CoLAKE: 如何实现非结构性语言和结构性知识表征的同步训练
©原创作者 | 疯狂的Max
论文CoLAKE: Contextualized Language and Knowledge Embedding 解读
01 背景与动机
随着预训练模型在NLP领域各大任务大放异彩,一系列研究都致力于将外部知识融入大规模预训练模型,比如ERNIE[1]和KnowBERT[2],然而这些模型的局限性可以总结为以下三个方面:
(1)entity embedding都是通过一些knowledge embedding(KE) models,比如用TransE[3],预先提前训练好的。因此模型并不是一个真正的同步训练知识表征和语言表征的综合模型;
(2)只利用了知识图谱中的entity embedding来提升预训练模型,很难完全获取的知识图谱中一个实体丰富的上下文信息。因此对应的效能增益也就局限于预先训练好的 entity embedding的质量。
(3)预训练好的entity embedding是固定的,并且在知识图谱稍作改变时都需要重新训练。针对这三点局限,本文作者提出一种CoLAKE模型,通过改造模型的输入和结构,沿用预训练模型的MLM目标,对语言和知识的表征同时进行同步训练,将其统一在一个一致的表征空间中去。不同于前人的模型,CoLAKE根据知识的上下文和语言的上下文动态的表征一个实体。
为了解决非结构化文本与知识之间的异构性冲突,CoLAKE将两者以一种统一的数据结果将两者整合起来,形成word-knowledge graph,将其作为预训练数据在改造后的Transformer encoder模型上进行预训练。
除此之外,CoLAKE拓展了原始BERT的MLM训练任务,也就是将掩码策略应用的word,entity,relation节点上,通过WK graph未被掩盖的上下文和知识来预测掩盖的节点。
作者在GLUE和一些知识导向的下游任务上进行了实验,结果证明CoLAKE在大多数任务上都超越了原始的预训练模型和其他融合知识图谱的预训练模型。
总结起来,CoLAKE有以下三个亮点:
(1)通过扩展MLM训练任务同步学习到了带有上下文的语言表征和知识表征。
(2)采用WK graph的方法融合了语言和知识的异构性。
(3)本质上是一个预训练的GNN网络,因此其结构性可扩展。
02 模型方法
CoLAKE在结构化的、无标签的word-knowledge graphs的数据上对结合了上下文的语言和知识表征进行联合的、同步的预训练。其实现方法是先构造出输入句子对应的WK graphs,然后对模型结构和训练目标稍作改动。具体实现如下:
①构造WK graphs
先对输入的句子中的mention进行识别,然后通过一个entity linker找到其在特定知识图谱中对应的entity。Mention结点被替换为相应的entity,被称作anchor nodes。
以这个anchor node为中心,可以提取到多种三元组关系来形成子图,提取到的这些子图和句子中的词语,以及anchor node一起拼接起来形成WK graph,如下图 Figure 2所示。
实际上,对于每个anchor node,作者随机玄奇最多15个相邻关系和实体来构建WK graph,并且只考虑anchor node在三元组中是head的情况。

②模型结构改动
接下来构建好的WK graph进入Transformer Encoder,CoLAKE对embedding层和encoder层都做了相应的改造。
Embedding Layer:输入的embedding是token embedding,type embedding和position embedding的加和。
其中,token embedding,需要构建word、relation和entity三种类型的查找表。
对于word embedding,采用Roberta一样的BPE的分词方法,将词语切割为字词用以维护大规模的词典。相应的,对每一个entity和relation就沿用一般的知识嵌套方法一样来获取对应的embedding。
然后输入中token embedding则是由word embedding,entity embedding, relation embedding拼接起来,这三者是同样维度的向量。
因为WK graph会将原本的输入以token为单位进行重组,因此输入的token序列会看起来像是一段错乱的序列,因此需要对应修正其type input和position input。
其中对于每个token,其同一对应的type会用来表征该token对应的node的类型,比如是word,entity或者是relation;对应的position也是根据WK graph赋予的。下图给出了一个具体的例子进行说明:
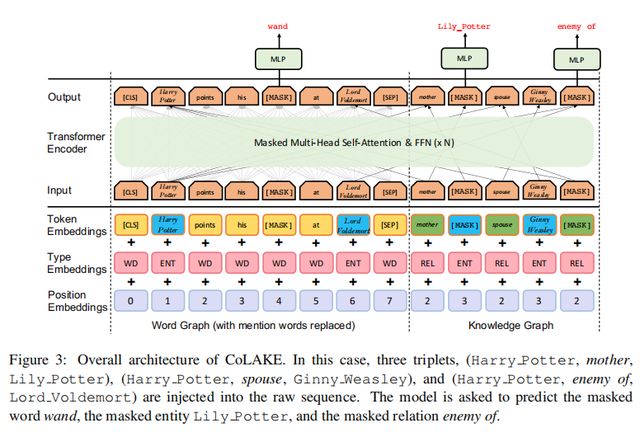


可以看出,模型的改动就是在计算注意力矩阵的时候,对于没有关联的节点加上了负无穷,使得两者不可见,以这种方式体现出WK graph的结构。
③训练目标
MLM是指随机的掩盖掉输入中的某些词,让模型预测掩盖掉的词是什么。而CoLAKE就是将MLM从词序列拓展到了WK graphs。
作者随机掩盖15%的节点,80%的时间用[MASK]替代,10%的时间随机替换成同类型的其他节点,10%时间不做任何改变。
通过掩盖词语,关系和实体三种不同的结点,能从不同角度帮助模型更好的同时学习到语言本身和知识图谱中的知识,并且对齐语言和知识的表征空间。
同时,作者提到在预测anchor node的时候,模型可能会更容易借助知识上下文而不是语言上下文,因为后者的多样性和学习难度更大。为了规避这个问题,作者在预训练时在50%的时间里丢弃了anchor nodes的相邻节点,从而减少来自知识图谱的帮助。
03 实验结果
CoLAKE模型在知识导向类任务(entity typing和relation extraction任务)上表现都超越了其他融合知识图谱的预训练模型,实验结果如下图所示:

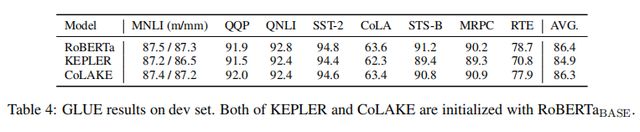
同时,CoLAKE在语言理解类的任务(GLUE)[4]上表现与未加入知识图谱的Roberta模型相当,且优于同样用Roberta初始化训练KEPLER模型效果(加入了知识图谱的KEPLER在语言理解类任务上效果会变差的更为明显),实验结果如下图所示。
因此由此得出结论,CoLAKE可以通过异构的WK graph同时模型化文本和知识。
总而言之,文中的实验结果表明CoLAKE可以在知识导向的任务上提升模型性能,并且在语言理解类任务上获得与原本的预训练模型相当的效果。
另外,作者还设计了一个word-knowledge graph completion的任务来探索CoLAKE在模型化结构特征上的能力,分别通过直推式的设定和归纳式的设定来进行任务训练,输出是三元组中的实体或者关系。简单来说就是,通过输入三元组
![]()
直推式的设定指h,r,t都分别出现在训练集中,但是这个三元组组合没有出现在训练集中;归纳式的设定是指h和t至少有一个实体并未出现在训练集中。
作者也将CoLAKE与常见的集中知识图谱嵌套训练的模型进行了效果比较,如下图所示,效果也是赶超了其他知识图谱嵌套模型。

04 结论和未来研究方向
CoLAKE模型实现了非结构化的语言表征和结构化的知识表征同步综合训练。其通过一种统一化的数据结构word-knowledge graph实现了语言上下文和知识上下文的融合。实验结构表明CoLAKE模型在知识导向类NLP任务上的有效性。
除此之外,作者还通过设计一种WK graph complication的任务来探索了WK graph的应用潜力和未来的研究方向:
(1)CoLAKE可以用于关系抽取中远距离标注样例的去噪。
(2)CoLAKE可以用于检测graph-to-text模板的效果。
参考文献
[1] Zhengyan Zhang, Xu Han, Zhiyuan Liu, Xin Jiang, Maosong Sun, and Qun Liu. 2019. ERNIE: enhanced language representation with informative entities. In ACL, pages 1441–1451
[2]Matthew E. Peters, Mark Neumann, Robert L. Logan IV, Roy Schwartz, Vidur Joshi, Sameer Singh, and Noah A.
Smith. 2019. Knowledge enhanced contextual word representations. In EMNLP-IJCNLP, pages 43–54.
[3]Antoine Bordes, Nicolas Usunier, Alberto Garc´ıa-Dur´an, Jason Weston, and Oksana Yakhnenko. 2013. Translating embeddings for modeling multi-relational data. In NIPS.
[4]Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. 2019a. GLUE: A multi-task benchmark and analysis platform for natural language understanding. In ICLR.