基于深度强化学习的智能船舶航迹跟踪控制
基于深度强化学习的智能船舶航迹跟踪控制
人工智能技术与咨询 昨天
本文来自《中国舰船研究》 ,作者祝亢等
关注微信公众号:人工智能技术与咨询。了解更多咨询!
0. 引 言
目前,国内外对运载工具的研究正朝着智能化、无人化方向发展,智能船舶技术受到全球造船界与航运界的广泛关注。其以实现船舶航行环境的智能化、自主化发展为目标,深度融合传统船舶设计与制造技术以及现代信息通信与人工智能技术,包含智能航行、智能船用设备、智能船舶测试等多方面的研究[1]。其中,智能航行技术一直是保障船舶顺利完成货物运输、通信救助等任务的重要基础。要使船舶在面对多种复杂水域干扰的情况下也能遵守正常的通航秩序,安全地执行任务且保证完成效果,采取有效的控制手段精确进行航迹跟踪就显得尤为重要。
针对航迹跟踪的研究任务可以分为制导和控制2个方面。在制导方面,常由视线(line-of-sight,LOS)算法将路径跟踪问题转换为方便处理的动态误差控制问题;在控制方面,基于船舶的复杂非线性系统,常考虑使用PID等无模型控制方法,或采用模型线性化的方法来解决非线性模型在计算速率方面存在的问题。但对于复杂的环境,传统PID控制器不仅参数复杂,还不具备自适应学习能力。而最优控制、反馈线性化一类的控制算法通常需要建立精确的模型才能获得较高的控制精度。滑模控制虽然对模型精度要求不高,但其抖振问题难以消除[2]。即使存在一些自适应参数调节方法,如通过估计系统输出实现PID参数自整定的自适应PID控制方法,也会由于模型的不确定性和外界扰动,存在系统输出与真实输出的偏差[3],又或者存在参数寻优时间过长的问题而影响控制的实时性。对于与模糊逻辑相结合的响应速度快、实时性好的PID自适应控制器[4],其控制精度依赖于复杂的模糊规则库,致使整体计算复杂。
考虑到船舶的复杂非线性系统模型,和保障航迹跟踪控制的实时性时产生的大量参数整定和复杂计算等问题,本文将采用深度强化学习算法来研究智能船舶的轨迹跟踪问题。深度强化学习(deep reinforcement learning,DRL)是深度学习与强化学习的结合,其通过强化学习与环境探索得到优化的目标,而深度学习则给出运行的机制用于表征问题和解决问题。深度强化学习算法不依赖动力学模型和环境模型,不需要进行大量的算法计算,还具备自学习能力。Magalhães等[5]基于强化学习算法,使用Q-learning设计了一种监督开关器并应用到了无人水面艇,它能智能地切换控制器从而使无人艇的行驶状态符合多种环境与机动要求。2015年,Mnih等[6]为解决复杂强化学习的稳定性问题,将强化学习与深度神经网络相结合,提出了深度Q学习(deep Q network,DQN)算法,该算法的提出代表了深度强化学习时代的到来。之后,在欠驱动无人驾驶船舶的航行避碰中也进行了相关应用[7]。
面对存在的大量参数整定、复杂算法计算等问题,为实现船舶航迹跟踪的精准控制,本文拟设计一种基于深度确定性策略梯度算法(deep deterministic policy gradient,DDPG)的深度强化学习航迹跟踪控制器,在LOS算法制导的基础上,对船舶航向进行控制以达到航迹跟踪效果。然后,根据实际船舶的操纵特性以及控制要求,将船舶路径跟踪问题建模成马尔可夫决策过程,设计相应的状态空间、动作空间与奖励函数,并采用离线学习方法对控制器进行学习训练。最后,通过仿真实验验证深度强化学习航迹控制器算法的有效性,并与BP-PID控制器算法的控制效果进行对比分析。
1. 智能船舶航迹跟踪控制系统总体设计
1.1 LOS算法制导
航迹跟踪控制系统包括制导和控制2个部分,其中制导部分一般是根据航迹信息和船舶当前状态确定所需的设定航向角值来进行工作。本文使用的LOS算法已被广泛运用于路径控制。LOS算法可以在模型参数不确定的情况下,以及在复杂的操纵环境中与控制器结合,从而实现对模型的跟踪控制。视线法的导航原理是基于可变的半径与路径点附近生成的最小圆来产生期望航向,即LOS角。经过适当的控制,使当前船舶的航向与LOS角一致,即能达到航迹跟踪的效果[8]。
LOS算法示意图如图1所示。假设当前跟踪路径点为Pk+1(xk+1,yk+1)Pk+1(xk+1,yk+1),上一路径点为Pk(xk,yk)Pk(xk,yk),以船舶所在位置Ps(xs,ys)Ps(xs,ys)为圆心,选择半径RLosRLos与路径PkPk+1PkPk+1相交,选取与Pk+1Pk+1相近的点PLos(xLos,yLos)PLos(xLos,yLos)作为LOS点,当前船舶坐标到LOS点的方向矢量与x0x0的夹角ψLosψLos则为需要跟踪的LOS角。图中:dd为当前船舶至跟踪路径的最短距离;ψψ为当前航向角。
其中,半径RLosRLos的计算公式如式(1)和式(2)所示,为避免RminRmin的计算出现零值,在最终的计算中加入了2倍的船长LppLpp来进行处理[9]。
| ⎧⎩⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪a(t)=(x(t)−xk)2+(y(t)−yk)2−−−−−−−−−−−−−−−−−−−−−√b(t)=(xk+1−x(t))2+(y(t)−yk+1)2−−−−−−−−−−−−−−−−−−−−−−−−√c(t)=(xk+1−xk)2+(yk+1−yk)2−−−−−−−−−−−−−−−−−−−−−−√Rmin(t)=a(t)2−(c(t)2−b(t)2+a(t)22c(t))2−−−−−−−−−−−−−−−−−−−−−−−−−−⎷{a(t)=(x(t)−xk)2+(y(t)−yk)2b(t)=(xk+1−x(t))2+(y(t)−yk+1)2c(t)=(xk+1−xk)2+(yk+1−yk)2Rmin(t)=a(t)2−(c(t)2−b(t)2+a(t)22c(t))2 |
(1) |
| RLos=Rmin(t)+2LppRLos=Rmin(t)+2Lpp |
(2) |
式中,所计算的RminRmin即为当前时刻t的航迹误差ε,也即图1中的dd。
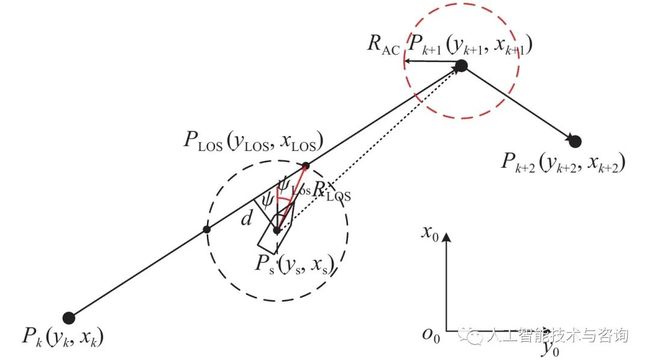
图 1 LOS导航原理图
Figure 1. Schematic diagram of LOS algorithm
船舶在沿着路径进行跟踪时,若进入下一个航向点的一定范围内,即以Pk+2(xk+2,yk+2)Pk+2(xk+2,yk+2)为圆心、RACRAC为半径的接受圆内,则更新当前航向点为下一航向点,半径RACRAC一般选取为2倍船长。
1.2 基于强化学习的控制过程设计
强化学习(reinforcement learning,RL)与深度学习同属机器学习范畴,是机器学习的一个重要分支,主要用来解决连续决策的问题,是马尔可夫决策过程(Markov decision processes,MDP)问题[10]的一类重要解决方法。
此类问题均可模型化为MDP问题,简单表示为四元组
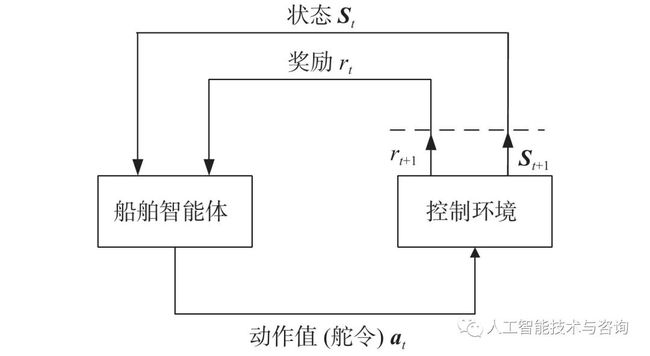
图 2 船舶控制的MDP模型
Figure 2. MDP model of ship control
如图2所示,船舶智能体直接与当前控制环境进行交互而且不需要提前获取任何信息。在训练过程中,船舶采取动作值atat与环境进行交互更新自己的状态st→st+1st→st+1,并获得相应的奖励rt+1rt+1,之后,继续采取下一动作与环境交互。在此过程中,会产生大量的数据,利用这些数据学习优化自身选择动作的策略policyππ。简单而言,这是一个循环迭代的过程。在强化学习中,训练的目标是找到一个最佳的控制策略 policyπ∗π∗,以使累积回报值RtRt达到最大[11]。在下面的公式中,γγ为折扣系数,用来衡量未来回报在当前时期的价值比例,设定γ∈[0,1]γ∈[0,1]。
| Rt=rt+γrt+1+γ2rt+2+⋯=∑k=1∞γkrt+k+1Rt=rt+γrt+1+γ2rt+2+⋯=∑k=1∞γkrt+k+1 |
(3) |
Policy ππ可以使用2种值函数进行评估:状态值函数Vπ(st)Vπ(st)和动作值函数Qπ(st,at)Qπ(st,at)。其中Vπ(st)Vπ(st)为在遵循当前策略的状态下对累积回报值的期望,EE为期望值;类似地,Qπ(st,at)Qπ(st,at)表示基于特定状态和动作情况(st,at)(st,at)下对累积回报值的期望。
| Vπ(st)=Eπ[Rt|st]=Eπ[∑k=1∞γkrt+k+1|st]Vπ(st)=Eπ[Rt|st]=Eπ[∑k=1∞γkrt+k+1|st] |
(4) |
| Qπ(st,at)=Eπ[Rt|st,at]=Eπ[∑k=1∞γkrt+k+1|st,at]Qπ(st,at)=Eπ[Rt|st,at]=Eπ[∑k=1∞γkrt+k+1|st,at] |
(5) |
根据值函数和上述最佳控制策略policy π∗π∗的定义,最佳policy π∗π∗总是满足以下条件:
| π∗=argmaxVπ(st)=argmaxQπ(st,at)π∗=argmaxVπ(st)=argmaxQπ(st,at) |
(6) |
1.3 航迹跟踪问题马尔可夫建模
从以上描述可以看出,在基于强化学习的控制设计中,马尔可夫建模过程的组件设计是最为关键的过程,状态空间、动作空间和奖励的正确性对算法性能和收敛速度的影响很大。所以针对智能船舶的轨迹跟踪问题,对其进行马尔可夫建模设计。
1) 状态空间设计。
根据制导采用的LOS算法,要求当前航向角根据LOS角进行调节以达到跟踪效果。所以在选取状态时,需考虑LOS算法中的输出参数,包括目标航向ψLOSψLOS与实际航向ψψ的差值ee、航迹误差ε,以及与航迹点距离误差εdεd。
对于船舶模型,每个时刻都可以获得当前船舶的纵荡速度uu、横荡速度vv、艏转向速度rr和舵角δδ。为使强化学习能实现高精度跟踪效果,快速适应多种环境的变换,除了选取当前时刻的状态值外,还加入了上一时刻的状态值进行比较,以及当前航向误差与上一时刻航向误差的差值e(k−1)e(k−1),使当前状态能够更好地表示船舶是否在往误差变小的方向运行。最终,当前时刻t的状态空间可设计为
| st=[et,εt,εdt,ut,vt,rt,δt,e(k−1)t,et−1,εt−1,εdt−1,ut−1,vt−1,rt−1,δt−1]st=[et,εt,εtd,ut,vt,rt,δt,e(k−1)t,et−1,εt−1,εt−1d,ut−1,vt−1,rt−1,δt−1] |
(7) |
2) 动作空间设计。
针对航迹跟踪任务特点,以及LOS制导算法的原理,本文将重点研究对船舶航向,即舵角的控制,不考虑对船速与桨速的控制。动作空间只有舵令一个动作值,即δδ,其值的选取需要根据实际船舶的控制要求进行约束,设定为在(−35∘,35∘)(−35∘,35∘)以内,最大舵速为15.8 (°)/s。
3) 奖励函数设计。
本文期望航向角越靠近LOS角奖励值越高,与目标航迹的误差越小奖励值越高。因此,设计的奖励函数为普遍形式,即分段函数:
| rt={0,−|e|−0.1|e(k−1)|−0.01|ε|,if|e|⩽0.1radif|e|>0.1radrt={0,if|e|⩽0.1rad−|e|−0.1|e(k−1)|−0.01|ε|,if|e|>0.1rad |
(8) |
式中,e(k−1)e(k−1)为当前航向误差与上一时刻航向误差的差值。当差值大于0.1rad0.1rad时选择负值奖励,也可称之为惩罚值,是希望训练网络能尽快改变当前不佳的状态。将负值的选取与另一分段的00奖励值做明显对比,使其训练学习后可以更加快速地选择奖励值高的动作,从而达到最优效果。
1.4 控制系统总体方案
基于强化学习的智能船舶航迹控制系统总体框架如图3所示。LOS算法根据船舶当前位置计算得到需要的航向以及航迹误差,在与船舶的状态信息整合成上述所示状态向量stst后输入进航迹控制器中,然后根据强化学习算法输出当前最优动作值atat给船舶执行,同时通过奖励函数rtrt计算获得相应的奖励来进行自身参数迭代,以使航迹控制器具备自学习能力。

图 3 基于强化学习的智能船舶轨迹跟踪控制框图
Figure 3. Block diagram of intelligent ship tracking control based on RL
在将控制器投入实时控制之前,首先需要对控制器进行离线训练。设定规定次数的训练后,将获得的使累计回报值达到最大的网络参数进行存储整合,由此得到强化学习控制器,并应用于航迹跟踪的实时控制系统。
要解决强化学习问题,目前有许多的算法、机制和网络结构可供选择,但这些方法都缺少可扩展的能力,并且仅限于处理低维问题。为此,Mnih等[6]提出了一种可在强化学习问题中使用大规模神经网络的训练方法——DQN算法,该算法成功结合了深度学习与强化学习,使强化学习也可以扩展处理一些高维状态、动作空间下的决策问题[12]。DQN算法可解决因强化学习过程与神经网络逼近器对值函数逼近的训练相互干扰,而导致学习结果不稳定甚至是产生分歧的问题[13],是深度强化学习领域的开创者。
DQN算法显著提高了复杂强化学习问题的稳定性和性能,但因其使用的是离散的动作空间,故需要对输出的动作进行离散化,且只能从有限的动作值中选择最佳动作。对于船舶的轨迹跟踪问题,如果候选动作数量太少,就很难对智能体进行精确控制。为使算法满足船舶的操纵特性与要求,本文选择了一种适用于连续动作空间的深度强化学习算法,即基于DDPG的算法[14]来对智能船舶航迹跟踪控制器进行设计,该算法不仅可以在连续动作空间上进行操作,还可以高效精准地处理大量数据。
2. 基于DDPG算法的控制器设计
2.1 DDPG算法原理
DDPG是Lillicrap等[14]将DQN算法应用于连续动作中而提出的一种基于确定性策略梯度的Actor-Critic框架无模型算法。DDPG的基本框架如图4所示。

图 4 DDPG基本框架
Figure 4. Block diagram of DDPG
网络整体采用了Actor-Critic形式,同时具备基于值函数的神经网络和基于策略梯度的神经网络:Actor网络的θπθπ表示确定性策略函数a=π(s|θπ)a=π(s|θπ),Critic网络的θQθQ表示值函数Q(s,a|θQ)Q(s,a|θQ)。并且DDPG还借鉴了DQN技术,其通过采取经验池回放机制(experience replay)以及单独的目标网络来消除大规模神经网络带来的不稳定性。
所谓经验池回放机制,即在每个时间点都存储当前状态、动作等信息作为智能体的经验et=(st,at,rt,st+1)et=(st,at,rt,st+1),以此形成回放记忆序列D={e1,⋯,eN}D={e1,⋯,eN}。在训练网络时,从中随机提取mini batch数量的经验数据作为训练样本,但重复使用历史数据的操作会增加数据的使用率,也打乱了原始数据的顺序,会降低数据之间的关联性。而目标网络则建立了2个结构一样的神经网络——用于更新神经网络参数的主网络和用于产生优化目标值的目标网络,初始时,将主网络参数赋予给目标网络,然后主网络参数不断更新,目标网络不变,经过一段时间后,再将主网络的参数赋予给目标网络。此循环操作可使优化目标值在一段时间内稳定不变,从而使得算法性能更加稳定。
在训练过程中,主网络中的Actor网络根据从经验池中随机选取的样本状态ss,经过当前策略函数a=π(s|θπ)a=π(s|θπ)选择出最优的动作值aa交予船舶智能体,让其与环境交互后得到下一时刻的状态值s′s′。而此时的Critic网络则接受当前的状态ss和动作值aa,使用值函数Q(s,a|θQ)Q(s,a|θQ)评价当前状态的期望累计奖赏,并用于更新Actor网络的参数。在目标网络中,整体接收下一时刻的状态s′s′,经目标Actor网络选出动作后交予目标Critic获得目标期望值Q′(a′)Q′(a′),然后,再通过计算损失函数对主网络的Critic网络参数进行更新。对于主网络的Actor网络参数更新,Silver等[15]证实,确定性策略的目标函数J(θπ)J(θπ)采用ππ策略的梯度与Q函数采用ππ策略的期望梯度是等价的:
| ∂J(θπ)∂θπ=Es[∂Q(s,a|θQ)∂θπ]∂J(θπ)∂θπ=Es[∂Q(s,a|θQ)∂θπ] |
(9) |
根据确定性策略a=π(s|θπ)a=π(s|θπ),得到Actor网络的梯度为:
| ∂J(θπ)∂θπ=Es[∂Q(s,a|θQ)∂a∂π(s|θπ)∂θπ]∂J(θπ)∂θπ=Es[∂Q(s,a|θQ)∂a∂π(s|θπ)∂θπ] |
(10) |
| ∇θπJ≈1N∑i(∇aQ(s,a|θπ)|s=si,a=π(si)⋅∇θππ(s|θπ)|s=si)∇θπJ≈1N∑i(∇aQ(s,a|θπ)|s=si,a=π(si)⋅∇θππ(s|θπ)|s=si) |
(11) |
另一方面,对于Critic网络中的价值梯度:
| ∂L(θQ)∂θQ=Es,a,r,s′∼D[(TargetQ−Q(s,a|θQ))∂Q(s,a|θQ)∂θQ]∂L(θQ)∂θQ=Es,a,r,s′∼D[(TargetQ−Q(s,a|θQ))∂Q(s,a|θQ)∂θQ] |
(12) |
| TargetQ=r+γQ′(s′,π(s′|θπ′)|θQ′)TargetQ=r+γQ′(s′,π(s′|θπ′)|θQ′) |
(13) |
式中,θπ′θπ′和θQ′θQ′分别为目标策略网络和目标值函数网络的网络参数。其中,目标网络的更新方法与DQN算法中的不同,在DDPG算法中,Actor-Critic网络各自的目标网络参数是通过缓慢的变换方式更新,也叫软更新。以此方式进一步增加学习过程的稳定性:
| θQ′=τθQ+(1−τ)θQ′θQ′=τθQ+(1−τ)θQ′ |
(14) |
| θπ′=τθπ+(1−τ)θπ′θπ′=τθπ+(1−τ)θπ′ |
(15) |
式中,ττ为学习率。
定义最小化损失函数来更新Critic网络参数,其中,yiyi为当前时刻状态动作估计值函数与目标网络得到的目标期望值间的误差:
| L=1N∑i(yi−Q(si,ai|θQ))2L=1N∑i(yi−Q(si,ai|θQ))2 |
(16) |
2.2 算法实现步骤
初始化Actor-Critic网络的参数,将当前网络的参数赋予对应的目标网络;设置经验池容量为30 000个,软更新学习率为0.01,累计折扣系数设定为0.9,初始化经验池。训练的每回合步骤如下:
1) 初始化船舶环境;
2) 重复以下步骤直至到达设置的最大步长;
3) 在主网络中,Actor网络获取此刻船舶的状态信息stst,并根据当前的策略选取动作舵令δtδt给船舶执行,即δt=π(st|θπ)δt=π(st|θπ);
4) 船舶执行当前舵令后输出奖励rtrt和下一个状态st+1st+1,Actor网络再次获取该状态信息并选取下一舵令δt+1δt+1;
5) 将此过程中产生的数据(st,δt,rt,st+1)(st,δt,rt,st+1)存储在经验池中,以作为网络训练学习的数据集。当经验池存储满后,再从第1个位置循环存储;
6) 从经验池中随机采样N个样本(st,δt,rt,st+1)(st,δt,rt,st+1),作为当前Actor网络和Critic网络的训练数据;
7) 通过损失函数更新Critic网络,根据Actor网络的策略梯度更新当前Actor网络,然后再对目标网络进行相应的软更新。
3. 系统仿真与算法对比分析
3.1 仿真环境构建
为验证上述方法的有效性,基于Python环境进行了船舶航迹跟踪仿真实现。控制研究对象模型选用文献[16-17]中的单桨单舵7 m KVLCC2船模,建模采用三自由度模型(即纵荡、横荡和艏摇),具体建模过程参考文献[16]。表1列出了船舶的一些主要参数。
表 1 KVLCC2船舶参数
Table 1. Parameters of a KVLCC2 tanker
| 参数 | 数值 | 参数 | 数值 | |
| 船长Lpp/m | 7 | 方形系数CbCb | 0.809 8 | |
| 船宽Bwl/m | 1.168 8 | 浮心坐标/m | 0.244 0 | |
| 型深D/m | 0.656 3 | 螺旋桨直径Dp/m | 0.216 0 | |
| 排水体积/m3 | 3.272 4 | 舵面积/m2 | 0.053 9 |
| 显示表格
在所选用的DDPG控制器中,Crtic网络和Actor网络的实现参数设置分别如表2和表3所示。
表 2 Critic网络参数
Table 2. Critic network parameters
| 参数 | 赋值 |
| 输入层 | 状态向量S(t)S(t) |
| 第1个隐层 | 300 |
| 第1层激活函数 | Relu |
| 第2个隐层 | 200 |
| 第2层激活函数 | Relu |
| 输出层 | 动作δ(t)δ(t) |
| 输出层激活函数 | Tanh |
| 参数初始化 | Xavier初始化 |
| 学习率 | 0.000 1 |
| 优化器 | Adam |
表 3 Actor网络参数
Table 3. Actor network parameters
| 参数 | 赋值 |
| 输入层 | 状态向量S(t)S(t),动作δ(t)δ(t) |
| 第1个隐层 | 300 |
| 第1层激活函数 | Relu |
| 第2个隐层 | 200 |
| 第2层激活函数 | Relu |
| 输出层 | Q(S(i),δ(i))Q(S(i),δ(i)) |
| 输出层激活函数 | Linear |
| 参数初始化 | Xavier初始化 |
| 学习率 | 0.001 |
| 优化器 | Adam |
3.2 控制器离线学习
基于DDPG算法进行的离线训练学习设置如下:初始化网络参数以及经验缓存池,设计最大的训练回合为2 000,每回合最大步长为500,采样时间为1 s。在规划训练期间所需跟踪的航迹时,为使控制器适应多种环境,以及考虑到LOS制导算法中对于航向控制的要求,依据文献[18]中的设计思想,根据拐角的变换,设计了多条三航迹点航线,每回合训练时随机选取一条进行航迹跟踪。
训练时,将数据存入经验池中,然后再从中随机采样一组数据进行训练,状态值及动作值均进行归一化处理,当达到最大步长或最终航迹点输出完成时,便停止这一回合,并计算当前回合的总回报奖励。当训练进行到200,300和500回合时,其航向误差如图5所示。由图中可以看出,在训练时随着回合的增加,航向误差显著减小,控制算法不断收敛;当训练达到最大回合结束后,总奖励值是不断增加的。为使图像显示得更加清晰,截取了200~500回合的总回报奖励如图6所示。从中可以看出,在约270回合时算法基本收敛,展现了快速学习的过程。

图 5 航向误差曲线
Figure 5. Course error curves
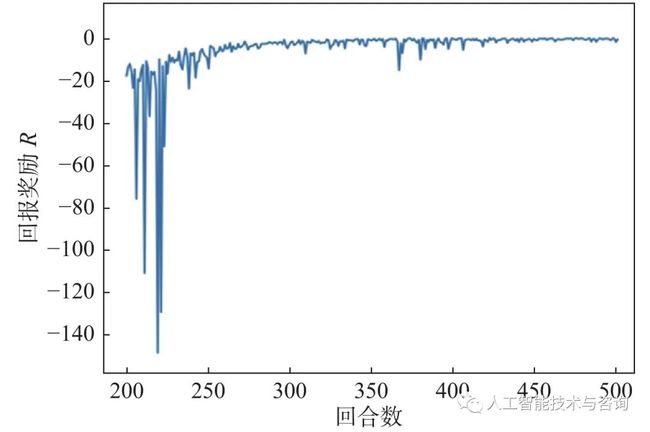
图 6 总回报奖励曲线
Figure 6. Total reward curve
3.3 仿真实验设计及对比分析
上述训练完成后,DDPG控制器保存回报奖励函数最大的网络参数,并将其应用于航迹跟踪仿真。为了验证DDPG控制器的可行性,本文选用BP-PID控制器进行对比分析。
用于对比的BP-PID控制器选择使用输入层节点数为4、隐含层节点数为5、输出层节点数为3的BP神经网络对PID的3种参数进行选择,其中学习率为0.546,动量因子为0.79,并参考文献[19],利用附加惯性项对神经网络进行优化。在相同的环境下,将DDPG控制器与BP-PID控制器进行仿真对比分析。仿真时,船舶的初始状态为从原点(0,0)出发,初始航向为45°,初始航速也即纵荡速度uu=1.179 m/s,螺旋桨初始速度rr=10.4 r/s。
仿真实验1:分别设计直线轨迹和锯齿状轨迹,用以观察2种控制器对直线的跟踪效果和面对剧烈转角变化时的跟踪效果(图7),轨迹点坐标分别为(0,50),(400,50)和(0,0),(100,250),(200,0),(300,250),(400,0),(500,250),(600,0),单位均为m。

图 7 航迹跟踪效果(实验1)
Figure 7. Tracking control result (experiment 1)
通过对2种类型轨迹跟踪的对比可以看出,对于直线轨迹,DDPG控制器能够更加快速地进行稳定跟踪,在锯齿状轨迹转角跟踪时其效果也明显优于BP-PID控制器。对仿真过程中航向角的均方根误差(图7(b))进行计算,显示BP-PID控制器的数值达61.017 8,而DDPG控制器的仅为10.018,后者具有更加优秀的控制性能。
仿真实验2:为模拟传统船舶的航行轨迹,设计轨迹点为(0,0),(100,50),(150,250),(400,250),(450,50),(550,0)的航迹进行跟踪。跟踪效果曲线和航向均方根误差(RMSE)的对比分别如图8和表4所示。

图 8 航迹跟踪结果(实验2)
Figure 8. Tracking control result (experiment 2)
表 4 控制性能指标
Table 4. Control performance
| 控制器 | RMSE |
| BP-PID控制器 | 13.585 0 |
| DDPG控制器 | 6.911 96 |
在此次仿真过程中,进一步对比了2种控制器对于LOS角跟踪的效果以及舵角的变化频率,结果分别如图9和图10所示。PID经过BP神经网络参数整定后整体巡航时间约为1 000 s,而DDPG控制器的巡航时间则在此基础上缩短了4%;在转角处的航向跟踪中,DDPG控制器在20 s内达到期望值,而BP-PID的调节时间则约为60 s,且控制效果并不稳定,舵角振动频率高。由此可见,深度强化学习控制器可以很快地根据航迹变化做出调整,减少了不必要的控制环节,调节时间短,控制效果稳定,舵角变化频率小,具有良好的控制性能。

图 9 BP-PID控制器控制效果
Figure 9. Control result of BP-PID
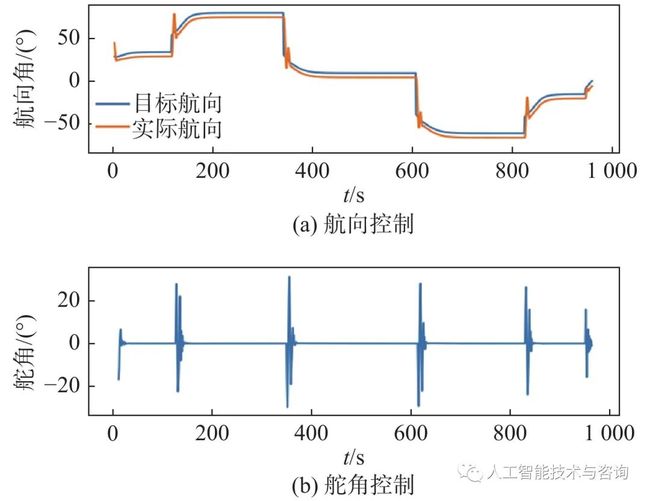
图 10 DDPG控制器控制效果
Figure 10. Control result of DDPG
4. 结 语
本文针对船舶的航迹跟踪问题,提出了一种基于深度强化学习的航迹跟踪控制器设计思路。首先根据LOS算法制导,建立了航迹跟踪控制的马尔可夫模型,给出了基于DDPG控制器算法的程序实现;然后在Python环境中完成了船舶航迹跟踪控制系统仿真实验,并与BP-PID控制器进行了性能对比分析。
将航迹跟踪问题进行马尔可夫建模设计后,将控制器投入离线学习。通过对此过程的分析发现,DDPG控制器在训练中能快速收敛达到控制要求,证明了设计的状态、动作空间以及奖励函数的可行性。并且航迹跟踪仿真对比结果也显示,DDPG控制器能较快地应对航迹变化,控制效果稳定且舵角变化少,对于不同的轨迹要求适应性均相对良好。整体而言,基于深度强化学习的控制方法可以应用到船舶的航迹跟踪控制之中,在具有自适应稳定控制能力的情况下,不仅免去了复杂的控制计算,也保证了实时性,对船舶的智能控制具有一定的参考价值。

关注微信公众号:人工智能技术与咨询。了解更多咨询!