基于深度学习的回声消除系统与Pytorch实现
文章作者:凌逆战
文章代码(pytorch实现):https://github.com/LXP-Never/AEC_DeepModel
文章地址(转载请指明出处):https://www.cnblogs.com/LXP-Never/p/14779360.html
写这篇文章的目的:
- 降低全国想要做基于深度学习的回声消除同学们一个入门门槛。万事开头难呀,肯定有很多小白辛苦研究了一年,连基线系统都搭建不出来的,他们肯定心心念念有谁能帮帮他们,这不,我来了。
- 在基于深度学习的回声消除这一块,网上几乎没人开源,github上能找到的几乎都是基于自适应滤波器的。我个人是很提倡开源精神的,能让更多的人能够参与进来,小到促进这个领域的进步,大到提升国家科学竞争力,哪怕只是一小步,都需要有人做出行动。
- 今天我开源,明天你开源。可能以后你们的开源项目也能帮助到我。
作者独白:
- 写这篇文章的目的在于想做基于深度学习的回声消除小白们一份入门教学,所以别对这篇文章有什么创新点或者性能上的较大期待,我只是随便搭建了一个基线系统,来进行回声消除代码的讲解,带领小白入门。
- 别问我为什么不调试好了再分享出来,时间精力有限,我的研究方向也不是回声消除,我只是感兴趣,也没人给我钱支持我研究,从一个基线模型到最终一个完善的模型,是需要巨大的时间成本的,每往下走一步需要的付出精力越多,这就是科研之路。
- 本文分享出来的系统在哪个点可以改进,可以做创新发论文,我都会在文中说明,不用感谢我
- 本文引用了诸多我原先的文章,遇到不懂的大家可能还需要多翻看原来的文章,知识需要积累,没有一蹴而就的捷径。
- 文中若有不对之处,还请各位看官多多包含,多提意见,我会积极修改的。觉得写得不错的,建议点赞关注一下,这是对我最大的支持,是给我开源精神最大的鼓励,我以后也还会努力分享好文章给大家的。
原理
传统算法
主要参考我的另外一篇文章:声学回声消除(Acoustic Echo Cancellation)原理与实现。

图中 x ( n ) x(n) x(n)为远端语音, y ( n ) y(n) y(n)为远端回声 y ( n ) = x ( n ) ∗ w ( n ) y(n)=x(n)*w(n) y(n)=x(n)∗w(n), s ( n ) s(n) s(n)为近端语音, d ( n ) d(n) d(n)为近端麦克风语音信号。
深度学习算法
回声包含线性回声和非线性回声
- 线性回声:远端语音直接 被近端麦克风接收的回声。
- 非线性回声:远端语音经过多径传播后 被近端麦克风接收的回声
线性回声可以通过 时延估计、端点检测和自适应滤波器技术较好的消除,非线性回声经过多次反射后产生了混响,声学特性复杂,很难消除。基于深度学习的回声消除技术,目前有这几个方向在做:
- 神经网络
- 自适应滤波器+神经网络
神经网络
利用神经网络较强的非线性拟合能力,直接消除线性回声和非线性回声
- 优点:过程简单,一步到位
- 缺点:可能需要更复杂或精炼的模型,才能达到更好的效果。更加考验模型的能力

自适应滤波器+神经网络
先利用简单的传统方法消除线性回声,再利用神经网络消除非线性回声
- 优点:有针对性的进行回声消除,能降低神经网络的负担
- 缺点:能一步到位的事情,就不要把事情复杂化
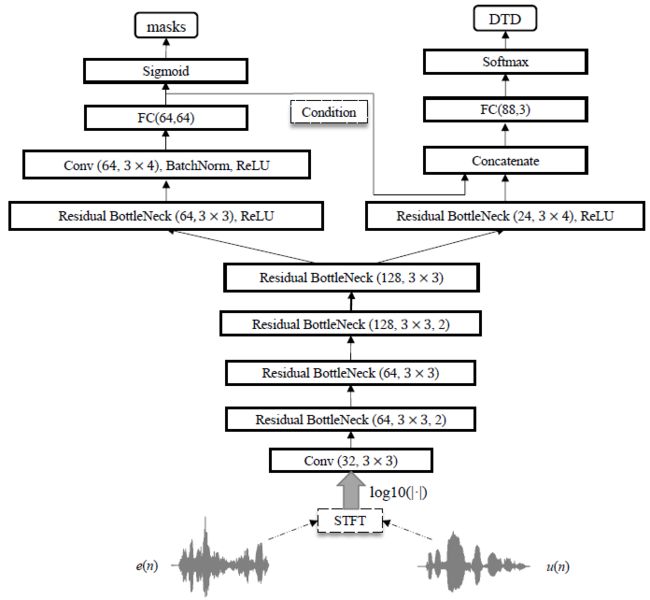
图片来源于论文:Residual acoustic echo suppression based on efficient multi-task convolutional neural network,图中 e ( n ) e(n) e(n)为自适应滤波器输出的的残差信号, u ( n ) u(n) u(n)为远端参考信号,然后利用短时间傅里叶变换(STFT)将 e ( n ) e(n) e(n)和 u ( n ) u(n) u(n)转换到频域,串联作为输入特征。同样输出mask。估计的近端振幅为:
估 计 的 近 端 振 幅 = m a s k ∗ 自 适 应 滤 波 器 输 出 估计的近端振幅=mask*自适应滤波器输出 估计的近端振幅=mask∗自适应滤波器输出
训练策略
- 频谱映射:输入(近端麦克风语音频谱,远端语音频谱),输出(近端语音频谱)
- 波形映射:输入(近端麦克风语音波形,远端语音波形),输出(近端语音波形)
- 频谱mask:输入(近端麦克风语音频谱,远端语音频谱),输出 (mask),近端语音频谱 = mask*近端麦克风语音频谱
- 时域mask:输入(近端麦克风语音波形),输出(近端语音mask, 远端回声mask),近端语音波形 = 近端语音mask*近端麦克风语音波形(这个点,我是受到语音分离的一篇文章启发,觉得可行,所以也分享在这了,目前还没有这方向的论文,科研工作者可以去尝试)
频谱映射、波形映射、频谱mask我在这篇文章中做了详细的说明,时域mask在这篇文章中做了详细的讲解。
回声消除跟语音增强和语音去混响或者语音分离很像,都是从混合语音或者污染语音中提取干净的语音。因此我们如果想要在回声消除领域找创新点的话,不妨去多看看我刚刚提的三个方向的论文。我主要参考的是语音增强和语音分离。
基线模型
本文重点来了,我搭建的基线系统是使用神经网络直接消除回声, 训练策略为 频谱mask。
数据准备
做回声消除任务主要有两类数据,真实回声数据以及合成回声数据。
- 真实回声数据:在真实环境中采集的回声,目前只有微软举办的 回声消除挑战赛中开源的数据集,我个人认为微软数据集中真实数据集有点问题,详情见博客。
- 合成回声数据:通过RIR合成的回声。可以使用任意的语音数据集,使用RIR-Generator生成房间冲击响应(推荐使用MATLAB方法),再卷积远端语音得到回声。科研界主要使用的TIMIT数据集。AEC-Challenge 数据集也有合成数据集。
我这里就偷个懒,直接使用AEC-Challenge合成好了的数据集。文件结构如下
└─Synthetic
├─TEST
│ ├─echo_signal
│ ├─farend_speech
│ ├─nearend_mic_signal
│ └─nearend_speech
├─TRAIN
│ ├─echo_signal
│ ├─farend_speech
│ ├─nearend_mic_signal
│ └─nearend_speech
└─VAL
├─echo_signal
├─farend_speech
├─nearend_mic_signal
└─nearend_speech
如果你们想用TIMIT数据集的话(毕竟很多论文都用他),可以具体参考这篇论文的数据准备方法。我个人被这篇论文给绕晕了,数据准备看似不简单,但用代码实现起来却非常难。你们可以自己去试试。
但不管用哪个数据集,我还是建议大家都把数据按照上面的文件路径结构放好,方便读取。
我搭建的基线系统实现的是频谱mask的训练策略,模型输入为**[远端语音振幅,近端麦克风振幅],模型输出IRM** mask。IRM公式可以写成以下几种形式为:
IRM = 近 端 语 音 振 幅 2 近 端 语 音 振 幅 2 + 远 端 回 声 振 幅 2 \operatorname{IRM}=\sqrt{\frac{近端语音振幅^2}{近端语音振幅^2+远端回声振幅^2}} IRM=近端语音振幅2+远端回声振幅2近端语音振幅2
I R M = 远端语音振幅 2 ( 近端语音振幅+远端回声振幅 ) 2 \mathrm{IRM}=\sqrt{\frac{\text { 远端语音振幅 }^{2}}{(\text { 近端语音振幅+远端回声振幅 })^{2}}} IRM=( 近端语音振幅+远端回声振幅 )2 远端语音振幅 2
IRM = 近 端 语 音 振 幅 2 近 端 麦 克 风 语 音 振 幅 2 \operatorname{IRM}=\sqrt{\frac{近端语音振幅^2}{近端麦克风语音振幅^2}} IRM=近端麦克风语音振幅2近端语音振幅2
我使用的是Pytorch搭建的模型,Pytorch有一套自己的数据加载方式,我之前写过一篇文章进行了总结:pytorch加载语音类自定义数据集 。如果你已经很熟悉了请继续看,本文的回声消除数据预处理代码如下:
# Author:凌逆战
# -*- coding:utf-8 -*-
"""
作用:数据预处理
"""
import glob
import os
import torch.nn.functional as F
import torch
import torchaudio
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
class FileDateset(Dataset):
def __init__(self, dataset_path="./Synthetic/TRAIN", fs=16000, win_length=320, mode="train"):
self.fs = fs
self.win_length = win_length
self.mode = mode
farend_speech_path = os.path.join(dataset_path, "farend_speech") # "./Synthetic/TRAIN/farend_speech"
nearend_mic_signal_path = os.path.join(dataset_path, "nearend_mic_signal") # "./Synthetic/TRAIN/nearend_mic_signal"
nearend_speech_path = os.path.join(dataset_path, "nearend_speech") # "./Synthetic/TRAIN/nearend_speech"
self.farend_speech_list = sorted(glob.glob(farend_speech_path+"/*.wav")) # 远端语音路径,list
self.nearend_mic_signal_list = sorted(glob.glob(nearend_mic_signal_path+"/*.wav")) # 近端麦克风语音路径,list
self.nearend_speech_list = sorted(glob.glob(nearend_speech_path+"/*.wav")) # 近端语音路径,list
def spectrogram(self, wav_path):
"""
:param wav_path: 音频路径
:return: 返回该音频的振幅和相位
"""
wav, _ = torchaudio.load(wav_path)
wav = wav.squeeze()
if len(wav) < 160000:
wav = F.pad(wav, (0,160000-len(wav)), mode="constant",value=0)
S = torch.stft(wav, n_fft=self.win_length, hop_length=self.win_length//2,
win_length=self.win_length, window=torch.hann_window(window_length=self.win_length),
center=False, return_complex=True) # (*, F,T)
magnitude = torch.abs(S) # 振幅
phase = torch.exp(1j * torch.angle(S)) # 相位
return magnitude, phase
def __getitem__(self, item):
"""__getitem__是类的专有方法,使类可以像list一样按照索引来获取元素
:param item: 索引
:return: 按 索引取出来的 元素
"""
# 远端语音 振幅,相位 (F, T),F为频点数,T为帧数
farend_speech_magnitude, farend_speech_phase = self.spectrogram(self.farend_speech_list[item]) # torch.Size([161, 999])
# 近端麦克风 振幅,相位
nearend_mic_magnitude, nearend_mic_phase = self.spectrogram(self.nearend_mic_signal_list[item])
# 近端语音 振幅,相位
nearend_speech_magnitude, nearend_speech_phase = self.spectrogram(self.nearend_speech_list[item])
X = torch.cat((farend_speech_magnitude, nearend_mic_magnitude), dim=0) # 在频点维度上进行拼接(161*2, 999),模型输入
_eps = torch.finfo(torch.float).eps # 防止分母出现0
mask_IRM = torch.sqrt(nearend_speech_magnitude ** 2/(nearend_mic_magnitude ** 2+_eps)) # IRM,模型输出
return X, mask_IRM, nearend_mic_magnitude, nearend_speech_magnitude
def __len__(self):
"""__len__是类的专有方法,获取整个数据的长度"""
return len(self.farend_speech_list)
if __name__ == "__main__":
train_set = FileDateset()
train_loader = DataLoader(train_set, batch_size=64, shuffle=True, drop_last=True)
for x, y, nearend_mic_magnitude,nearend_speech_magnitude in train_loader:
print(x.shape) # torch.Size([64, 322, 999])
print(y.shape) # torch.Size([64, 161, 999])
print(nearend_mic_magnitude.shape)
我几乎每行代码都给了注释了,各位点个赞不过分吧。还有不懂地方的各位可以在评论区指出。
如果想要创新发文章的话,数据处理这里也可以做改动:
- 更改mask方法,或者提出更好用的mask,我这篇文章总结了不少:基于深度学习的单通道语音增强,大家可以轮着试一试,反正我给出了代码。
- 我这里使用的是振幅,你们可以尝试提取一些语音其他的特征,类似 梅尔频谱特征,对数功率谱等等。
- 在强调一遍呀,现在没有基于时域mask的回声消除论文,大家快去攻略占地呀,主要参考语音分离这个领域。
模型搭建
我这里使用的是频谱mask的训练策略,模型输入为 远端语音振幅 和 近端麦克风振幅 的串联,模型输出**IRM。由上可知,输入大小为 [64, 322, 999],输出大小为 [64, 161, 999]。那么我们只需要随便搭建一个模型符合这个输入输出就行了。
**
# Author:凌逆战
# -*- coding:utf-8 -*-
"""
作用:随便搭建的模型,只要符合输入大小是[64, 322, 999],输出大小是[64, 161, 999],就能跑通
"""
import torch.nn as nn
import torch
class Base_model(nn.Module):
def __init__(self):
super(Base_model, self).__init__()
# [batch, channel, input_size] (B, F, T)
# [64, 322, 999] ---> [64, 161, 999]
self.model = nn.Sequential(
nn.Conv1d(in_channels=322, out_channels=322, kernel_size=3, stride=1, padding=1),
nn.LeakyReLU(0.2),
nn.Conv1d(in_channels=322, out_channels=322, kernel_size=3, stride=1, padding=1),
nn.LeakyReLU(0.2),
nn.Conv1d(in_channels=322, out_channels=161, kernel_size=3, stride=1, padding=1),
nn.LeakyReLU(0.2),
nn.Conv1d(in_channels=161, out_channels=161, kernel_size=3, stride=1, padding=1),
nn.Sigmoid()
)
def forward(self, x):
"""
:param x: 麦克风信号和远端信号的特征串联在一起作为输入特征 (322, 206)
:return: IRM_mask * input = 近端语音对数谱
"""
Estimated_IRM = self.model(x)
return Estimated_IRM
if __name__ == "__main__":
model = Base_model().cuda()
x = torch.randn(8, 322, 999).to("cuda") # 输入 [8, 322, 999]
y = model(x) # 输出 [8, 161, 999]
print(y.shape)
模型是一个可以创新的点,大家可以改成目前比较流行的模型来发文章。我这里就随便搭建了。
如果想要创新发文章的话,模型搭建这里也可以做改动:
- 使用时序模型来更多的考量语音帧间相关性,如LSTM、TCN,注意力机制等等,反正现在的模型五花八门,看着谁好用借鉴过来用,然后魔改一下,有良好的效果的话,就能写论文了。
训练模块
训练模块其实是最没啥创新的,所有写的正儿八经的代码,训练模型几乎都一样,但是这一块却是卡住所有新人的较大关卡。不懂的人觉得难的要死,懂的人觉得简单地一批。
训练模块的具体流程有以下几部分:
- 命令行解析
- 数据集加载
- 检测模型保存地址是否存在,如果不存在则创建
- 实例化模型
- 实例化优化器(一般使用Adam优化器)
- 准备事件文件,方便Tensorboard可视化
- 如果接着上一次检查点训练,则加载模型
- 循环epochs,开始训练(前向传播,反向传播)
- 验证模型(根据验证集的损失和度量,对模型的超参数进行调整)
import os
import torch
from torch.utils.data import DataLoader
from torch import nn
import argparse
from tensorboardX import SummaryWriter
from data_preparation.data_preparation import FileDateset
from model.Baseline import Base_model
from model.ops import pytorch_LSD
def parse_args():
parser = argparse.ArgumentParser()
# 重头开始训练 defaule=None, 继续训练defaule设置为'/**.pth'
parser.add_argument("--model_name", type=str, default=None, help="是否加载模型继续训练 '/50.pth' None")
parser.add_argument("--batch-size", type=int, default=16, help="")
parser.add_argument("--epochs", type=int, default=20)
parser.add_argument('--lr', type=float, default=3e-4, help='学习率 (default: 0.01)')
parser.add_argument('--train_data', default="./data_preparation/Synthetic/TRAIN", help='数据集的path')
parser.add_argument('--val_data', default="./data_preparation/Synthetic/VAL", help='验证样本的path')
parser.add_argument('--checkpoints_dir', default="./checkpoints/AEC_baseline", help='模型检查点文件的路径(以继续培训)')
parser.add_argument('--event_dir', default="./event_file/AEC_baseline", help='tensorboard事件文件的地址')
args = parser.parse_args()
return args
def main():
args = parse_args()
print("GPU是否可用:", torch.cuda.is_available()) # True
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 实例化 Dataset
train_set = FileDateset(dataset_path=args.train_data) # 实例化训练数据集
val_set = FileDateset(dataset_path=args.val_data) # 实例化验证数据集
# 数据加载器
train_loader = DataLoader(train_set, batch_size=args.batch_size, shuffle=False, drop_last=True)
val_loader = DataLoader(val_set, batch_size=args.batch_size, shuffle=False, drop_last=True)
# ########### 保存检查点的地址(如果检查点不存在,则创建) ############
if not os.path.exists(args.checkpoints_dir):
os.makedirs(args.checkpoints_dir)
################################
# 实例化模型 #
################################
model = Base_model().to(device) # 实例化模型
# summary(model, input_size=(322, 999)) # 模型输出 torch.Size([64, 322, 999])
# ########### 损失函数 ############
criterion = nn.MSELoss(reduce=True, size_average=True, reduction='mean')
###############################
# 创建优化器 Create optimizers #
###############################
optimizer = torch.optim.Adam(model.parameters(), lr=args.lr, )
# lr_schedule = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[10,20], gamma=0.1)
# ########### TensorBoard可视化 summary ############
writer = SummaryWriter(args.event_dir) # 创建事件文件
# ########### 加载模型检查点 ############
start_epoch = 0
if args.model_name:
print("加载模型:", args.checkpoints_dir + args.model_name)
checkpoint = torch.load(args.checkpoints_dir + args.model_name)
model.load_state_dict(checkpoint["model"])
optimizer.load_state_dict(checkpoint["optimizer"])
start_epoch = checkpoint['epoch']
# lr_schedule.load_state_dict(checkpoint['lr_schedule']) # 加载lr_scheduler
for epoch in range(start_epoch, args.epochs):
model.train() # 训练模型
for batch_idx, (train_X, train_mask, train_nearend_mic_magnitude, train_nearend_magnitude) in enumerate(
train_loader):
train_X = train_X.to(device) # 远端语音cat麦克风语音 [batch_size, 322, 999] (, F, T)
train_mask = train_mask.to(device) # IRM [batch_size 161, 999]
train_nearend_mic_magnitude = train_nearend_mic_magnitude.to(device)
train_nearend_magnitude = train_nearend_magnitude.to(device)
# 前向传播
pred_mask = model(train_X) # [batch_size, 322, 999]--> [batch_size, 161, 999]
train_loss = criterion(pred_mask, train_mask)
# 近端语音信号频谱 = mask * 麦克风信号频谱 [batch_size, 161, 999]
pred_near_spectrum = pred_mask * train_nearend_mic_magnitude
train_lsd = pytorch_LSD(train_nearend_magnitude, pred_near_spectrum)
# 反向传播
optimizer.zero_grad() # 将梯度清零
train_loss.backward() # 反向传播
optimizer.step() # 更新参数
# ########### 可视化打印 ############
print('Train Epoch: {} Loss: {:.6f} LSD: {:.6f}'.format(epoch + 1, train_loss.item(), train_lsd.item()))
# ########### TensorBoard可视化 summary ############
# lr_schedule.step() # 学习率衰减
# writer.add_scalar(tag="lr", scalar_value=model.state_dict()['param_groups'][0]['lr'], global_step=epoch + 1)
writer.add_scalar(tag="train_loss", scalar_value=train_loss.item(), global_step=epoch + 1)
writer.add_scalar(tag="train_lsd", scalar_value=train_lsd.item(), global_step=epoch + 1)
writer.flush()
# 神经网络在验证数据集上的表现
model.eval() # 测试模型
# 测试的时候不需要梯度
with torch.no_grad():
for val_batch_idx, (val_X, val_mask, val_nearend_mic_magnitude, val_nearend_magnitude) in enumerate(
val_loader):
val_X = val_X.to(device) # 远端语音cat麦克风语音 [batch_size, 322, 999] (, F, T)
val_mask = val_mask.to(device) # IRM [batch_size 161, 999]
val_nearend_mic_magnitude = val_nearend_mic_magnitude.to(device)
val_nearend_magnitude = val_nearend_magnitude.to(device)
# 前向传播
val_pred_mask = model(val_X)
val_loss = criterion(val_pred_mask, val_mask)
# 近端语音信号频谱 = mask * 麦克风信号频谱 [batch_size, 161, 999]
val_pred_near_spectrum = val_pred_mask * val_nearend_mic_magnitude
val_lsd = pytorch_LSD(val_nearend_magnitude, val_pred_near_spectrum)
# ########### 可视化打印 ############
print(' val Epoch: {} \tLoss: {:.6f}\tlsd: {:.6f}'.format(epoch + 1, val_loss.item(), val_lsd.item()))
######################
# 更新tensorboard #
######################
writer.add_scalar(tag="val_loss", scalar_value=val_loss.item(), global_step=epoch + 1)
writer.add_scalar(tag="val_lsd", scalar_value=val_lsd.item(), global_step=epoch + 1)
writer.flush()
# # ########### 保存模型 ############
if (epoch + 1) % 10 == 0:
checkpoint = {
"model": model.state_dict(),
"optimizer": optimizer.state_dict(),
"epoch": epoch + 1,
# 'lr_schedule': lr_schedule.state_dict()
}
torch.save(checkpoint, '%s/%d.pth' % (args.checkpoints_dir, epoch + 1))
if __name__ == "__main__":
main()
咳咳咳,这个注释量,你们爱了没有,很详细了,还看不懂说明你的基础太差了,别看这篇文章了,打基础去吧,基础很重要。
如果想要创新发文章的话,损失这里也可以做改动:
- 使用一个更加全面的损失函数引导模型训练,我言尽于此,剩下的靠大家自己领悟了。
推理阶段
将模型预测的近端语音振幅和近端麦克风语音相位相乘得到近端语音的复数表示,经过短时傅里叶逆变换得到近端语音波形。这里需要补一点基础知识:
复数的几种表示形式:
- 实部、虚部(直角坐标系): a + b j a+bj a+bj ( a a a是实部, b b b是虚部)
- 幅值、相位(指数系): r e j θ re^{j\theta } rejθ ( r r r是幅值, θ \theta θ是相角, e j θ e^{j\theta } ejθ是相位)
- 两种形式互换: e j θ = c o s θ + i s i n θ e^{j\theta }=cos\theta+isin\theta ejθ=cosθ+isinθ, r e j θ = r ( c o s θ + j s i n θ ) = r c o s θ + j r s i n θ re^{j\theta }=r(cos\theta+jsin\theta)=rcos\theta+jrsin\theta rejθ=r(cosθ+jsinθ)=rcosθ+jrsinθ
因此,实部 a = r c o s θ a=rcos\theta a=rcosθ,虚部 b = r s i n θ b=rsin\theta b=rsinθ,
幅值 r = a 2 + b 2 r=\sqrt{a^2+b^2} r=a2+b2,相角 θ = t a n − 1 ( b a ) \theta=tan^{-1}(\frac{b}{a}) θ=tan−1(ab)
还有一种是极坐标表示法:$r\angle \theta $
结合上述补充知识,以及复数矩阵D(F, T),我们可以得到一下频谱信息
- 复数的实部: real = np.real(D(F, T))
- 复数的虚部: imag= np.imag(D(F, T))
- 幅值: magnitude = np.abs(D(F, T)) 或 magnitude = np.sqrt(real2+imag2)
- 相角: angle = np.angle(D(F, T))
- 相位: phase = np.exp(1j * np.angle(D(F, T)))
librosa提供了专门将复数矩阵D(F, T)分离为幅值 S S S和相位 P P P的函数, D = S ∗ P D=S*P D=S∗P
librosa.magphase(D, power=1)
参数:
- D:经过stft得到的复数矩阵
- power:幅度谱的指数,例如,1代表能量,2代表功率,等等。
返回:
- D_mag:幅值 D D D,
- D_phase:相位 P P P, phase = exp(1.j * phi) , phi 是复数矩阵的相位角 np.angle(D)
当然我们也可以通过上面的公式自己求
# Author:凌逆战
# -*- coding:utf-8 -*-
"""
作用:通过模型生成近端语音
"""
import librosa
import matplotlib
import torchaudio
import torch.nn.functional as F
import torch
import matplotlib.pyplot as plt
from model.Baseline import Base_model
from matplotlib.ticker import FuncFormatter
import numpy as np
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示符号
def spectrogram(wav_path, win_length=320):
wav, _ = torchaudio.load(wav_path)
wav = wav.squeeze()
if len(wav) < 160000:
wav = F.pad(wav, (0, 160000 - len(wav)), mode="constant", value=0)
# if len(wav) != 160000:
# print(wav_path)
# print(len(wav))
S = torch.stft(wav, n_fft=win_length, hop_length=win_length // 2,
win_length=win_length, window=torch.hann_window(window_length=win_length),
center=False, return_complex=True)
magnitude = torch.abs(S)
phase = torch.exp(1j * torch.angle(S))
return magnitude, phase
fs = 16000
farend_speech = "./farend_speech/farend_speech_fileid_9992.wav"
nearend_mic_signal = "./nearend_mic_signal/nearend_mic_fileid_9992.wav"
nearend_speech = "./nearend_speech/nearend_speech_fileid_9992.wav"
echo_signal = "./echo_signal/echo_fileid_9992.wav"
print("GPU是否可用:", torch.cuda.is_available()) # True
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
farend_speech_magnitude, farend_speech_phase = spectrogram(farend_speech) # 远端语音 振幅,相位
nearend_mic_magnitude, nearend_mic_phase = spectrogram(nearend_mic_signal) # 近端麦克风语音 振幅,相位
nearend_speech_magnitude, nearend_speech_phase = spectrogram(nearend_speech) # 近端语音振 幅,相位
farend_speech_magnitude = farend_speech_magnitude.to(device)
nearend_mic_phase = nearend_mic_phase.to(device)
nearend_mic_magnitude = nearend_mic_magnitude.to(device)
nearend_speech_magnitude = nearend_speech_magnitude.to(device)
nearend_speech_phase = nearend_speech_phase.to(device)
model = Base_model().to(device) # 实例化模型
checkpoint = torch.load("../checkpoints/AEC_baseline/10.pth")
model.load_state_dict(checkpoint["model"])
X = torch.cat((farend_speech_magnitude, nearend_mic_magnitude), dim=0)
X = X.unsqueeze(0)
per_mask = model(X) # [1, 322, 999]-->[1, 161, 999]
per_nearend_magnitude = per_mask * nearend_mic_magnitude # 预测的近端语音 振幅
complex_stft = per_nearend_magnitude * nearend_mic_phase # 振幅*相位=语音复数表示
print("complex_stft", complex_stft.shape) # [1, 161, 999]
per_nearend = torch.istft(complex_stft, n_fft=320, hop_length=160, win_length=320,
window=torch.hann_window(window_length=320).to("cuda"))
torchaudio.save("./predict/nearend_speech_fileid_9992.wav", src=per_nearend.cpu().detach(), sample_rate=fs)
# print("近端语音", per_nearend.shape) # [1, 159680]
y, _ = librosa.load(nearend_speech, sr=fs)
time_y = np.arange(0, len(y)) * (1.0 / fs)
recover_wav, _ = librosa.load("./predict/nearend_speech_fileid_9992.wav", sr=16000)
time_recover = np.arange(0, len(recover_wav)) * (1.0 / fs)
plt.figure(figsize=(8,6))
ax_1 = plt.subplot(3, 1, 1)
plt.title("近端语音和预测近端波形图", fontsize=14)
plt.plot(time_y, y, label="近端语音")
plt.plot(time_recover, recover_wav, label="深度学习生成的近端语音波形")
plt.xlabel('时间/s', fontsize=14)
plt.ylabel('幅值', fontsize=14)
plt.xticks(fontsize=14)
plt.yticks(fontsize=14)
plt.subplots_adjust(top=0.932, bottom=0.085, left=0.110, right=0.998)
plt.subplots_adjust(hspace=0.809, wspace=0.365) # 调整子图间距
plt.legend()
norm = matplotlib.colors.Normalize(vmin=-200, vmax=-40)
ax_2 = plt.subplot(3, 1, 2)
plt.title("近端语音频谱", fontsize=14)
plt.specgram(y, Fs=fs, scale_by_freq=True, sides='default', cmap="jet", norm=norm)
plt.xlabel('时间/s', fontsize=14)
plt.ylabel('频率/kHz', fontsize=14)
plt.xticks(fontsize=14)
plt.yticks(fontsize=14)
plt.subplots_adjust(top=0.932, bottom=0.085, left=0.110, right=0.998)
plt.subplots_adjust(hspace=0.809, wspace=0.365) # 调整子图间距
ax_3 = plt.subplot(3, 1, 3)
plt.title("深度学习生成的近端语音频谱", fontsize=14)
plt.specgram(recover_wav, Fs=fs, scale_by_freq=True, sides='default', cmap="jet", norm=norm)
plt.xlabel('时间/s', fontsize=14)
plt.ylabel('频率/kHz', fontsize=14)
plt.xticks(fontsize=14)
plt.yticks(fontsize=14)
plt.subplots_adjust(top=0.932, bottom=0.085, left=0.110, right=0.998)
plt.subplots_adjust(hspace=0.809, wspace=0.365) # 调整子图间距
def formatnum(x, pos):
return '$%d$' % (x / 1000)
formatter = FuncFormatter(formatnum)
ax_2.yaxis.set_major_formatter(formatter)
ax_3.yaxis.set_major_formatter(formatter)
plt.show()
为了方便可视化对比,我顺便把波形图可语谱图画了出来

如果这篇文章对你有帮助,点个赞是对我最大的鼓励。
关注我,我将分享更有价值的文章!