detectron2入门学习二:实现FruitsNut水果坚果分割任务数据集Mask与coco格式转换处理
学习目标:
将数据集进行Mask掩膜、coco标注等不同格式的转换
工程文件地址:
https://github.com/fenglingbai/FruitsNutsHandle
一、单实例的coco标注与Mask掩膜相互转换:
掩膜转换的方式有多种,每个实例生成一张掩膜或者每张图片生成一张掩膜,对于初学者来说,单实例的coco数据集这里采用已有的工具进行转换比较好,这里采用pycococreator进行转化:
pycococreator工程文件地址:
https://github.com/waspinator/pycococreator
由于官方给出的安装方式是在linux上进行,windows可以选择下载工程文件后在当前的工程文件种打开命令提示符,如果运行环境是在虚拟环境中,则激活虚拟环境,之后输入如下命令即可:
python setup.py install
相关的说明可以参考该网址:
https://patrickwasp.com/create-your-own-coco-style-dataset/
检验是否成功安装可以输入如下指令:
from pycococreatortools import pycococreatortools
如果没有报错即可。
1.1 每个实例转换为一张灰度掩模图
根据标注数据进行实例掩膜的生成。
根据pycococreator的示例,掩膜的命名方式主要为:

这里在掩膜的生成的命名种直接采用其要求的命名格式,这样即可直接进行后续的转换工作。
相关代码与注释如图所示:
def objectSingleMask(annFile, classes_names, savePath):
"""
从标注文件annFile提取符合类别classes_names的掩膜,并进行保存
由于每一张图片仅有一张实例,因此默认为灰度图
:param annFile: json注释文件
:param classes_names: 需要提取掩膜的类别名
:param savePath: 保存路径
:return:
"""
# 获取COCO_json的数据
coco = COCO(annFile)
# 拿到所有需要的图片数据的id - 我需要的类别的categories的id是多少
classes_ids = coco.getCatIds(catNms=classes_names)
# 取所有类别的并集的所有图片id
# 如果想要交集,不需要循环,直接把所有类别作为参数输入,即可得到所有类别都包含的图片
imgIds_list = []
# 循环取出每个类别id对应的有哪些图片并获取图片的id号
for idx in classes_ids:
imgidx = coco.getImgIds(catIds=idx) # 将该类别的所有图片id好放入到一个列表中
imgIds_list += imgidx
print("搜索id... ", imgidx)
# 去除重复的图片
imgIds_list = list(set(imgIds_list)) # 把多种类别对应的相同图片id合并
# 一次性获取所有图像的信息
image_info_list = coco.loadImgs(imgIds_list)
# 对每张图片的每个实例生成一个mask
annotation_id = 1
for imageinfo in image_info_list:
for singleClassIdIndex in range(len(classes_ids)):
singleClassId = classes_ids[singleClassIdIndex]
# 找到掩膜的标号id
singleClassAnnId = coco.getAnnIds(imgIds=imageinfo['id'], catIds=[singleClassId], iscrowd=None)
# 提取掩膜的分割数据
singleClassAnnList = coco.loadAnns(singleClassAnnId)
for singleItem in singleClassAnnList:
# 寻找每一个实例
singleItemMask = coco.annToMask(singleItem)
# 将实例转换为0~255的uint8,进行保存
singleItemMask = (singleItemMask * 255).astype(np.uint8)
# __.png
file_name = savePath + '/' + imageinfo['file_name'][:-4] + '_' + \
classes_names[singleClassIdIndex] + \
'_' + '%d' % annotation_id + '.png'
cv2.imwrite(file_name, singleItemMask)
print("已保存mask图片: ", file_name)
annotation_id = annotation_id + 1
程序运行时直接输入:
# 标注文件地址
jsondir = "data/trainval.json"
# 单掩膜
singleMaskDir = "mydata/singleMask"
mkr(singleMaskDir)
objectSingleMask(jsondir, ['date', 'fig', 'hazelnut'], singleMaskDir)
即可。
文件夹展示:

1.2 根据单个实例的掩模图重新生成coco标注文件
# 将单幅掩模图转换为json文件
# https://patrickwasp.com/create-your-own-coco-style-dataset/
import datetime
import json
import os
import re
import fnmatch
from PIL import Image
import numpy as np
from pycococreatortools import pycococreatortools
def filter_for_jpeg(root, files):
"""
提取文件夹中符合相关后缀的图片文件
:param root: 文件路径
:param files: 文件路径下的文件列表
:return: 符合命名条件的文件
"""
file_types = ['*.jpeg', '*.jpg', '*.png']
file_types = r'|'.join([fnmatch.translate(x) for x in file_types])
files = [os.path.join(root, f) for f in files]
files = [f for f in files if re.match(file_types, f)]
return files
def filter_for_annotations(root, files, image_filename):
"""
提取文件夹中符合相关后缀的coco注释文件,
由于png图片为无损,因此一般采用png格式作为掩膜格式
:param root: 文件路径
:param files: 文件路径下的文件列表
:param image_filename: coco注释文件对应的图片文件
:return:
"""
file_types = ['*.png']
file_types = r'|'.join([fnmatch.translate(x) for x in file_types])
basename_no_extension = os.path.splitext(os.path.basename(image_filename))[0]
file_name_prefix = basename_no_extension + '.*'
files = [os.path.join(root, f) for f in files]
files = [f for f in files if re.match(file_types, f)]
files = [f for f in files if re.match(file_name_prefix, os.path.splitext(os.path.basename(f))[0])]
return files
if __name__ == "__main__":
# 路径设置
ROOT_DIR = 'data'
IMAGE_DIR = os.path.join(ROOT_DIR, "images")
ANNOTATION_DIR = "mydata/singleMask"
SAVE_PATH_DIR = "myjson/singleJson.json"
# 注释文件的相关信息,可有可无
INFO = {
"description": "FruitsNuts Dataset",
"url": "https://github.com/fenglingbai/FruitsNutsHandle",
"version": "0.1.0",
"year": 2022,
"contributor": "fenglingbai",
"date_created": datetime.datetime.utcnow().isoformat(' ')
}
LICENSES = [
{
"id": 1,
"name": "None",
"url": "None"
}
]
# 根据自己的需要添加种类
CATEGORIES = [
{
"supercategory": "date",
"id": 1,
"name": "date"
},
{
"supercategory": "fig",
"id": 2,
"name": "fig"
},
{
"supercategory": "hazelnut",
"id": 3,
"name": "hazelnut"
}
]
# json文件的输出字典
coco_output = {
"info": INFO,
"licenses": LICENSES,
"categories": CATEGORIES,
"images": [],
"annotations": []
}
# 注释标号的初始化
image_id = 0
segmentation_id = 1
# 筛选数据的原图文件
for root, _, files in os.walk(IMAGE_DIR):
image_files = filter_for_jpeg(root, files)
# 遍历每一个原图文件
for image_filename in image_files:
image = Image.open(image_filename)
image_info = pycococreatortools.create_image_info(
image_id, os.path.basename(image_filename), image.size)
coco_output["images"].append(image_info)
# 筛选原图文件对应的标注文件
for root, _, files in os.walk(ANNOTATION_DIR):
annotation_files = filter_for_annotations(root, files, image_filename)
# 遍历每一个标注文件
for annotation_filename in annotation_files:
print(annotation_filename)
class_id = [x['id'] for x in CATEGORIES if x['name'] in annotation_filename][0]
category_info = {'id': class_id, 'is_crowd': 'crowd' in image_filename}
binary_mask = np.asarray(Image.open(annotation_filename)
.convert('1')).astype(np.uint8)
annotation_info = pycococreatortools.create_annotation_info(
segmentation_id, image_id, category_info, binary_mask,
image.size, tolerance=2)
if annotation_info is not None:
coco_output["annotations"].append(annotation_info)
segmentation_id = segmentation_id + 1
image_id = image_id + 1
# 存储json标注文件
with open(SAVE_PATH_DIR, 'w') as output_json_file:
json.dump(coco_output, output_json_file)
print('ok')
运行后的json文件可以在对应设置的文件路径中找到。
二、单图片的coco标注与Mask掩膜相互转换:
2.1 单图片进行掩膜转化
def objectMultyMask(annFile, classes_names, savePath, type="color"):
"""
从标注文件annFile提取符合类别classes_names的掩膜,并进行保存
:param annFile: 标注文件
:param classes_names: 需要提取的类别名
:param savePath: 掩膜保存的路径
:param type: 保存的色彩选择,
color使用matplot默认保存为彩色,
gray使用cv2保存为灰度图
:return:
"""
# 获取COCO_json的数据
coco = COCO(annFile)
# 拿到所有需要的图片数据的id - 我需要的类别的categories的id是多少
classes_ids = coco.getCatIds(catNms=classes_names)
# 取所有类别的并集的所有图片id
# 如果想要交集,不需要循环,直接把所有类别作为参数输入,即可得到所有类别都包含的图片
imgIds_list = []
# 循环取出每个类别id对应的有哪些图片并获取图片的id号
for idx in classes_ids:
imgidx = coco.getImgIds(catIds=idx) # 将该类别的所有图片id好放入到一个列表中
imgIds_list += imgidx
print("搜索id... ", imgidx)
# 去除重复的图片
imgIds_list = list(set(imgIds_list)) # 把多种类别对应的相同图片id合并
# 一次性获取所有图像的信息
image_info_list = coco.loadImgs(imgIds_list)
# 对每张图片生成一个mask
for imageinfo in image_info_list:
mask_pic = np.zeros(shape=(imageinfo['height'], imageinfo['width']))
for singleClassId in classes_ids:
# 每一类标记进行生成掩膜
singleClassMask = np.zeros(shape=(imageinfo['height'], imageinfo['width']))
# 找到掩膜的标号id
singleClassAnnId = coco.getAnnIds(imgIds=imageinfo['id'], catIds=[singleClassId], iscrowd=None)
# 提取掩膜的分割数据
singleClassAnnList = coco.loadAnns(singleClassAnnId)
for singleItem in singleClassAnnList:
# 将每一个实例进行叠加
singleItemMask = coco.annToMask(singleItem)
singleClassMask += singleItemMask
# 最后在原图上叠加该类的掩膜信息
singleClassMask[singleClassMask > 0] = 1
# 重叠的部分使用后者的掩膜信息
mask_pic[singleClassMask == 1] = 0
mask_pic = mask_pic + singleClassMask * singleClassId
# 保存图片
mask_pic = mask_pic.astype(np.uint8)
file_name = savePath + '/' + imageinfo['file_name'][:-4] + '.png'
if type == "color":
plt.imsave(file_name, mask_pic)
else:
cv2.imwrite(file_name, mask_pic)
print("已保存mask图片: ", file_name)
图像在保存种,每一个像素的值代表了其中该像素所属的类别。因此如果需要可视化展示可以在"type"属性中选择"color",否则选择"gary"。程序运行时直接输入:
multyMaskGrayDir = "mydata/multyMaskGray"
mkr(multyMaskGrayDir)
objectMultyMask(jsondir, ['date', 'fig', 'hazelnut'], multyMaskGrayDir, type="gray")
multyMaskColorDir = "mydata/multyMaskColor"
mkr(multyMaskColorDir)
objectMultyMask(jsondir, ['date', 'fig', 'hazelnut'], multyMaskColorDir, type="color")
多掩膜的彩色展示如图所示:

灰度图展示由于像素值为0,1,2,3,以8位图片展示全部为黑色,肉眼难以辨认,这里不再展示。
2.2 单图片掩膜进行coco注释文件转化
在上文中我们选择了pycococreator工具,这里也可以采用cv2中的工具进行实现
import cv2
import os
import numpy as np
import json
if __name__ == '__main__':
# 初始化对应的类别名与id
my_label = {"background": 0,
"date": 1,
"fig": 2,
"hazelnut": 3
}
# 初始化需要保存的coco字典
coco = dict()
coco['images'] = []
coco['type'] = 'instances'
coco['annotations'] = []
coco['categories'] = []
# 初始化相关的变量与标记
image_set = set()
category_item_id = 0
annotation_id = 0
# 1.添加coco的categories
my_label = sorted(my_label.items(), key=lambda item: item[1])
for val in my_label:
category_item = dict()
category_item['supercategory'] = 'none'
category_item_id = val[1]
if 0 == category_item_id:
continue
category_item['id'] = category_item_id
category_item['name'] = val[0]
coco['categories'].append(category_item)
# 2.添加coco的images
IMAGE_DIR = "data/images/"
ANNOTATION_DIR = "mydata/multyMaskGray/"
SAVE_JSON_DIR = "myjson/multyMaskGray.json"
# 加载图片信息
imageListFile = os.listdir(IMAGE_DIR)
imageListFile.sort(key=lambda x: int(x[:-4]))
annotationListFile = os.listdir(ANNOTATION_DIR)
annotationListFile.sort(key=lambda x: int(x[:-4]))
assert len(imageListFile) == len(annotationListFile)
for imageId in range(len(imageListFile)):
assert imageListFile[imageId][0:-4] == annotationListFile[imageId][0:-4]
annotationPath = ANNOTATION_DIR + annotationListFile[imageId]
annotationGray = cv2.imread(annotationPath, -1)
if len(annotationGray.shape) == 3:
annotationGray = cv2.cvtColor(annotationGray, cv2.COLOR_BGR2GRAY)
image_item = dict()
image_item['id'] = imageId
image_item['file_name'] = imageListFile[imageId]
image_item['width'] = annotationGray.shape[1] # size['width']
image_item['height'] = annotationGray.shape[0] # size['height']
coco['images'].append(image_item)
image_set.add(imageListFile[imageId])
# 3.添加coco的annotations
for current_category_id in range(1, len(my_label)):
img_bi = np.zeros(annotationGray.shape, dtype='uint8')
img_bi[annotationGray == current_category_id] = 255
my_contours, _ = cv2.findContours(img_bi, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
for c in my_contours:
area_t = cv2.contourArea(c)
# 这里设定阈值进行筛选
if 0 == len(c) or area_t < 20:
continue
L_pt = c
# x,y,w,h
bbox = cv2.boundingRect(L_pt)
x1, y1, w1, h1 = bbox
# 标记超过原图界限,进行忽略
if x1 < 0 or y1 < 0 or x1 + w1 > annotationGray.shape[1] or y1 + h1 > annotationGray.shape[0]:
continue
seg = []
for val in L_pt:
x = val[0][0]
y = val[0][1]
seg.append(int(x))
seg.append(int(y))
bbox = list(bbox)
annotation_item = dict()
annotation_item['segmentation'] = []
annotation_item['segmentation'].append(seg)
annotation_item['area'] = area_t
annotation_item['iscrowd'] = 0
annotation_item['ignore'] = 0
annotation_item['image_id'] = imageId
annotation_item['bbox'] = bbox
annotation_item['category_id'] = current_category_id
annotation_id += 1
annotation_item['id'] = annotation_id
coco['annotations'].append(annotation_item)
json.dump(coco, open(SAVE_JSON_DIR, 'w'))
print('ok')
运行后的json文件可以在对应设置的文件路径中找到。
三、运行结果展示:
3.1 单实例的注释文件训练预测展示:

3.2 单图片的注释文件训练预测展示:
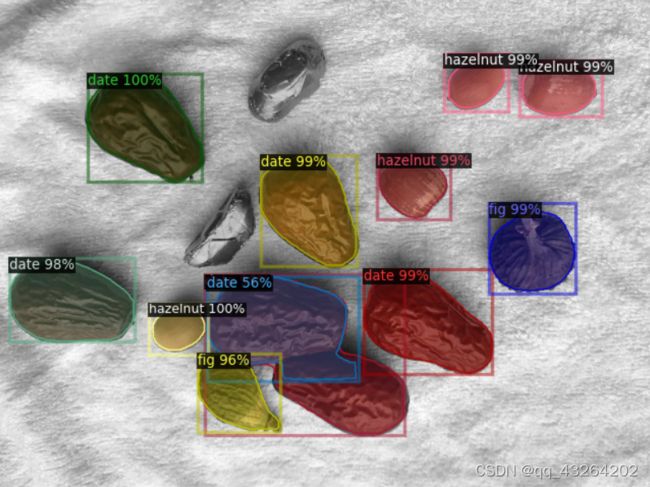
可以看出,单实例的注释文件训练效果优于单图片的注释文件,这是由于单图片的掩膜存在两实例连接或遮挡的情况,这种情况下难以将不同实例进行分离,从而使得训练数据是将整体作为一个实例进行训练。同时预测结果经过了NMS处理,也会将这相邻的物体判定为单个实例,因此效果较差。