点亮 ⭐️ Star · 照亮开源之路https://github.com/apache/inc...

本月初,SeaTunnel同步计算引擎STE 2.3.0 beta2(commit id 7393c47)在社区的共同努力之下正式发布。与此同时,社区对大家期待的性能指标进行了测试。
为了让大家对测试结果有一个更直观的概念,我们采用了对比测试的方法。熟悉数据集成领域的人应该了解,DataX是目前数据开源同步引擎里,性能较好的同步工具之一,这次SeaTunnel做对比的对象,正是这款目前在数据集成领域使用较多的开源同步引擎。
为了保证对比测试的准确性,我们选取了相同的测试场景:在相同的资源情况下,测试DataX和SeaTunnel将数据批量从MySQL同步到HDFS,以Text格式保存,所需要花费的时间,并进行对比。
测试环境
MySQL
阿里云RDS MySQL 8Core 32G
HDFS
CPU:Intel(R) Xeon(R) Platinum 8369B CPU @ 2.70GHz
Memory:32G
节点数:3
NameNode -Xmx4G
DataNode -Xmx16G
测试数据
列数:31
行数:32226320 (3000万条)
大小:数据写入HDFS(text格式)大小为18G
我们在Mysql中创建了一张包含了31个字段的表,主键选择递增的id,其他所有字段采用随机的方式生成,除了主键外均不设置索引。
建表语句为
create table test.type_source_table
(
id int auto_increment
primary key,
f_binary binary(64) null,
f_blob blob null,
f_long_varbinary mediumblob null,
f_longblob longblob null,
f_tinyblob tinyblob null,
f_varbinary varbinary(100) null,
f_smallint smallint null,
f_smallint_unsigned smallint unsigned null,
f_mediumint mediumint null,
f_mediumint_unsigned mediumint unsigned null,
f_int int null,
f_int_unsigned int unsigned null,
f_integer int null,
f_integer_unsigned int unsigned null,
f_bigint bigint null,
f_bigint_unsigned bigint unsigned null,
f_numeric decimal null,
f_decimal decimal null,
f_float float null,
f_double double null,
f_double_precision double null,
f_longtext longtext null,
f_mediumtext mediumtext null,
f_text text null,
f_tinytext tinytext null,
f_varchar varchar(100) null,
f_date date null,
f_datetime datetime null,
f_time time null,
f_timestamp timestamp null
);DataX任务配置
为了充分利用DataX提供的特性,我们采用了DataX提供的splitPk的特性,将单个Job对应的分片进行拆分,产生一定数量的子任务。具体配置如下:
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"id",
"f_binary",
"f_blob",
"f_long_varbinary",
"f_longblob",
"f_tinyblob",
"f_varbinary",
"f_smallint",
"f_smallint_unsigned",
"f_mediumint",
"f_mediumint_unsigned",
"f_int",
"f_int_unsigned",
"f_integer",
"f_integer_unsigned",
"f_bigint",
"f_bigint_unsigned",
"f_numeric",
"f_decimal",
"f_float",
"f_double",
"f_double_precision",
"f_longtext",
"f_mediumtext",
"f_text",
"f_tinytext",
"f_varchar",
"f_date",
"f_datetime",
"f_time",
"f_timestamp"
],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://seatunnel.rds.aliyuncs.com:3306/test"
],
"table": [
"type_source_table"
]
}
],
"password": "password",
"username": "root",
"splitPk": "id"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "id",
"type": "INT"
},
{
"name": "f_binary",
"type": "STRING"
},
{
"name": "f_blob",
"type": "STRING"
},
{
"name": "f_long_varbinary",
"type": "STRING"
},
{
"name": "f_longblob",
"type": "STRING"
},
{
"name": "f_tinyblob",
"type": "STRING"
},
{
"name": "f_varbinary",
"type": "STRING"
},
{
"name": "f_smallint",
"type": "SMALLINT"
},
{
"name": "f_smallint_unsigned",
"type": "SMALLINT"
},
{
"name": "f_mediumint",
"type": "SMALLINT"
},
{
"name": "f_mediumint_unsigned",
"type": "SMALLINT"
},
{
"name": "f_int",
"type": "INT"
},
{
"name": "f_int_unsigned",
"type": "INT"
},
{
"name": "f_integer",
"type": "INT"
},
{
"name": "f_integer_unsigned",
"type": "INT"
},
{
"name": "f_bigint",
"type": "BIGINT"
},
{
"name": "f_bigint_unsigned",
"type": "BIGINT"
},
{
"name": "f_numeric",
"type": "DOUBLE"
},
{
"name": "f_decimal",
"type": "DOUBLE"
},
{
"name": "f_float",
"type": "FLOAT"
},
{
"name": "f_double",
"type": "DOUBLE"
},
{
"name": "f_double_precision",
"type": "DOUBLE"
},
{
"name": "f_longtext",
"type": "STRING"
},
{
"name": "f_mediumtext",
"type": "STRING"
},
{
"name": "f_text",
"type": "STRING"
},
{
"name": "f_tinytext",
"type": "STRING"
},
{
"name": "f_varchar",
"type": "STRING"
},
{
"name": "f_date",
"type": "DATE"
},
{
"name": "f_datetime",
"type": "TIMESTAMP"
},
{
"name": "f_time",
"type": "DATE"
},
{
"name": "f_timestamp",
"type": "TIMESTAMP"
}
],
"defaultFS": "hdfs://hadoop1:9000",
"fieldDelimiter": ",",
"fileName": "result",
"fileType": "text",
"path": "/test/result",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": 8
}
}
}
}在固定JVM内存为8G的情况下,得到最佳的channel数为8。同时固定channel数的情况下,得到最佳的内存大小为2G,用时114S完成同步。基于该结论,我们在相同的内存和并发数上,测试SeaTunnel能够达到的速度。
SeaTunnel Engine任务配置
在SeaTunnel中,我们同样使用和DataX类似的特性,根据ID字段来进行数据拆分,分成多个子任务进行数据处理。
下面是SeaTunnel的配置文件:
env {
# You can set engine configuration here
job.mode = "BATCH"
checkpoint.interval = 300000
#execution.checkpoint.data-uri = "hdfs://localhost:9000/checkpoint"
}
source {
# This is a example source plugin **only for test and demonstrate the feature source plugin**
jdbc{
url = "jdbc:mysql://seatunnel.mysql.rds.aliyuncs.com:3306/test"
driver = "com.mysql.cj.jdbc.Driver"
user = "root"
password = "password"
query = "select * from type_source_table"
partition_column = "id"
parallelism = 8
}
}
transform {
}
sink {
HdfsFile {
fs.defaultFS="hdfs://hadoop1:9000"
path="/test/result/"
field_delimiter="\t"
row_delimiter="\n"
file_name_expression="${transactionId}_${now}"
file_format="text"
filename_time_format="yyyy.MM.dd"
is_enable_transaction=true
}
}在相同的2G,8线程的情况下,SeaTunnel Engine比DataX快20%,具体对比见后表。
结论
在对比了最佳的配置之后,我们针对不同的内存大小,不同的线程数进行了更加深入的对比。在相同的环境下,重复测试得到如下对比结果图表。
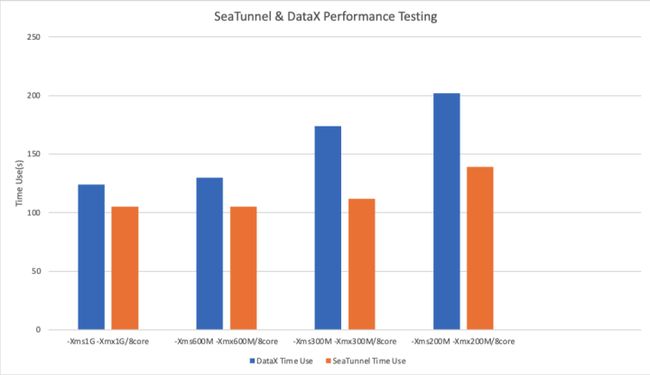
单位:秒
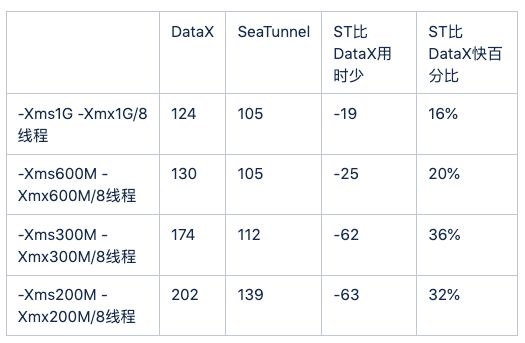
从上表可以看出,在相同测试环境下,最新发布的同步计算引擎 SeaTunnel Engine 均比DataX同步数据的速度更快,甚至在内存吃紧的情况下,内存的降低对SeaTunnel Engine没有显著影响。这得益于SeaTunnel优秀的架构和高效的代码逻辑。
值得注意的是,这只是单机版本测试,DataX也支持单机版本,而SeaTunnel新引擎是支持集群版本的,单机性能差异就如此之大,可想而知SeaTunnel集群会给用户带来多大的性能提升!Note:本次对比基于DataX: datax_v202209. SeaTunnel: commit id 7393c47,欢迎大家下载测试!