半监督3D医学图像分割(一):Mean Teacher
Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results
研究背景
- 随着人工智能技术在医疗领域的应用越来越广泛,开发自动、准确和可靠的医学图像处理算法对于计算机辅助诊断和手术导航系统至关重要。
- 传统的图像处理算法需要手动设计特征提取算子,深度学习算法基于给定数据和标签进行端到端的训练,并自动提取出对于目标最显著的特征。
- 图像分割是医学图像处理中的重要任务之一,基于深度学习的自动分割方法不需要医生进行手动标注,分割效率高且不会受到主观因素的影响。
- 深度学习归根结底是数据驱动的,模型训练的好坏取决于图像和标签的质量。
- 医学图像需要专业医师标注,特别是3D图像,标注代价昂贵。
- 有标签的数据集有限,而无标签的数据集有很多。
- 在医学图像处理领域,自监督学习、半监督学习以及无监督学习应用前景广阔。
自监督学习先使用大量无标签的数据集,通过对比学习和图像重建等方式构建损失函数,进行预训练,然后在特定任务上使用有标签的数据集进行微调。
半监督学习则是将少量有标注的数据和大量无标注的数据直接输入到网络中,构建一致性损失或者多任务学习,达到比单独用有标注数据集更好的结果。
网络结构
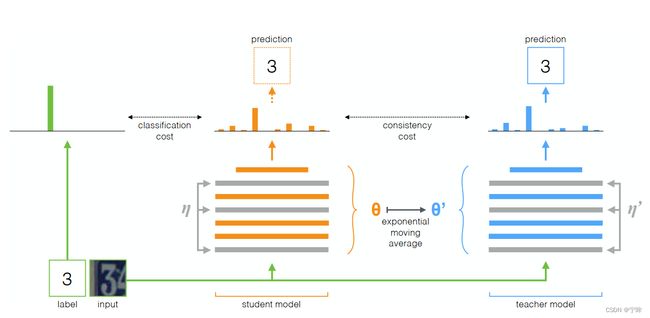
下面是我参考Mean Teacher论文里的方法,结合图像分割画的网络图。

网络分为两部分,学生网络和教师网络,教师网络的参数重是冻结的,通过指数滑动平均从学生网络迁移更新。
同时输入有标签的图像和无标签的图像,同一张图像加上独立的随机噪声分别输入到学生网络和教师网络中。
损失由两部分组成,有标签的数据做分割损失,无标签的图像做一致性损失(有标签的也可以做一致性损失)。
个人认为,Mean Teacher网络的训练是一个求同存异的过程,输入的图像略有差异,网络参数略有差异,我们假设网络训练好后完全收敛,此时学生网络和教师网络的参数应该是非常接近的,也具备良好的去噪能力,那么一致性损失就会很小;反之,如果网络没有收敛,一致性损失也不会收敛。
指数滑动平均
Exponential moving average (EMA ):
θ t ′ = α θ t − 1 ′ + ( 1 − α ) θ t \theta_t' = \alpha \theta'_{t-1} + (1-\alpha)\theta_t θt′=αθt−1′+(1−α)θt
- 每个iteration更新一次参数,θ表示学生网络的参数,θ‘表示教师网络的参数
- t表示时刻,α表示动量,若α=0.9,则教师网络每次更新,保留自身90%的参数不变,10%从学生网络迁移
损失函数
θ ∗ = a r g m i n θ ∏ i = 1 N L s e g ( f ( x i ; θ ) , y i ) + λ ∏ i = N + 1 N + M L c o n ( f ( x i ; θ , η s ) , f ( x i ; θ ′ , η t ) ) \theta^* = argmin_{\theta} \prod_{i=1}^{N}L_{seg}(f(x_i;\theta),y_i) + \lambda\prod_{i=N+1}^{N+M}L_{con}(f(x_i;\theta,\eta^s),f(x_i;\theta',\eta^t)) θ∗=argminθi=1∏NLseg(f(xi;θ),yi)+λi=N+1∏N+MLcon(f(xi;θ,ηs),f(xi;θ′,ηt))
- θ和θ‘分别表示学生网络和教师网络的参数,η是随机噪声,y是标签
- N例有标签的数据,M例无标签的数据,i是数据索引
- Lseg 是dice loss或者交叉熵等常用的分割损失;Lcon是一致性损失,一般用MSE
- 每个 batch size 包含有标签的数据和无标签的数据,无标签的部分用来做一致性损失
代码解读
LASeg: 2018 Left Atrium Segmentation (MRI) (github.com)
运行:
python train_mean_teacher.py
对比只使用有标签部分的数据:
python train_sup.py
使用的数据集仍然是Left Atrium (LA) MR dataset ,是在上一篇博文LAHeart2018左心房分割实战的基础上实现的,参考https://github.com/yulequan/UA-MT
1.TwoStreamBatchSampler
肯定很多人想问,如何从dataset中采样,才能在每个 batch size 中包含有标签的数据和无标签的数据
import itertools
import numpy as np
from torch.utils.data.sampler import Sampler
class TwoStreamBatchSampler(Sampler):
"""Iterate two sets of indices
An 'epoch' is one iteration through the primary indices.
During the epoch, the secondary indices are iterated through
as many times as needed.
"""
def __init__(self, primary_indices, secondary_indices, batch_size, secondary_batch_size):
# 有标签的索引
self.primary_indices = primary_indices
# 无标签的索引
self.secondary_indices = secondary_indices
self.secondary_batch_size = secondary_batch_size
self.primary_batch_size = batch_size - secondary_batch_size
assert len(self.primary_indices) >= self.primary_batch_size > 0
assert len(self.secondary_indices) >= self.secondary_batch_size > 0
def __iter__(self):
# 随机打乱索引顺序
primary_iter = iterate_once(self.primary_indices)
secondary_iter = iterate_eternally(self.secondary_indices)
return (
primary_batch + secondary_batch
for (primary_batch, secondary_batch)
in zip(grouper(primary_iter, self.primary_batch_size),
grouper(secondary_iter, self.secondary_batch_size))
)
def __len__(self):
return len(self.primary_indices) // self.primary_batch_size
def iterate_once(iterable):
# print('shuffle labeled_idxs')
return np.random.permutation(iterable)
def iterate_eternally(indices):
# print('shuffle unlabeled_idxs')
def infinite_shuffles():
while True:
yield np.random.permutation(indices)
return itertools.chain.from_iterable(infinite_shuffles())
def grouper(iterable, n):
"Collect data into fixed-length chunks or blocks"
# grouper('ABCDEFG', 3) --> ABC DEF"
args = [iter(iterable)] * n
return zip(*args)
if __name__ == '__main__':
labeled_idxs = list(range(12))
unlabeled_idxs = list(range(12,60))
batch_sampler = TwoStreamBatchSampler(labeled_idxs, unlabeled_idxs, 4, 2)
for _ in range(2):
i = 0
for x in batch_sampler:
i += 1
print('%02d' % i, '\t', x)
- dataset中的每个数据都有对应的索引,这里将有标签数据的索引和无标签数据的索引分开,构建了一个双流采样器,分别从两个索引列表中采样
- 例如,上面代码中有标签的索引是0 – 11,无标签的索引是12 – 59。遍历采样2次得到的结果如下:
shuffle labeled_idxs
shuffle unlabeled_idxs
01 (2, 7, 46, 12)
02 (9, 3, 25, 50)
03 (8, 0, 15, 49)
04 (6, 11, 14, 41)
05 (1, 10, 37, 19)
06 (5, 4, 34, 35)
shuffle labeled_idxs
shuffle unlabeled_idxs
01 (0, 1, 22, 17)
02 (10, 7, 55, 19)
03 (6, 11, 53, 21)
04 (2, 4, 49, 27)
05 (3, 8, 41, 36)
06 (9, 5, 48, 44)
- 每个epoch打乱一次索引列表,相当于的dataset中的
shuffle=True
2.随机噪声
代码只在教师网络的输入加了随机噪声,学生网络的输入没有加噪声
noise = torch.clamp(torch.randn_like(unlabeled_volume_batch) * 0.1, -0.2, 0.2)
其实学生网络和教师网络分别加上随机噪声,跟只给一边网络加噪声的效果是差不多的,都是为了制造一点差异性。
3.指数滑动平均(EMA)
student network 和 teacher network 结构相同,teacher network的参数冻结,不参与反向传播
def create_model(ema=False):
# Network definition
net = VNet(n_channels=1, n_classes=num_classes, normalization='batchnorm', has_dropout=True)
model = net.cuda()
if ema:
for param in model.parameters():
param.detach_() # 切断反向传播
return model
model = create_model()
ema_model = create_model(ema=True)
权重迁移
θ t ′ = α θ t − 1 ′ + ( 1 − α ) θ t \theta_t' = \alpha \theta'_{t-1} + (1-\alpha)\theta_t θt′=αθt−1′+(1−α)θt
def update_ema_variables(model, ema_model, alpha, global_step):
# Use the true average until the exponential average is more correct
alpha = min(1 - 1 / (global_step + 1), alpha)
for ema_param, param in zip(ema_model.parameters(), model.parameters()):
ema_param.data.mul_(alpha).add_(1 - alpha, param.data)
- global_step 的作用是让teacher network的参数,在前期更新的快一点
- 每个batch size,每次反向传播,teacher network的参数都更新一次
4.损失函数
分割损失
L t o t a l = L d i c e + L C E L_{total} = L_{dice} + L_{CE} Ltotal=Ldice+LCE
loss_seg = F.cross_entropy(outputs[:labeled_bs], label_batch[:labeled_bs])
outputs_soft = F.softmax(outputs, dim=1)
loss_seg_dice = losses.dice_loss(outputs_soft[:labeled_bs, 1, :, :, :], label_batch[:labeled_bs] == 1)
supervised_loss = 0.5 * (loss_seg + loss_seg_dice)
一致性损失
L c o n = ∣ ∣ f ( x i ; θ , η s ) , f ( x i ; θ ′ , η t ) ∣ ∣ 2 L_{con} = ||f(x_i;\theta,\eta^s),f(x_i;\theta',\eta^t)||^2 Lcon=∣∣f(xi;θ,ηs),f(xi;θ′,ηt)∣∣2
损失权重
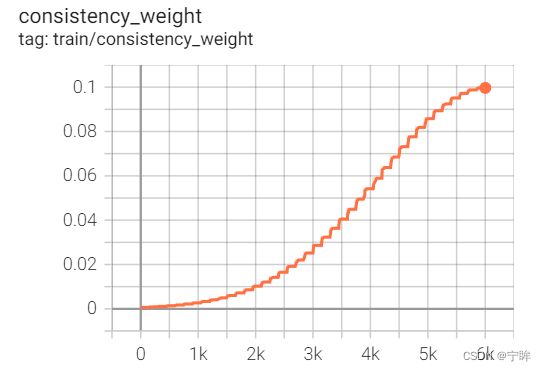
λ ( t ) = ω m a x ⋅ e − 5 ( 1 − t t m a x ) 2 \lambda(t) = \omega_{max} \cdot e^{-5(1-\frac{t}{t_{max}})^2} λ(t)=ωmax⋅e−5(1−tmaxt)2
# 每150个iteration更新一次损失权重
consistency_weight = get_current_consistency_weight(iter_num // 150)
consistency_dist = consistency_criterion(outputs[labeled_bs:], ema_output)
consistency_loss = consistency_weight * consistency_dist
一致性损失的权重随着训练周期逐渐增加,防止网络训练前期被无意义的一致性目标影响。
def get_current_consistency_weight(epoch):
# Consistency ramp-up from https://arxiv.org/abs/1610.02242
return args.consistency * ramps.sigmoid_rampup(epoch, args.consistency_rampup)
ramps.sigmoid_rampup
def sigmoid_rampup(current, rampup_length):
"""Exponential rampup from https://arxiv.org/abs/1610.02242"""
if rampup_length == 0:
return 1.0
else:
current = np.clip(current, 0.0, rampup_length)
phase = 1.0 - current / rampup_length
return float(np.exp(-5.0 * phase * phase))
完整训练代码:
import os
import sys
from tqdm import tqdm
from tensorboardX import SummaryWriter
import argparse
import logging
import time
import random
import torch
import torch.optim as optim
from torchvision import transforms
import torch.nn.functional as F
import torch.backends.cudnn as cudnn
from torch.utils.data import DataLoader
from networks.vnet import VNet
from utils import ramps, losses
from dataloaders.la_heart import *
parser = argparse.ArgumentParser()
parser.add_argument('--dataset_name', type=str, default='LA', help='dataset_name')
parser.add_argument('--root_path', type=str, default='/***/data_set/LASet/data',
help='Name of Experiment')
parser.add_argument('--exp', type=str, default='vnet', help='model_name')
parser.add_argument('--model', type=str, default='MT', help='model_name')
parser.add_argument('--max_iterations', type=int, default=6000, help='maximum epoch number to train')
parser.add_argument('--batch_size', type=int, default=4, help='batch_size per gpu')
parser.add_argument('--labeled_bs', type=int, default=2, help='labeled_batch_size per gpu')
parser.add_argument('--labelnum', type=int, default=25, help='trained samples')
parser.add_argument('--max_samples', type=int, default=123, help='all samples')
parser.add_argument('--base_lr', type=float, default=0.01, help='maximum epoch number to train')
parser.add_argument('--deterministic', type=int, default=1, help='whether use deterministic training')
parser.add_argument('--seed', type=int, default=1337, help='random seed')
parser.add_argument('--gpu', type=str, default='1', help='GPU to use')
### costs
parser.add_argument('--ema_decay', type=float, default=0.99, help='ema_decay')
parser.add_argument('--consistency_type', type=str, default="mse", help='consistency_type')
parser.add_argument('--consistency', type=float, default=0.1, help='consistency')
parser.add_argument('--consistency_rampup', type=float, default=40.0, help='consistency_rampup')
args = parser.parse_args()
patch_size = (112, 112, 80)
snapshot_path = "model/{}_{}_{}_labeled/{}".format(args.dataset_name, args.exp, args.labelnum, args.model)
os.environ['CUDA_VISIBLE_DEVICES'] = args.gpu
batch_size = args.batch_size * len(args.gpu.split(','))
max_iterations = args.max_iterations
base_lr = args.base_lr
labeled_bs = args.labeled_bs
if args.deterministic:
cudnn.benchmark = False
cudnn.deterministic = True
random.seed(args.seed)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
torch.cuda.manual_seed(args.seed)
num_classes = 2
patch_size = (112, 112, 80)
def cal_dice(output, target, eps=1e-3):
output = torch.argmax(output,dim=1)
inter = torch.sum(output * target) + eps
union = torch.sum(output) + torch.sum(target) + eps * 2
dice = 2 * inter / union
return dice
def get_current_consistency_weight(epoch):
# Consistency ramp-up from https://arxiv.org/abs/1610.02242
return args.consistency * ramps.sigmoid_rampup(epoch, args.consistency_rampup)
def update_ema_variables(model, ema_model, alpha, global_step):
# Use the true average until the exponential average is more correct
alpha = min(1 - 1 / (global_step + 1), alpha)
for ema_param, param in zip(ema_model.parameters(), model.parameters()):
ema_param.data.mul_(alpha).add_(1 - alpha, param.data)
if __name__ == "__main__":
# make logger file
if not os.path.exists(snapshot_path):
os.makedirs(snapshot_path)
logging.basicConfig(filename=snapshot_path + "/log.txt", level=logging.INFO,
format='[%(asctime)s.%(msecs)03d] %(message)s', datefmt='%H:%M:%S')
logging.getLogger().addHandler(logging.StreamHandler(sys.stdout))
logging.info(str(args))
def create_model(ema=False):
# Network definition
net = VNet(n_channels=1, n_classes=num_classes, normalization='batchnorm', has_dropout=True)
model = net.cuda()
if ema:
for param in model.parameters():
param.detach_()
return model
model = create_model()
ema_model = create_model(ema=True)
db_train = LAHeart(base_dir=args.root_path,
split='train',
transform=transforms.Compose([
RandomRotFlip(),
RandomCrop(patch_size),
ToTensor(),
]))
db_test = LAHeart(base_dir=args.root_path,
split='test',
transform=transforms.Compose([
CenterCrop(patch_size),
ToTensor()
]))
labeled_idxs = list(range(args.labelnum))
unlabeled_idxs = list(range(args.labelnum, args.max_samples))
batch_sampler = TwoStreamBatchSampler(labeled_idxs, unlabeled_idxs, batch_size, batch_size - labeled_bs)
def worker_init_fn(worker_id):
random.seed(args.seed + worker_id)
train_loader = DataLoader(db_train, batch_sampler=batch_sampler, num_workers=4, pin_memory=True,
worker_init_fn=worker_init_fn)
test_loader = DataLoader(db_test, batch_size=1,shuffle=False, num_workers=4, pin_memory=True)
model.train()
ema_model.train()
optimizer = optim.SGD(model.parameters(), lr=base_lr, momentum=0.9, weight_decay=0.0001)
if args.consistency_type == 'mse':
consistency_criterion = losses.softmax_mse_loss
elif args.consistency_type == 'kl':
consistency_criterion = losses.softmax_kl_loss
else:
assert False, args.consistency_type
writer = SummaryWriter(snapshot_path + '/log')
logging.info("{} itertations per epoch".format(len(train_loader)))
iter_num = 0
best_dice = 0
max_epoch = max_iterations // len(train_loader) + 1
lr_ = base_lr
model.train()
for epoch_num in tqdm(range(max_epoch), ncols=70):
time1 = time.time()
for i_batch, sampled_batch in enumerate(train_loader):
time2 = time.time()
# print('fetch data cost {}'.format(time2-time1))
volume_batch, label_batch = sampled_batch['image'], sampled_batch['label']
volume_batch, label_batch = volume_batch.cuda(), label_batch.cuda()
unlabeled_volume_batch = volume_batch[labeled_bs:]
noise = torch.clamp(torch.randn_like(unlabeled_volume_batch) * 0.1, -0.2, 0.2)
ema_inputs = unlabeled_volume_batch + noise
outputs = model(volume_batch)
with torch.no_grad():
ema_output = ema_model(ema_inputs)
# calculate the loss
loss_seg = F.cross_entropy(outputs[:labeled_bs], label_batch[:labeled_bs])
outputs_soft = F.softmax(outputs, dim=1)
loss_seg_dice = losses.dice_loss(outputs_soft[:labeled_bs, 1, :, :, :], label_batch[:labeled_bs] == 1)
supervised_loss = 0.5 * (loss_seg + loss_seg_dice)
consistency_weight = get_current_consistency_weight(iter_num // 150)
consistency_dist = consistency_criterion(outputs[labeled_bs:], ema_output) # (batch, 2, 112,112,80)
consistency_loss = consistency_weight * consistency_dist
loss = supervised_loss + consistency_loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
update_ema_variables(model, ema_model, args.ema_decay, iter_num)
iter_num = iter_num + 1
writer.add_scalar('lr', lr_, iter_num)
writer.add_scalar('loss/loss', loss, iter_num)
writer.add_scalar('loss/loss_seg', loss_seg, iter_num)
writer.add_scalar('loss/loss_seg_dice', loss_seg_dice, iter_num)
writer.add_scalar('train/consistency_weight', consistency_weight, iter_num)
writer.add_scalar('train/consistency_dist', consistency_dist, iter_num)
logging.info('iteration %d : loss : %f cons_dist: %f, loss_weight: %f' %
(iter_num, loss.item(), consistency_dist.item(), consistency_weight))
if iter_num >= 800 and iter_num % 200 == 0:
model.eval()
with torch.no_grad():
dice_sample = 0
for sampled_batch in test_loader:
img, lbl = sampled_batch['image'].cuda(), sampled_batch['label'].cuda()
outputs = model(img)
dice_once = cal_dice(outputs,lbl)
dice_sample += dice_once
dice_sample = dice_sample / len(test_loader)
print('Average center dice:{:.3f}'.format(dice_sample))
if dice_sample > best_dice:
best_dice = dice_sample
save_mode_path = os.path.join(snapshot_path, 'iter_{}_dice_{}.pth'.format(iter_num, best_dice))
save_best_path = os.path.join(snapshot_path, '{}_best_model.pth'.format(args.model))
torch.save(model.state_dict(), save_mode_path)
torch.save(model.state_dict(), save_best_path)
logging.info("save best model to {}".format(save_mode_path))
writer.add_scalar('Var_dice/Dice', dice_sample, iter_num)
writer.add_scalar('Var_dice/Best_dice', best_dice, iter_num)
model.train()
if iter_num >= max_iterations:
break
time1 = time.time()
if iter_num >= max_iterations:
break
save_mode_path = os.path.join(snapshot_path, 'iter_' + str(max_iterations) + '.pth')
torch.save(model.state_dict(), save_mode_path)
logging.info("save model to {}".format(save_mode_path))
writer.close()
需要注意的是,训练过程中记录的dice并不准确,真实指标需要运行
inference.py中滑动窗口法进行推理。
实验结果
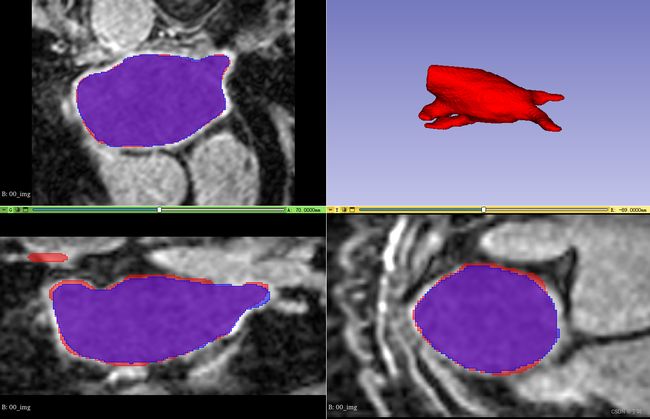
分割结果重建图:蓝色是金标签,红色是模型预测结果
- 一共154例数据,123例当做训练集,31例当做测试集
- 分别使用20%和10%的标签数据集进行实验,推理结果如下表:
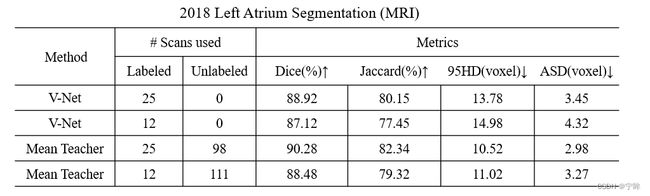
- 对比了只用有标签部分数据进行训练的结果,下图中红色为金标签,蓝色是有监督预测结果,绿色是半监督预测结果
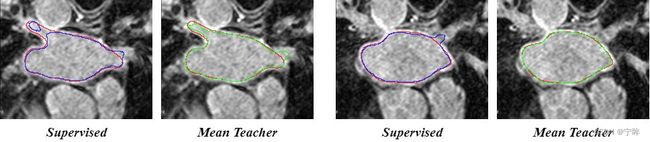
不管是评价指标,还是可视化结果,在使用同样数量有标签的数据集的情况下,半监督训练结果相比有监督结果都有显著提升。
参考资料:
Tarvainen A, Valpola H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results[J]. Advances in neural information processing systems, 2017, 30.
项目地址:
LASeg: 2018 Left Atrium Segmentation (MRI)