LeNet-5源代码(详注)、mnist_data及论文
LeNet-5是论文Gradient-Based Learning Applied to Document Recognition(IEEE-1998)提出的一种用于手写体字符识别的卷积神经网络模型。
- 源代码
'''利用tensorflow实现的卷积神经网络来进行MNIST手写数字图像的分类。'''
import numpy as np
import tensorflow as tf
#下载mnist数据集,并从mnist_data目录中读取数据
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('mnist_data',one_hot=True)
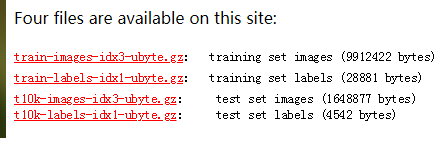
#(1)“mnist_data” 是和当前文件相同目录下的一个文件夹。从https://yann.lecun.com/exdb/mnist/ 下载4个文件,放到目录MNIST_data下。
#(2)MNIST数据集每个样本都是一张28*28像素的灰度手写数字图片。
#(3)one_hot值被设为true。在分类问题的数据集标注时,如何不采用独热编码的方式, 类别通常就是一个符号,比如9。
#但如果采用独热编码的方式,则每类表示为一个列表list,共计有10个数值,但只有一个为1,其余均为0。如,“9”的独热编码可为[00000 00001].
#定义输入数据x和输出y的形状。函数tf.placeholder的目的是定义输入,可以理解为采用占位符进行占位。
#None位置的参数被用于表示样本的个数,因为样本数此时无法确定,故设为None。每个输入样本的特征数目为28*28。
input_x = tf.placeholder(tf.float32,[None,28*28])/255 #因为每个像素的取值范围是 0~255
output_y = tf.placeholder(tf.int32,[None,10]) #10表示10个类别
#输入层的输入数据input_x被reshape成四维数据,其中第一维的数据代表了图片数量
input_x_images = tf.reshape(input_x,[-1,28,28,1])
test_x = mnist.test.images[:3000] #读取测试集图片的特征,读取3000个图片
test_y = mnist.test.labels[:3000] #读取测试集图片的标签。即3000个图片对应的标签
#定义卷积神经网络CNN的结构
#定义第一层——conv1的结构。tf.layers.conv2d函数表示要使用2维的卷积层
conv1 = tf.layers.conv2d(
inputs=input_x_images,#输入是input_x_images 。
filters=32,#滤波器的数量是32。
kernel_size=[5,5],#卷积核的尺寸是5*5。
strides=1,
padding='same',#padding参数的作用是决定在进行卷积时,是否要对输入的图像矩阵边缘补0。
activation=tf.nn.relu#最后设置activation,即激活函数设为relu。
)
print(conv1) #输出的shape为[28,28,32]
#利用tf.layers.max_pooling2d 函数进行最大池操作,输入就是conv1,这里pool_size设为2*2,步长为2。
pool1 = tf.layers.max_pooling2d(
inputs=conv1,
pool_size=[2,2],
strides=2
)
print(pool1) #输出的形状为[14,14,32],由于每个图像变为了14*14的,因此图片的尺寸明显变小了
#定义第二次卷积的结构。同样使用tf.layers.conv2d函数。输入是刚才的最大池处理后的结果。使用64个卷积核,每核大小为5*5. 其它的设置和conv1相同。
conv2 = tf.layers.conv2d(
inputs=pool1,
filters=64,
kernel_size=[5,5],
strides=1,
padding='same',
activation=tf.nn.relu
)
print(conv2) #由于padding设为了'same',所以输出为[14,14,64]。所以这一层卷积处理后,特征图的数目增加了。但每个图的尺寸仍然是14*14
#利用tf.layers.max_pooling2d 函数进行再一次的最大池操作。
pool2 = tf.layers.max_pooling2d(
inputs=conv2,
pool_size=[2,2],
strides=2
)
print(pool2) #输出为[7,7,64],尺寸变为7*7
#刚才进行的是两次卷积以及降采样。得到的特征图有64个,每个大小为7*7=49。下面对每个图进行打平处理,64*49=3136. 目的是为FC做准备,以便得到softmax数值】
flat = tf.reshape(pool2,[-1,7*7*64])
#下面接一个全连接层,使用的是tf.layers.dense函数,其输入为打平的结果flat。units: 输出的大小(维数),激活函数设为relu
dense=tf.layers.dense(
inputs=flat,
units=1024,
activation=tf.nn.relu
)
print(dense) #输出的特征图的像素个数应该是1024
#利用tf.layers.dropout函数做了一次dropout操作。丢弃率rate=0.5,即一半的神经元丢弃不工作。输入就是dense
dropout = tf.layers.dropout(
inputs=dense,
rate=0.5
)
print(dropout) #输出应该仍为1024个数值
#使用tf.layers.dense定义输出层,输入是刚才的dropout的结果。这个层是一个简单的全连接层,没有使用激活函数,输出10个数值。
outputs = tf.layers.dense(
inputs=dropout,
units=10
)
print(outputs) #输出为10个数值
#到现在为止,完成了一次正向传播。得到的outputs就是预测的结果。】
#计算交叉熵损失,利用的是softmax_cross_entropy函数。其中的output_y表示真实的分类结果。而outputs则表示预测的结果
loss = tf.losses.softmax_cross_entropy(onehot_labels=output_y,logits=outputs)
print(loss)#打印loss的维度
#定义训练操作,采用梯度下降的优化方法,设置学习率为0.001
train_op = tf.train.GradientDescentOptimizer(0.001).minimize(loss)
#定义模型的性能评价指标为准确率,具体是使用tf.metrics.accuracy函数来实现的。labels是正确的标签,predictions则是预测的结果
accuracy_op = tf.metrics.accuracy(
labels=tf.argmax(output_y,axis=1), #返回张量维度上最大值的索引
predictions=tf.argmax(outputs,axis=1)#返回张量维度上最大值的索引
)
print(accuracy_op)#打印这个张量
#以上定义了tensorflow的图,下面就要开始执行任务了。首先要初始化所有变量
sess=tf.Session()
init=tf.group(tf.global_variables_initializer(),tf.local_variables_initializer())
sess.run(init)
#只训练了2000个批次
for i in range(2000):
#每次迭代只选取 50个图片及其标签
batch = mnist.train.next_batch(50)
#把batch中的这50幅图像的特征数据batch[0]及其标签batch[1] 送入模型,进行训练操作,并得到其训练损失
train_loss, train_op_=sess.run([loss,train_op],{input_x:batch[0],output_y:batch[1]})
#每迭代100次就输出一下训练的损失函数取值和在测试数据集(只选了3000个图片)上的准确率。
if i%100==0:
#计算在测试集上的准确率
test_accuracy=sess.run(accuracy_op,{input_x:test_x,output_y:test_y})
print("Step=%d, Train loss=%.4f,Test accuracy=%.2f"%(i,train_loss,test_accuracy[0]))#输出当前步数,训练损失,准确率
#模型已经训练完毕。下面选取30幅图像,看下模型预测的效果。test_output是预测的结果
test_output=sess.run(outputs,{input_x:test_x[:30]})
#由于test_output实际上是一个softmax的结果,所以下面用np.argmax函数求每一幅图像预测的分类值
inferenced_y=np.argmax(test_output,1)
print(inferenced_y,'Inferenced numbers')
print(np.argmax(test_y[:30],1),'Real numbers')
#关闭session
sess.close()
执行效果:

-
论文Gradient-Based Learning Applied to Document Recognition(IEEE-1998) 链接:https://cuijiahua.com/wp-content/themes/begin/down.php?id=2388

-
mnist_data链接:http://yann.lecun.com/exdb/mnist/