光流融合到RGB流的巨作:《MARS: Motion-Augmented RGB Stream for Action Recognition》
代码:MARS
论文地址:MARS Paper
摘要
大多数的双流方法:一个流输入RGB 另一个流输入光流。虽然光流能够提高性能,但是光流计算耗时。所以双流的这种方式是很难去进行低延时的应用。在这篇paper中,作者引入了两种方式来专门操作RGB帧模仿运动流,训练一个标准的3DCNN。首先,与Flow流相比,通过最小化基于特征的损失,我们表明网络以高保真度重现运动流。其次,为了有效地利用外观和运动信息,我们使用基于特征的损失和用于动作识别的标准交叉熵损失的线性组合进行训练。我们将使用这种组合损失训练的流表示为MotionAugmented RGB流(MARS)。作为单个流,MARS比单独的RGB或Flow执行得更好与RGB和Flow流的72.0%和65.6%相比,Kinetics的准确性分别为72.7%和65.6%。
Introduction
基于双流RGB和Flow的结合3D-CNN产生最好的结果是有一定的缺点。首先,双流方法需要从RGB帧中提取显式和准确的光流,这是计算成本很高的,如图1中MiniKinetics数据集[44]上的精度与时间图所示。从图中我们可以观察到Flow和RGB+Flow明显比RGB慢。计算流的有效方法确实存在,但它们不是那么有效。其次,在计算网络的前向通过之前,需要估计光流。因此,双流方法不仅需要大量的计算资源,而且还导致在线场景中识别动作的高延迟。因此,即使在架构优化后,它们也不能应用于实际应用[44]。
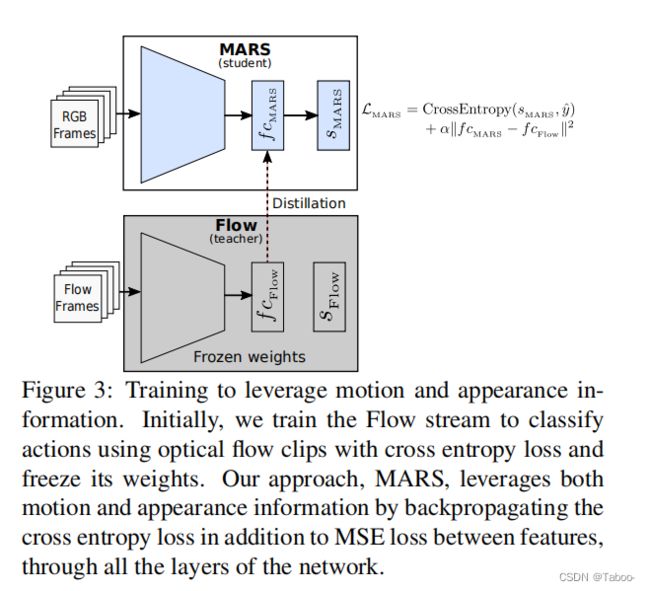
在本文中,我们提出了两种新的学习策略,基于蒸馏[14]和特权信息下学习[39]的概念,以避免测试时的流计算,同时保持双流方法的性能。首先,我们训练一个标准的3D CNN,它以RGB作为输入,并从图像中产生特征流。更准确地说,我们将网络最后一个完全连接层之前的层的特征与来自运动流的同一层的特征之间的差异最小化(参见图2)。换句话说,我们的流在架构和输入方面类似于RGB流,但使用不同的损失函数进行训练。我们表明,通过使用这种方法,可以从RGB帧中获得光流特征,而无需在推理过程中进行显式的光流计算。为了便于标记,我们将此网络表示为运动模拟RGB流(MERS)。可以有效地将从光流获得的知识转移到基于3D卷积的RGB输入流中。
通过将标准RGB流与仅基于RGB输入的新流(MERS)相结合,我们获得了与双流方法(RGB+Flow)相当的精度,但计算成本显著降低。我们用MARS表示MotionAugmented RGB Stream网络。实验强调,使用我们的新方法训练的网络,比单独的RGB和Flow流表现更好,与双流组合(RGB+Flow)相当。这表明MARS有效地利用了外观和运动信息。具体而言,MARS在 Kinetics上获得了72.7%的精度,而RGB和Flow分别为72.0%和65.6%。类似地,在HMDB51 (split-1)上,MARS获得了80.1%的精度,而RGB和Flow分别为73.5%和75.9%.
3 Learning to Replace Flow
动作识别的最新技术同时利用了外观(RGB)和运动(Flow)流[2]。这些流具有3D卷积而不是2D卷积的标准图像架构,并以固定长度的片段作为输入。给定一个连续帧的动作y的视频剪辑,分别训练RGB和Flow流来对动作进行分类。让sRGB (resp。sFlow)表示由RGB (resp. sFlow)计算的分数。Flow)网络在softmax之前,yRGB (resp。yFlow)预测的类别,即得分最高的类别。测试时的预测通常是通过平均sRGB和sFlow得到的。
我们现在解决了在测试时避免流计算的挑战,同时实现与双流网络类似的性能。为此,我们提出了一种基于特权信息下学习[39]概念的解决方案。我们认为在流剪辑上运行的光流是一个教师网络,它拥有动作识别所需的重要信息。我们的目标是训练第二个网络(学生)使用RGB帧作为输入对动作进行分类,以及来自老师的特权信息,即只在训练时提供的光流。在下面,我们假设Flow流已经训练为动作识别,我们冻结它的权重。我们现在详细介绍我们的两个学习策略:(i)使用RGB帧模仿光流特征(第3.1节),(ii)利用外观和运动信息(第3.2节)。

3.1. MERS
我们的第一个训练策略被称为运动仿真RGB即光流。我们通过在特征级上施加损失函数来实现这一点。CNN的初始层表示低层次的局部特征,后一层表示高层次的全局特征[46],对相关任务具有高度的辨别能力[31]。因此,我们在MERS的最后一个全连接层之前使用该层的输出损失来模拟Flow流的损失。我们将这些来自MERS和Flow流的特征分别表示为f cMERS和f cFlow。图2说明了MERS的训练策略。MERS具有与3D卷积的标准RGB流类似的架构和输入,但其目标是降低均方这些特征之间的误差(MSE)损失:

在网络的倒数第二层应用这种损失会使MERS的最后一层得不到训练。我们遵循两步训练程序,首先训练MERS的所有层,除了最后一层,使用均方损失。该训练提供了一个模拟Flow流的特性的流。为了执行动作识别,我们只单独训练(图中步骤2)最后一个全连接层,即分类器,使用这些“模仿”特征进行交叉熵损失。
总之,我们首先训练Flow流来对动作进行分类,使用在真实类标签y和预测类标签yFlow之间具有交叉熵损失的光流剪辑。一旦Flow流得到训练,我们就冻结它的权重。然后,通过在n层网络的前n−1层中反向传播f cMERS和f cFlow之间的MSE损失,训练MERS模拟使用RGB帧的Flow流。最后,通过训练第n层MERS,将这些幻觉流特征用于动作分类,在真实类y和通过评分sMERS预测的类之间存在交叉熵损失。请注意,交叉熵损失仅通过MERS的最后一层反向传播。在测试时,MERS与Flow流无关,只需要输入RGB。
3.2. MARS
我们的第二个策略更进一步:我们训练一个网络,在测试时仅使用RGB输入,并且没有显式的流量估计,同时利用外观和运动信息。我们称之为运动增强RGB流(MARS)。回想一下,MERS使用MSE损失将运动信息提取到运行在RGB帧上的网络中。为了用外观信息加强这种训练,我们通过在整个网络中反向传播MSE和交叉熵损失的线性组合来训练网络。换句话说,我们使用以下损失函数来训练MARS:
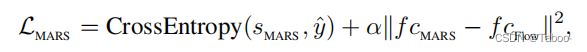
其中α是一个标量权重调制运动特征的影响。较小的α值使MARS类似于标准RGB流,较大的α值使其更接近模拟Flow流的MERS。我们在第5.3节中研究了α的影响。使用这种组合损失可以确保模拟特征和流动特征之间的差异导致交叉熵的降低,即更高的分类精度。由于流是基于RGB数据的,这个特征的区别来自于外观。因此,MARS有效地结合运动信息从光流与补充的外观信息,以便更好地进行动作分类。
为了总结我们的策略MARS,我们首先用标准交叉熵损失训练Flow流。然后我们冻结它的重量并训练MARS;参见图3。

5.2. Recognition accuracy
MERS:我们现在评估我们的训练策略MERS,其目标是模仿来自RGB输入的Flow流,以避免在测试时进行流计算。从表1所示的结果中,我们观察到,在所有数据集上,MERS和Flow之间的平均精度差异小于1%。这表明MERS是Flow流的一个很好的替代品。MERS+RGB和 RGB +光流的最小差异进一步支持了这一观察结果。此外,将Flow与MERS结合使用,几乎不会产生性能改进。总之,MERS为Flow流提供了有效的替代方案
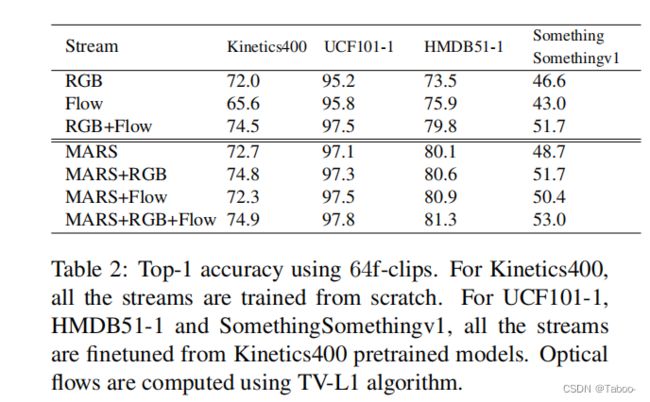
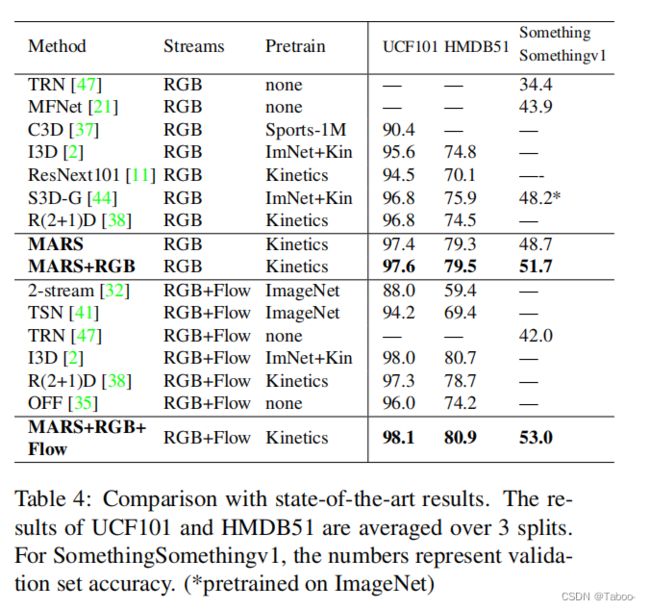
MARS.:表1还说明了我们结合基于特征和交叉熵损失(MARS)的训练策略的性能。所有的结果都对应于α = 50的设定.。我们观察到MARS的性能优于RGB和光流仅在MiniKinetics, UCF101, HMDB51和SomethingSomethingv1就有很大的差距(1%到9%之间),这表明MARS学会了有效地利用外观和运动信息。然而,在Kinetics400上,MARS的性能比RGB流差。这是由于该数据集上带有短剪辑的Flow流的性能较差,与RGB相比有14%的差异,因为许多视频大多是静态的短距离。Li et al.[22]还发现Kinetics400偏向静态信息。当使用64帧的较长剪辑时,请参见表2,RGB和光流明显较低(6.4%),MARS的性能优于RGB和光流。在所有其他数据集上,MARS获得了比RGB和Flow流更高的精度,特别是在运动至关重要的数据集上,如SomethingSomethingv1或HMDB51。在某些情况下,例如,在HMDB51的64fclips上,单独的MARS比两个流执行得更好
RGB +流模型。MARS+Flow和MARS的表现相似,这表明MARS成功地利用了运动信息,即添加Flow并不能进一步提高性能。

为了进一步了解MARS的表现优于RGB,我们比较了图5中MARS和RGB精度之间差异最高和最小的三个类(图中括号中的数字)的RGB、Flow和RGRS的性能。
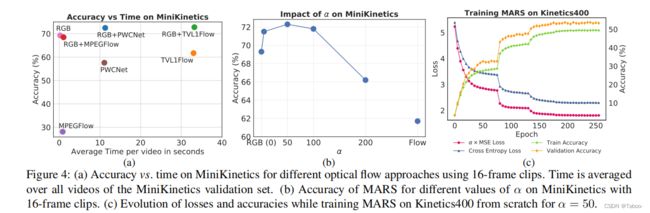
5.3. Effect of α on accuracy
MARS是通过平衡两次损失来训练的。
a)cross entropy loss between logits and ground-truth targets
b)MSE loss between averaged pooling features of MARS and Flow,
我们使用图4b中16个f剪辑的α = {5、50、100,200}值报告了MARS在MiniKinetics的平均精度。
我们还尝试将基于特征的损失应用于早期的层或对数。我们发现,在较早的层上应用这种损失会导致准确性下降,因为从RGB输入中模拟较低级别的流特征更加困难。当这种基于特征的损失应用于对数时,我们在MiniKinetics上获得了类似的性能,就像当损失应用于高级特征时一样,然而,在Kinetics400上预训练的模型不能很好地推广到其他数据集。

5.4. Impact of motion
为了进一步了解MARS和MERS学习到的特征与RGB和Flow流相比的差异,我们分析了它们在无运动情况下的表现。我们将MiniKinetics的实际测试剪辑替换为通过复制每个剪辑的中间帧创建的“静态”剪辑,从而删除运动信息。图6顶部报告的平均精度是通过对这些不重叠的连续“静态”剪辑(由16帧组成)的平均得分来计算的。图6还显示了每个流的类激活映射[48]。类激活映射有助于可视化特定于每个操作类的区分区域.我们为网络提供“静态”16f片段,并观察到RGB的准确性与静态片段略有下降,并且类激活是相关的。这表明,尽管存在3D卷积,但RGB主要关注外观。由于缺乏运动信息,MARS比RGB的落差更大,但可以正确定位相关区域,这表明MARS同时捕捉到外观和运动。MERS和Flow在静态剪辑上的表现接近随机(分类精度分别为0.5%和5.1%,以及随机的可视化区域)。在没有运动的情况下,这是预期的,并说明它们的行为相似。
Conclusion
直接放最后结果比较