FCN论文解读:FCN-Fully Convolutional Networks for Semantic Segmentation
FCN原文作为语义分割领域的开山之作,对其进行研究和阅读几乎是入门语义分割领域的基础,这篇博客整理了自己阅读该论文的一些心得感悟和收获。
首先是FCN原文中提到的Dense prediction问题。
Dense prediction问题:
一类问题,目标是标注出图像中每个像素点的对象类别(label),要求不但给出具体目标的位置,还要描绘物体的边界,具体有图像分割、语义分割、边缘检测等方向。
紧接着是语义分割中的IOU指标(在FCN中也被称为IU指标)。
IOU指标:
IOU即Intersection over union,交并比(有时也写作IU),是计算机视觉领域常用的指标,用来衡量算法的性能。语义分割领域,一般将IOU作为衡量算法的首要指标。
要理解IOU,首先需要了解四个概念,TP(ture positive)、FP(false positive)、TN(true negative)、FN(false negative),其中positive即有标签的部分,negative指无标签部分(可以简单理解为下图中的背景部分),T&F表示预测值真实与否。具体的如下图所示,白色斜线部分为TN,红色斜线部分为FN,蓝色斜线部分为FP,黄色荧光部分为TP。

IOU=TP/(TP+FP+FN),即预测值与真实值的交并比。
mIOU即IOU指标的平均值。
然后是对于原文的核心之一,FCN网络的理解。
核心思想:用于分类的神经网络由卷积层、池化层和最后连接的全连接层组成,经过最后的全连接层以后,二维的图像矩阵信息被映射为具体的类别进行输出,得到分类标签;而对于dense prediction问题,我们需要的不是具体的标签,而是一个二维的分割图,FCN(Full Conventional Network)方法丢弃掉全连接层,并将其换成卷积层,就能输出一张heatmap,这就是原始的分割图像了。
其原理如下图所示:
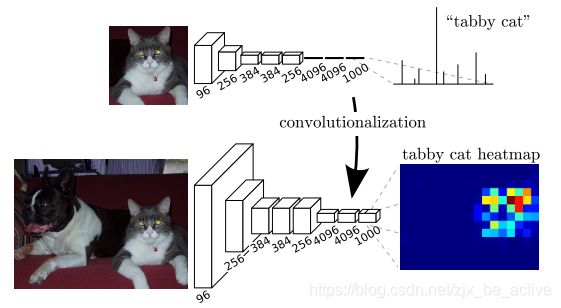
Transforming fully connected layers into convolution layers enables a classification net to output a heatmap
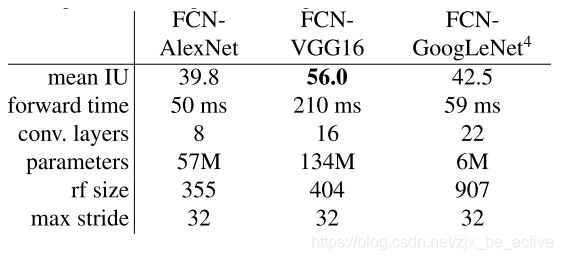
本文中,作者基于几种常见的卷积神经网络进行了改良,并对其性能进行了对比,最后采取了基于VGG16的FCN网络:
由于经过多次卷积之后图像大小会发生改变,需要通过上采样对其进行尺寸的恢复,所以紧接着进入原文的第二个核心,上采样。
Up-sampling(上采样):
在语义分割问题中,经过卷积操作之后,图像尺寸会大幅减小,但语义分割问题需要对图像的每一个像素进行语义标注,所以需要将图像还原成原图像大小,所以需要进行上采样的过程进行图像的扩大。常见的上采样方法有插值算法等。
插值算法:
进行上采样时,最直观最常用的方法就是插值算法,通过像素点的信息对其相邻位置进行填充。原文中提到了常用的双线性插值算法。
双线性插值:线性插值的二维拓展,线性插值类似于在直线上通过比例关系确定某点的坐标。一图理解双线性插值:
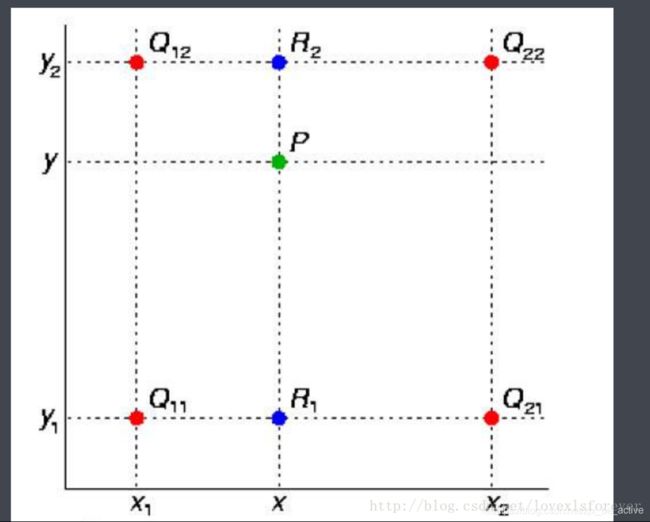
图中Q11、Q12、Q21、Q22为已知点,P为最终得到的插值点
原文最终采用了经典的Deconvolution的方法进行上采样。
Deconvolution(原文称其为backwards convolution,可译为逆卷积、转置卷积):
用于进行up-sampling过程,相比于其他采样方法,deconvolution具有参数可学习的特点。
接下来对其原理进行分析。首先,对于常规的卷积过程,如下图所示:
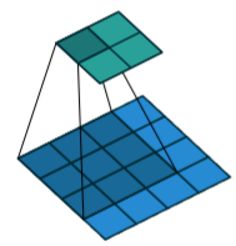
我们可以看到,经过卷积过程,图像变小了(感受野增大)。
那么,在deconvolution过程中,如何对图像进行放大呢?
答案就是zero padding(零填充),如下图所示:
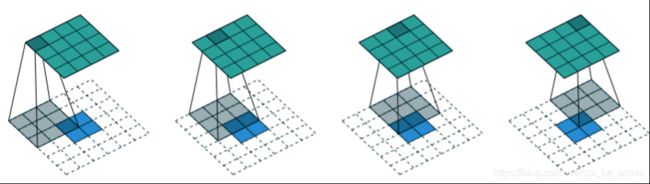
图中空白部分进行zero padding。
进一步的,如果考虑图像中的stride,则对填充方式进行调整(核心仍然是维持图upsampling后图像的大小保持不变),如下图所示:
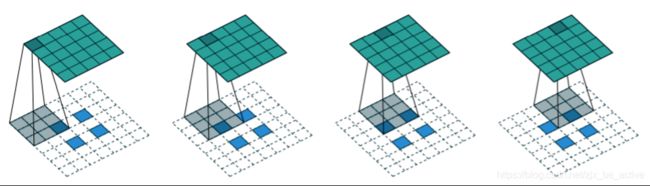
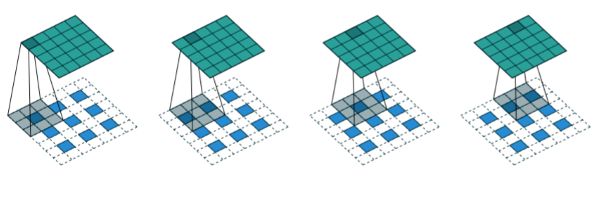
deconvolution中,卷积核是可以通过学习得出的,所以相比于插值算法等参数不可学习的方法,有更强的适用性(当然学习过程也会带来更大的运算量)
直接采用卷积的结果进行上采样的话,得出的feature map往往不够精细,所以原文采用了一种跳级结构来解决这一问题,这是原文的第三个核心。
跳跃结构(Skip Architecture,deep jet):
如果直接用全卷积后的层进行上采样的话,得到的结果往往不够精细,所以本文中采取了跳级结构的方法,将fine layers(更靠前的卷积层)和coarse layers(经过上采样的层)相结合,如下图所示;采用这种方法,能够在保留全局特征的前提下,尽可能使得图像的划分更为精细(当然,这种方法也会带来很高的运算量,采用的fine layers越靠前,运算量越大)。
作者通过实验对比了三种结构(FCN-32s、FCN-16s、FCN-8s)的性能,从-32s到-16s,性能提升明显,达到了62.4的mIOU;而从-16s到-8s,性能只提升了0.3个百分点,但平滑度和细节(smoothness and detail)略有所改善。再往前推得到类似-4s的结构的话,得到的性能提升非常有限,但计算量会大幅度增加,所以最后作者采用了FCN-8s作为最终结构。
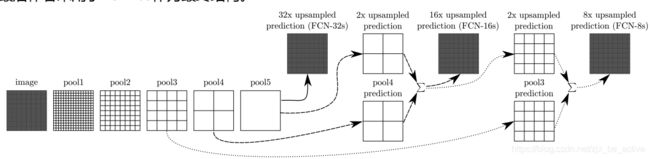
跳级结构的图示

三种不同结构的结果比较