Python学习笔记之支持向量机SVM实例,及SVC参数介绍
svm理论参考:http://blog.csdn.net/lisi1129/article/details/70209945?locationNum=8&fps=1
svm参数详解:https://www.cnblogs.com/luyaoblog/p/6775342.html
Python中支持向量机模块from sklearn import svm(support vector machine)
svm包含支持向量分类SVC(support vector classification)用于分类和支持向量回归SVR(support vector regression),用于预测
世界著名的鸢尾花SVM二特征分类详解
鸢尾花数据是一个简易有趣的数据集。这个数据集来源于科学家在一岛上找到一种花的三种不同亚类别,分别叫做setosa,versicolor,virginica。但是这三个种类并不是很好分辩,所以他们又从花萼长度,花萼宽度,花瓣长度,花瓣宽度这四个角度测量不同的种类用于定量分析。基于这四个特征,这些数据成了一个多重变量分析的数据集。
本教程基于Python2.7
先附上完整的代码:
#_*_ coding:utf-8 _*_
#支持向量机实战
#recoding:http://blog.csdn.net/lisi1129/article/details/70209945?locationNum=8&fps=1
#recoding:https://www.aliyun.com/zixun/content/5_82_2047913.html
import pandas as pd
from sklearn.model_selection import train_test_split
import numpy as np
from sklearn import svm
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
import matplotlib as mpl
from numpy import ravel
iris_feature=u"花萼长度",u"花萼宽度",u"花瓣长度",u"花瓣宽度"
if __name__=="__main__": #此句代码的意思是,当此脚本被直接执行时,name==main为真,当此脚本被调用时,name==main为假
path="iris.data"
data=pd.read_csv(path,header=None)
x,y=data[range(4)],data[4]
y=pd.Categorical(y).codes
x=x[[0,1]]
x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=0,train_size=0.6) #http://blog.csdn.net/u011089523/article/details/72810720
print "x_train:",x_train
print "y_train:",y_train
#分类器
clf=svm.SVC(C=1,kernel="poly",decision_function_shape="ovo") #http://blog.csdn.net/szlcw1/article/details/52336824
clf.fit(x_train,y_train.ravel())
print clf.score(x_train,y_train)#精度
print '训练集准确率:',accuracy_score(y_train,clf.predict(x_train))
print clf.score(x_test,y_test)#打印测试准确度
print '测试集准确率:',accuracy_score(y_test,clf.predict(x_test))
x1_min,x2_min=x.min()
x1_max,x2_max=x.max()
x1,x2=np.mgrid[x1_min:x1_max:500j,x2_min:x2_max:500j]
grid_test=np.stack((x1.flat,x2.flat),axis=1)
print 'grid_test=\n',grid_test
Z=clf.decision_function(grid_test)#计算样本点到分割超平面的函数距离
Z=Z[:,0].reshape(x1.shape)
print "decision_function:",Z
grid_hat=clf.predict(grid_test)# 预测分类值
grid_hat=grid_hat.reshape(x1.shape)# 使之与输入的形状相同
mpl.rcParams['font.sans-serif']=[u'SimHei']
mpl.rcParams['axes.unicode_minus']=False
cm_light = mpl.colors.ListedColormap(['#A0FFA0', '#FFA0A0', '#A0A0FF'])#指定默认字体
cm_dark=mpl.colors.ListedColormap(['r','g','b'])
plt.figure(facecolor='w')
plt.pcolormesh(x1,x2,grid_hat,cmap=cm_light)#绘制背景
plt.scatter(x[0],x[1],c=y,edgecolors='k',s=50,cmap=cm_dark)#scatter中edgecolors是指描绘点的边缘色彩,s指描绘点的大小,cmap指点的颜色
plt.scatter(x_test[0], x_test[1], s=120, facecolors='none', zorder=10) # 圈中测试集样本
plt.xlabel(iris_feature[0], fontsize=13)
plt.ylabel(iris_feature[1], fontsize=13)
plt.xlim(x1_min, x1_max)#xlim使图形的边界
plt.ylim(x2_min, x2_max)
plt.title(u'鸢尾花SVM二特征分类', fontsize=16)
plt.grid(b=True, ls=':')
plt.show()样本数据:https://pan.baidu.com/s/1sH7fxpOZkN1uC0QE9JWwgg
鸢尾花数据格式如下:前面四个是鸢尾花的四个特征,最后是鸢尾花的种类
1.读取数据,并进行训练样本和测试样本的划分。
data=pd.read_csv(path,header=None)
pd.read_csv(path,header,sep,delimiter,names,)还有很多参数,
path:所要读取文件的路径,也可以是url
sep:指定分隔符,不指定参数默认为使用","分割,
delimiter:定界符,备选分隔符(如果指定改参数,则sep参数失效)
header:指定行数来作为列名,数据开始行数,如果文件中没有列名,则默认为0,否则设置为None。
读取后的数据data形式如下:
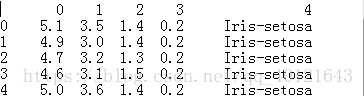
pandas的数据类型有两种,dataframe和series。datafram是一个二维的表结构,series是一维数据类型。
将数据自动分割成行列。
x,y=data[range(4),data[4]]
y=pd.Categorical(y).codes
将鸢尾花的种类y进行编码,三种种类分别为0 1 2,其中Categoricals有效地编码了包含大量重复文本的数据,极大的提高了这些数据处理的能力。
x=x[[0,1]]取样本的前两个特征作为本实例的demo
分配训练样本和测试样本的比例。
x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=0,train_size=0.6)
其中的x代表鸢尾花的特征,y代表鸢尾花的种类,根据x识别y。train_size=0.6是训练样本和测试样本的比例。
random_state是随机数的种子,其实就是该组随机数的编号,需要重复实验时,保证得到一组一样的随机数,比如你每次都填1,其他参数一样的情况下,你得到的随机数组是一样的,填写0和不填,每次都会不一样。
2,build分类器
clf=svm.SVC(C=50,kernel="poly",decision_function_shape="ovo")
SVC完整参数:
sklearn.svm.SVC(C,kernel,degree,gamma,coef0,shrinking,probability,tol,cache_size,class_weight,verbose,max_iter,decision_function_shape,random_state)
svc中的参数是针对不同的核函数需要填写的,具体如下图
0 -- linear: u'*v 1 -- polynomial: (gamma*u'*v + coef0)^degree 2 -- radial basis function: exp(-gamma*|u-v|^2) 3 -- sigmoid: tanh(gamma*u'*v + coef0) 4 -- precomputed kernel (kernel values in training_set_file)C:惩罚参数
默认值为1.惩罚参数是由于松弛变量而加入的,它表征的是对错误分类的惩罚程度,也就是不允许分类出错的程度。c越大,表明越不允许分类出错,但是c越大可能overfitting,比如说将训练样本中的噪声也没放过,加以学习,并没有意义,泛华效果也可能太低。c太小的话趋于0的话,分类将不会关注分类是否正确的问题,只要求间隔越大越好,此时分类也没有意义。
kernel:核函数
作用:核函数的引入是为了解决线性不可分的问题,将分类点映射到高维空间中以后,转化为可线性分割的问题。
(1)线性核函数(linear) K(x,xi)=x*xi
(2)多项式核(poly) K(x,xi)=((x*xi)+1)d
(3)径向基核(RBF) K(x,xi)=exp(-||x-xi||2σ2) gama=1/(2*σ2)
(4)傅里叶核 K(x,xi)=1−q22(1−2qcos(x−xi)+q2)
(5)样条核 K(x,xi)=B2n+1(x−xi)
(6)Sigmoid核函数 K(x,xi)=tanh(κ(x,xi)−δ)
核函数的选择:一是利用专家的先验只是预先选定核函数;二是采用Cross-Validation方法,即进行核函数选取时分别使用不同的核函数,归纳误差最小的核函数就是最好的核函数,如针对傅里叶核、RBF核、结合信号处理问题中的函数回归问题,通过仿真实验,对比分析在相同数据条件下,采用傅里叶核比RBF的svm误差小很多。
最常用的核函数是Linear核与RBF核。
1)Linear核:主要用于线性可分的情形,参数少,速度快,对于一般数据,分类效果已经很理想了。
2)RBF核:主要用于线性不可分的情形,参数多,分类结果非常依赖于参数,很多人是通过训练数据的交叉验证来寻找合适的参数,比较耗时间。应用最广的核函数就是RBF核了,无论是小样本还是大样本,高维还是低维,RBF核函数均适用,它相比其他核函数有一下有点:
RBF优点:
1,它可以将一个样本映射到一个更高维的空间,而且线性核函数只是RBF的一个特例,也就是说如果考虑使用RBF,那么就没哟必要考虑线性核函数了。
2,与多项式核函数相比,RBF需要 确定的参数少,核函数的参数的多少直接影响函数的复杂程度,另外,当多项式的阶数高是,核函数的元素之将发散,但是RBF则在上, 会减少数值的计算困难。
3,对于某些参数,RBF核Sigmoid具有相似的性能。
degree:多项式poly核函数的维度,默认为3,选择掐核函数时会被忽略。
C:惩罚系数,即对误差的宽容度。c越高,说明越不能容忍出现误差,容易过拟合。C越小,容易欠拟合。C过大或过小,泛化能力变差。
gamma:RBF,poly,核sigmiod核函数的参数,默认是auto。
gama: 这里面需要注意的就是gamma的物理意义,大家提到很多的RBF的幅宽,它会影响每个支持向量对应的高斯的作用范围,从而影响泛化性能。我的理解:如果gamma设的太大, 会很小,很小的高斯分布长得又高又瘦, 会造成只会作用于支持向量样本附近,对于未知样本分类效果很差,存在训练准确率可以很高,(如果让无穷小,则理论上,高斯核的SVM可以拟合任何非线性数据,但容易过拟合)而测试准确率不高的可能,就是通常说的过训练;而如果设的过小,则会造成平滑效应太大,无法在训练集上得到特别高的准确率,也会影响测试集的准确率。
会很小,很小的高斯分布长得又高又瘦, 会造成只会作用于支持向量样本附近,对于未知样本分类效果很差,存在训练准确率可以很高,(如果让无穷小,则理论上,高斯核的SVM可以拟合任何非线性数据,但容易过拟合)而测试准确率不高的可能,就是通常说的过训练;而如果设的过小,则会造成平滑效应太大,无法在训练集上得到特别高的准确率,也会影响测试集的准确率。
用cross-validation和grid-search 得到最优的c和g,
code0:核函数的常数项,对于poly核sigmoid有用
probability:是否采用概率估计,默认为false。
shrinking:是否采用shrinking heuristic方法,默认为true。
tol:停止训练的误差值大小,默认为1e-3.
cache_size:核函数cache缓存的大小,默认为200。
class_weight:类别的权重,字典形式传递,设置第几类的参数C为weight*C(C-SVC中的c)。
decision_function_shape:原始的svm只是用与二分类的问题,如果将其扩展到多分类问题,就要采取一定的融合策略,这里提供了三种选择,‘ovo’一对一,就是两两之间进行划分,‘ovr’一对多就是一类与其他类别进行划分,返回的是样本数,类别数。
random_state:在使用svm训练时候,是否先将训练数据打乱顺序,用来提高分类精度,如果给定的是一个整数,则该整数是随机序列的种子值。
x1,x2=np.mgrid[x1_min:x1_max:500j,x2_min:x2_max:500j]
grid_test=np.stack((x1.flat,x2.flat),axis=1)np.mgrid生成采样点,下面对mgrid函数的使用做详细介绍
假如需要回执z=x^2+y^2的图像 x=1~3 y=4~6
划分x轴和y轴
step1:x扩展,向右扩展
[1 1 1]
[2 2 2]
[3 3 3]
step2:y扩展(朝下扩展)
[4 5 6]
[4 5 6]
[4 5 6]
step3:定位(xi,yi)
[(1,4) (1,5) (1,6)]
[(2,4) (2,5) (2,6)]
[(3,4) (3,5) (3,6)]
step:将(xi,yi)带入z(x,y)中