可信度进行量化,通过舍弃置信度较低的知识来保障知识库的质量。
1.4.5 知识更新
从逻辑上看,知识图谱的更新包括概念层的更新和数据层的更新。概念层的更新是指新增数据后获得了新的概念,需要自动将新的概念添加到知识库的概念层中。数据层的更新主要是新增或更新实体、关系、属性值,对数据层进行更新需要考虑数据的一致性等。
知识图谱的更新有两种方式:
- 全面更新:以更新后的全部数据为输入,从零开始构建知识图谱。这种方法比较简单,但资源消耗大,而且需要耗费大量人力资源进行系统维护。
- 增量更新:以当前新增数据为输入,向现有知识图谱中添加新增知识。这种方式资源消耗小,但目前仍需要大量人工干预(定义规则等),因此实施起来十分困难。
1.4.6 其他
除了上面已经提及的技术外,在构建知识图谱的过程中还涉及到知识表示、知识存储等。
知识表示指用一定的结构和符号语言来描述知识,并且能够用计算机进行推理、计算等操作的技术。知识表示的主要方法有:谓词逻辑表示法、框架表示法、基于语义网络的表示法和基于语义网的表示法。
知识图谱主要有两种存储方式:一种是基于 RDF 的存储;另一种是基于图数据库的存储。RDF 的一个重要设计原则是数据的易发布以及共享,图数据库则把重点放在了高效的图查询和搜索上。其次,RDF 以三元组的方式来存储数据而且不包含属性信息,但图数据库一般以属性图为基本的表示形式,所以实体和关系可以包含属性,这就意味着更容易表达现实的业务场景。
1.5 知识图谱的应用
通过知识图谱,不仅可以将互联网的信息表达成更接近人类认知世界的形式,而且提供了一种更好地组织、管理和利用海量信息的方式。目前知识图谱用于智能搜索、智能问答、推荐系统、社交网络等领域。
1.5.1 智能搜索
互联网的终极形态是万物互联,而搜索的终极目标是对万物直接进行搜索。传统的搜索是靠网页之间的超链接实现网页的搜索,而语义搜索是直接对事物进行搜索,比如人、物、机构、地点等,这些事物可以来自文本、图片、视频、音频、物联网设备等。知识图谱和语义技术提供了关于这些事物的分类、属性和关系的描述,这样搜索引擎就可以直接对事物进行搜索。
对于搜索引擎,知识图谱解决了一个难题,即精确的对象级搜索问题。传统搜索引擎只能返回很多相关页面,用户需要从海量文本中自行寻找答案,即所谓字符串(Strings)级别的搜索。
1.5.2 智能问答
知识图谱可以应用于智能问答,比如天猫精灵、小米小爱和百度度秘等背后都有知识图谱数据和技术的支持。智能问答本质就是一种对话式的搜索,相比普通的搜索引擎,智能问答更加需要事物级的精确搜索和直接回答。
1.5.3 推荐系统
推荐系统也是知识图谱的典型应用场景。例如,在电商的推荐计算场景中,可以分别构建 User KG 和 Item KG。知识图谱的引入丰富了 User 和 Item 的语义属性和语义关系等信息,将大大增强 User 和 Item 的特征表示,从而有利于挖掘更深层次的用户兴趣。关系的多样性也有利于实现更加个性化的推荐,丰富的语义描述还可以增强推荐结果的可解释性,让推荐结果更加可靠和可信。
1.5.4 社交网络
Facebook 于 2013 年推出了 Graph Search 产品,其核心技术就是通过知识图谱将人、地点、事情等联系在一起,并以直观的方式支持精确的自然语言查询。
参考
[1] 1. 通俗易懂解释知识图谱(Knowledge Graph)
[2] 知识图谱入门——认识知识图谱
[3] 什么是知识图谱?
[4] 知识图谱的技术与应用(18版)
[5] 为什么需要知识图谱?什么是知识图谱?——KG的前世今生