轻量级网络——MobileNet系列学习(理论篇)
目录
一、MobileNetV1
1.1 Depthwise separable convolution(深度级可分离卷积)
参数对比
1.2 MobileNet网络结构
1.3 MobileNet网络结构
1.3MobileNet的TensorFlow实现
二、MobIleNetV2
2.1 对比 MobileNet V1 与 V2 的微结构
2.2 MobileNet V2 的网络结构
三、MoblieNetV3
3.1 V3的特点
3.2 网络结构
一、MobileNetV1
论文地址:https://arxiv.org/abs/1704.04861
代码地址:参考链接1中的代码GitHub - xiaohu2015/DeepLearning_tutorials: The deeplearning algorithms implemented by tensorflow
参考资料:
1. 【深度学习MobileNet】——深刻解读MobileNet网络结构_ciky奇的博客-CSDN博客_mobilenet网络结构
2. 深度可分离卷积 - 知乎
3. 卷积操作的基础知识_王小鹏鹏的博客-CSDN博客_卷积操作
4.如何理解卷积神经网络中的权值共享_zxucver的博客-CSDN博客_权值共享(权值共享解释的好)
Google2017年提出的移动端模型MobileNet,其核心是采用了可分解的depthwise separable convolution,其不仅可以降低模型计算复杂度,而且可以大大降低模型大小。
MobileNet的提出是为了解决模型过于庞大对内存要求过高又无法满足实时性的问题。目前的研究总结来看分为两个方向:一是对训练好的复杂模型进行压缩得到小模型;二是直接设计小模型并进行训练。不管如何,其目标在保持模型性能(accuracy)的前提下降低模型大小(parameters size),同时提升模型速度(speed, low latency)。MobileNet是通过直接设计小模型并进行训练的。
1.1 Depthwise separable convolution(深度级可分离卷积)
MobileNet的基本单元是深度级可分离卷积(depthwise separable convolution),深度级可分离卷积其实是一种可分解卷积操作(factorized convolutions),其可以分解为两个更小的操作:depthwise convolution和pointwise convolution。depthwise separable convolution首先是采用depthwise convolution对不同输入通道分别进行卷积,然后采用pointwise convolution将上面的输出再进行结合,这样其实整体效果和一个标准卷积是差不多的,但是会大大减少计算量和模型参数量。
例子介绍下常规卷积操作:卷积的基础知识可以参阅链接3。
对于一张5×5像素、三通道(shape为5×5×3),经过3×3卷积核的卷积层(假设输出通道数为4,则卷积核shape为3×3×3×4,最终输出4个Feature Map,如果有same padding则尺寸与输入层相同(5×5),如果没有则为尺寸变为3×3。(图源看水印)
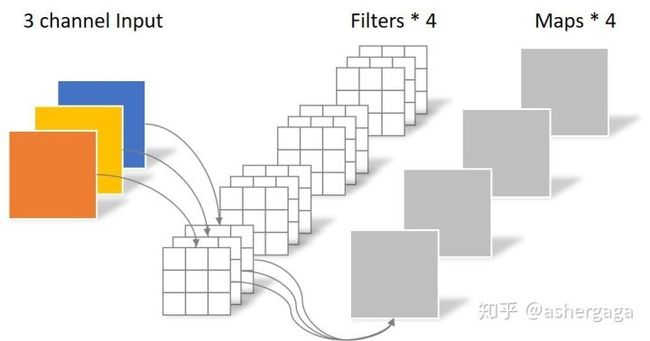
卷积层共4个Filter,每个Filter包含了3个Kernel,每个Kernel的大小为3×3。因此卷积层的参数数量可以用如下公式来计算:N_std = 4 × 3 × 3 × 3 = 108。
Depthwise convolution(逐通道卷积):它和标准卷积不同,对于标准卷积其卷积核是用在所有的输入通道上(input channels),而depthwise convolution针对每个输入通道采用不同的卷积核,就是说一个卷积核对应一个输入通道,所以说depthwise convolution是depth级别的操作。
Depthwise Convolution的一个卷积核负责一个通道,一个通道只被一个卷积核卷积。
一张5×5像素、三通道彩色输入图片(shape为5×5×3),Depthwise Convolution首先经过第一次卷积运算,DW完全是在二维平面内进行。卷积核的数量与上一层的通道数相同(通道和卷积核一一对应)。所以一个三通道的图像经过运算后生成了3个Feature map(如果有same padding则尺寸与输入层相同为5×5),如下图所示(图源看水印)。

其中一个Filter只包含一个大小为3×3的Kernel,卷积部分的参数个数计算如下:
N_depthwise = 3 × 3 × 3 = 27
pointwise convolution(逐点卷积):它其实就是普通的卷积,只不过其采用1x1的卷积核。Depthwise Convolution完成后的Feature map数量与输入层的通道数相同,无法扩展Feature map。而且这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的feature信息。因此需要Pointwise Convolution来将这些Feature map进行组合生成新的Feature map。
Pointwise Convolution的运算与常规卷积运算非常相似,它的卷积核的尺寸为 1×1×M,M为上一层的通道数。所以这里的卷积运算会将上一步的map在深度方向上进行加权组合,生成新的Feature map。有几个卷积核就有几个输出Feature map。(图源看水印)
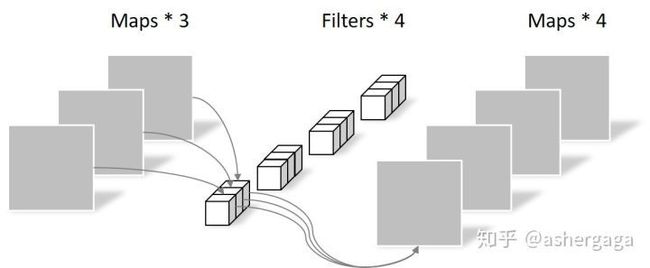
由于采用的是1×1卷积的方式,此步中卷积涉及到的参数个数可以计算为:
N_pointwise = 1 × 1 × 3 × 4 = 12
经过Pointwise Convolution之后,同样输出了4张Feature map,与常规卷积的输出维度相同。
参数对比
回顾一下,常规卷积的参数个数为:
N_std = 4 × 3 × 3 × 3 = 108
Separable Convolution的参数由两部分相加得到:
N_depthwise = 3 × 3 × 3 = 27
N_pointwise = 1 × 1 × 3 × 4 = 12
N_separable = N_depthwise + N_pointwise = 39
相同的输入,同样是得到4张Feature map,Separable Convolution的参数个数是常规卷积的约1/3。因此,在参数量相同的前提下,采用Separable Convolution的神经网络层数可以做的更深。
计算量对比:

1.2 MobileNet网络结构
depthwise separable convolution,这是MobileNet的基本组件,但是在真正应用中会加入batchnorm,并使用ReLU激活函数,所以depthwise separable convolution的基本结构如图3所示。

整个的网络结构:

注意:最后一列是input size。
MobileNet网络的计算与参数分布:

MobileNet到底效果如何,这里与GoogleNet和VGG16做了对比,如表3所示。相比VGG16,MobileNet的准确度稍微下降,但是优于GoogleNet。然而,从计算量和参数量上MobileNet具有绝对的优势。

1.3 MobileNet网络结构
前面说的MobileNet的基准模型,但是有时候你需要更小的模型,那么就要对MobileNet瘦身了。

上述提到的“因为主要计算量在后一项"可以看上边 MobileNet网络的计算与参数分布的表格得到。
1.3MobileNet的TensorFlow实现
链接1中给出了主要代码以及完整代码。复制主要代码之后学习:
class MobileNet(object):
def __init__(self, inputs, num_classes=1000, is_training=True,
width_multiplier=1, scope="MobileNet"):
"""
The implement of MobileNet(ref:https://arxiv.org/abs/1704.04861)
:param inputs: 4-D Tensor of [batch_size, height, width, channels]
:param num_classes: number of classes
:param is_training: Boolean, whether or not the model is training
:param width_multiplier: float, controls the size of model
:param scope: Optional scope for variables
"""
self.inputs = inputs
self.num_classes = num_classes
self.is_training = is_training
self.width_multiplier = width_multiplier
# construct model
with tf.variable_scope(scope):
# conv1
net = conv2d(inputs, "conv_1", round(32 * width_multiplier), filter_size=3,
strides=2) # ->[N, 112, 112, 32]
net = tf.nn.relu(bacthnorm(net, "conv_1/bn", is_training=self.is_training))
net = self._depthwise_separable_conv2d(net, 64, self.width_multiplier,
"ds_conv_2") # ->[N, 112, 112, 64]
net = self._depthwise_separable_conv2d(net, 128, self.width_multiplier,
"ds_conv_3", downsample=True) # ->[N, 56, 56, 128]
net = self._depthwise_separable_conv2d(net, 128, self.width_multiplier,
"ds_conv_4") # ->[N, 56, 56, 128]
net = self._depthwise_separable_conv2d(net, 256, self.width_multiplier,
"ds_conv_5", downsample=True) # ->[N, 28, 28, 256]
net = self._depthwise_separable_conv2d(net, 256, self.width_multiplier,
"ds_conv_6") # ->[N, 28, 28, 256]
net = self._depthwise_separable_conv2d(net, 512, self.width_multiplier,
"ds_conv_7", downsample=True) # ->[N, 14, 14, 512]
net = self._depthwise_separable_conv2d(net, 512, self.width_multiplier,
"ds_conv_8") # ->[N, 14, 14, 512]
net = self._depthwise_separable_conv2d(net, 512, self.width_multiplier,
"ds_conv_9") # ->[N, 14, 14, 512]
net = self._depthwise_separable_conv2d(net, 512, self.width_multiplier,
"ds_conv_10") # ->[N, 14, 14, 512]
net = self._depthwise_separable_conv2d(net, 512, self.width_multiplier,
"ds_conv_11") # ->[N, 14, 14, 512]
net = self._depthwise_separable_conv2d(net, 512, self.width_multiplier,
"ds_conv_12") # ->[N, 14, 14, 512]
net = self._depthwise_separable_conv2d(net, 1024, self.width_multiplier,
"ds_conv_13", downsample=True) # ->[N, 7, 7, 1024]
net = self._depthwise_separable_conv2d(net, 1024, self.width_multiplier,
"ds_conv_14") # ->[N, 7, 7, 1024]
net = avg_pool(net, 7, "avg_pool_15")
net = tf.squeeze(net, [1, 2], name="SpatialSqueeze")
self.logits = fc(net, self.num_classes, "fc_16")
self.predictions = tf.nn.softmax(self.logits)
def _depthwise_separable_conv2d(self, inputs, num_filters, width_multiplier,
scope, downsample=False):
"""depthwise separable convolution 2D function"""
num_filters = round(num_filters * width_multiplier)
strides = 2 if downsample else 1
with tf.variable_scope(scope):
# depthwise conv2d
dw_conv = depthwise_conv2d(inputs, "depthwise_conv", strides=strides)
# batchnorm
bn = bacthnorm(dw_conv, "dw_bn", is_training=self.is_training)
# relu
relu = tf.nn.relu(bn)
# pointwise conv2d (1x1)
pw_conv = conv2d(relu, "pointwise_conv", num_filters)
# bn
bn = bacthnorm(pw_conv, "pw_bn", is_training=self.is_training)
return tf.nn.relu(bn)二、MobIleNetV2
论文地址:http://openaccess.thecvf.com/content_cvpr_2018/papers/Sandler_MobileNetV2_Inverted_Residuals_CVPR_2018_paper.pdf
参考资料:1. MobileNet V2 论文初读 - 知乎
2.MobileNet系列网络详细解读_Mounsey的博客-CSDN博客_moblienet
3.详解MobileNetV2 - 知乎
V2的新想法包括Linear Bottleneck 和 Inverted Residuals Blocks。发表于2018年。
2.1 对比 MobileNet V1 与 V2 的微结构

相同点:都采用 Depth-wise (DW) 卷积搭配 Point-wise (PW) 卷积的方式来提特征。
不同点:Linear Bottleneck

那什么是 Inverted Residuals Blocks呢?
MobileNet V2 借鉴 ResNet,都采用了 1X1->3X3->1x1 的模式,MobileNet V2 借鉴 ResNet,同样使用 Shortcut 将输出与输入相加(未在下图中画出)
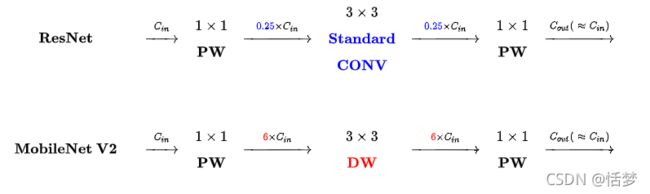
ResNet与MobileNet V2的不同点:Inverted Residual Block
- ResNet 使用 标准卷积 提特征,MobileNet 始终使用 DW卷积 提特征。
- ResNet 先降维 (0.25倍)、卷积、再升维,而 MobileNet V2 则是 先升维 (6倍)、卷积、再降维。直观的形象上来看,ResNet 的微结构是沙漏形,而 MobileNet V2 则是纺锤形,刚好相反。因此论文作者将 MobileNet V2 的结构称为 Inverted Residual Block。这么做也是因为使用DW卷积而作的适配,希望特征提取能够在高维进行。
2.2 MobileNet V2 的网络结构

t为扩张系数、c为输出通道数、n为该层重复的次数、s为步长。
基本参数汇总对比:

三、MoblieNetV3
论文地址:https://arxiv.org/pdf/1905.02244v5.pdf
代码实现:tensorflow:GitHub - Bisonai/mobilenetv3-tensorflow: Unofficial implementation of MobileNetV3 architecture described in paper Searching for MobileNetV3.
Pytorch:GitHub - xiaolai-sqlai/mobilenetv3: mobilenetv3 with pytorch,provide pre-train model
参考资料:1.重磅!MobileNetV3 来了! | 机器之心
2.MobileNet系列网络详细解读_Mounsey的博客-CSDN博客_moblienet
发表于2019年,MobileNetV3 没有引入新的 Block,题目中Searching已经道尽该网络的设计哲学:神经架构搜索。MobileNetV3是神经架构搜索得到的模型。
3.1 V3的特点
其内部使用的模块继承自:
1. MobileNetV1 模型引入的深度可分离卷积(depthwise separable convolutions);
2. MobileNetV2 模型引入的具有线性瓶颈的倒残差结构(the inverted residual with linear bottleneck);
3. MobileNetV3 模型引入的基于squeeze and excitation结构的轻量级注意力模型。
这些被证明行之有效的用于移动端网络设计的模块是搭建MobileNetV3的积木。
1、利用NAS(神经结构搜索)来搜索网络的配置和参数
在网络结构搜索中,作者结合两种技术:资源受限的NAS(platform-aware NAS)与NetAdapt,前者用于在计算和参数量受限的前提下搜索网络的各个模块,所以称之为模块级的搜索(Block-wise Search) ,后者用于对各个模块确定之后网络层的微调,主要是确定每层的filter数量(Layer-wise Search)。
2、作者对耗费资源最多的输入输出层做了改进

3、由于嵌入式设备计算sigmoid是会耗费相当大的计算资源的,因此作者提出了h-switch作为激活函数。且随着网络的加深,非线性激活函数的成本也会随之减少。所以,只有在较深的层使用h-switch才能获得更大的优势。

4、引入SE模块
Squeeze-and-Excitation Networks,SE模块是一种轻量级的通道注意力模块,能够让网络模型对特征进行校准的机制,使得有效的权重大,无效或效果小的权重小的效果。
MobileNetV3的SE模块被运用在线性瓶颈结构最后一层上,代替V2中最后的逐点卷积,改为先进行SE操作再逐点卷积。这样保持了网络结构每层的输入和输出,仅在中间做处理。
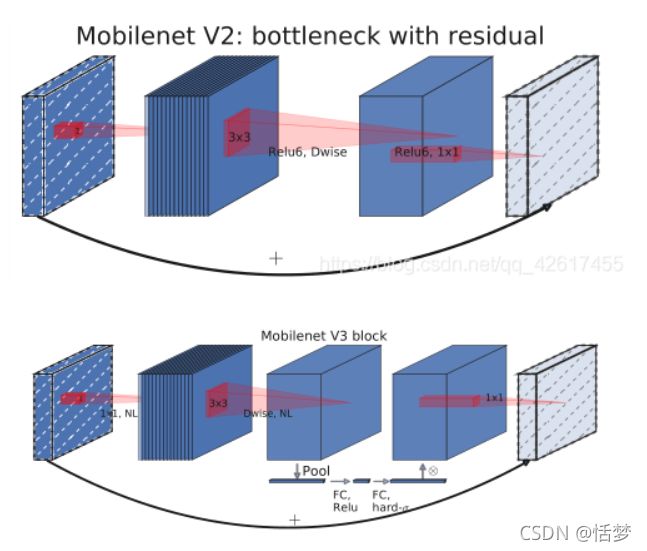
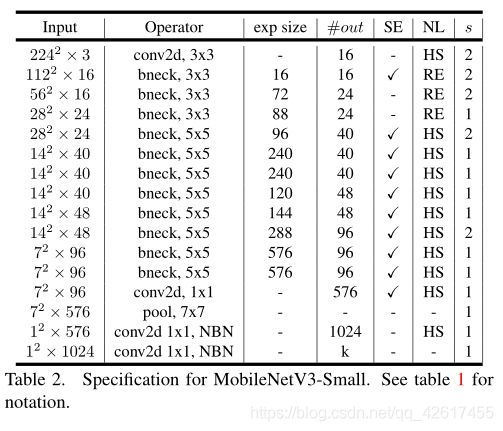
3.2 网络结构
MobileNetV3分为Large和Small两个版本,Large版本适用于计算和存储性能较高的平台,Small版本适用于硬件性能较低的平台。
Large版本共有15个bottleneck层,一个标准卷积层,三个逐点卷积层。
Small版本共有12个bottleneck层,一个标准卷积层,两个逐点卷积层。

上述内容,如有不妥之处,还望指出!