LSTM模型介绍
RNN
什么是RNN模型
循环神经网络,序列数据为输入,通过网络内部的结构设计有效捕捉序列之间的关系特征,一般也是以序列形式进行输出。
一般单层神经网络结构

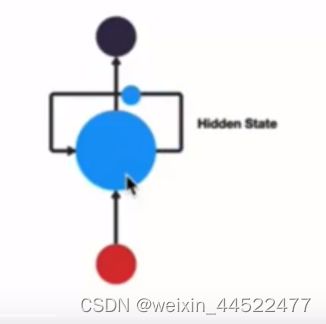
RNN单层网络结构
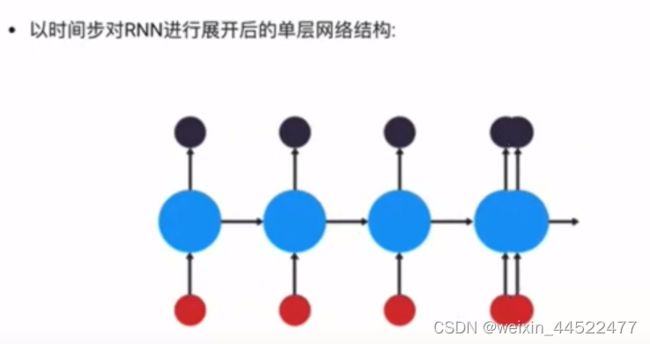
以时间步对RNN进行展开后的单层网络结构

RNN模型的作用
能够很好的利用序列之间的关系,自然界具有连续性的输入序列
RNN模型
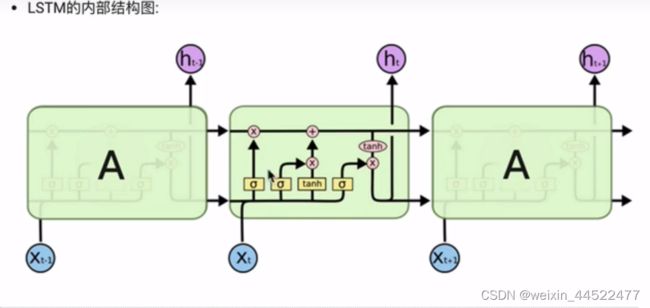
传统RNN的内部结构图
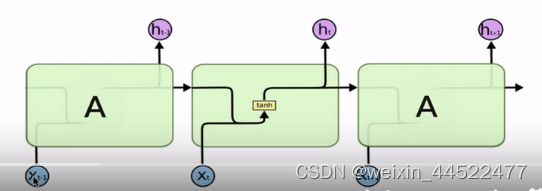
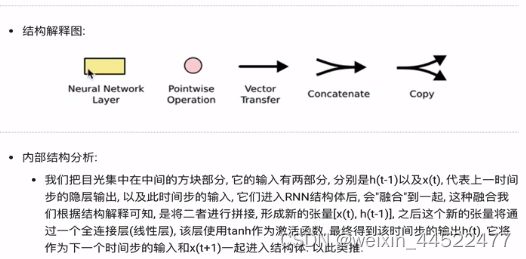

括号里面就是一个全连接的线性层

nn.RNN类初始化主要参数解释:
input_size:输入张量x中特征维度的大小
hidden_size:隐藏张量h中的特征维度的大小
num_layers:隐含层的数量
nonlinearity:激活函数的选择,默认是tanh
nn.RNN类实例化对象主要参数解释
input:输入张量x
h0:初始化的隐层张量h
RNN使用实例
import torch
import torch.nn as nn
# 5是input_size , 6是hidden_size , 1是num_layers
rnn = nn.RNN(5,6,1)
# 1 代表sequence lines 序列的长度,默认序列的长度只有1
# 3 代表批次的数量batch_size 扔进去3个样本,每个样本长度为1
# 5 代表inputsize
# 这两个要对应上
input = torch.randn(1,3,5)
# 1代表的是num_layers 这个1 要和rnn最后的那个1要对应上
# 3代表的是批次的数量
# 6代表的是hidden_size
h0 = torch.randn(1,3,6)
output, hn = rnn (input, h0)
print(output)
print(hn)
传统RNN的优势
内部结构简单,对计算资源要求低,相比RNN变体,参数总量少了很多,短序列任务上性能和效果都表现优异
传统RNN的缺点
解决长序列之间的关联,RNN表现很差
什么是梯度消失或爆炸
根据反向传播的算法和链式法则
soigmoid的导数值域是固定的,在[0,0,25]之间,一旦w小于1,那么梯度会非常非常小,梯度消失
w大于1,之后连乘可能会造成梯度过大,就是梯度爆炸
梯度消失或爆炸的危害
消失:权重无法更新,训练失败
爆炸:大幅度更新网络参数,会溢出(NaN值)
小结
学习了传统RNN的结构并且进行了分析
根据结构分析得出了传统RNN的计算公式
学习了激活函数tanh的作用
学习了pytorch中传统rnn工具的使用
在torch.nn工具包之中,通过torch.nn.RNN可调用
nn.RNN类初始化主要参数解释
nn.RNN实例化对象主要参数解释
实现了nn.RNN的使用实例,获得RNN的真实返回结构样式
学习了传统RNN的优点
学习了传统RNN的缺点
学习了什么是梯度消失或爆炸
梯度消失或爆炸的危害
区分实例化和初始化
实例化:在堆空间中开辟一块空间,属性值是默认值
初始化:1、赋值 2、调用初始化方法
面向对象变成
定义函数
def f():
pass
定义类的方法
class类名
实例化对象
vae = Singer()
python中的一切皆为对象
新建一个对象的过程叫做实例化,而面向对象就是这个类的实例
所有的类都要设置他的初始方法
def init(self,h,w):
self.height = h
self.weight = w
步骤
1、进行分词
2、将RNN

3、
LSTM内部结构
RNN模型的分类
第一个角度:输入和输出的结构
第二个角度:RNN的内部构造

LSTM
Bi-LSTM
GRU
Bi-GRU

N vs N RNN
输入和输出序列是等长的

N vs 1-RNN
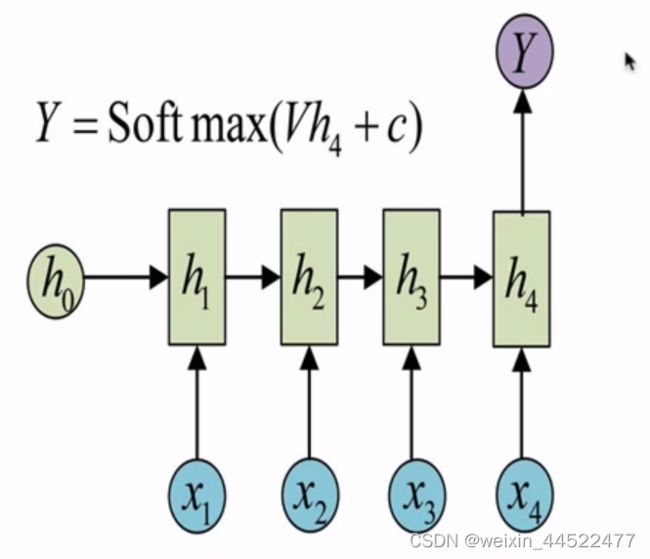
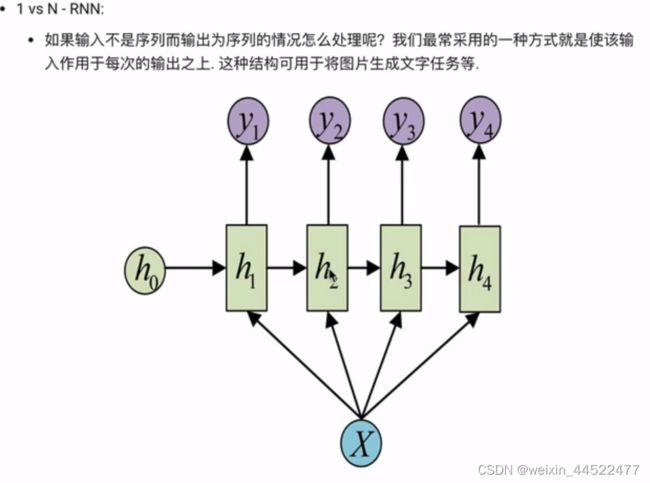
1 VS N-RNN
N VS M -RNN == seq2seq
总结
学习了什么是RNN模型

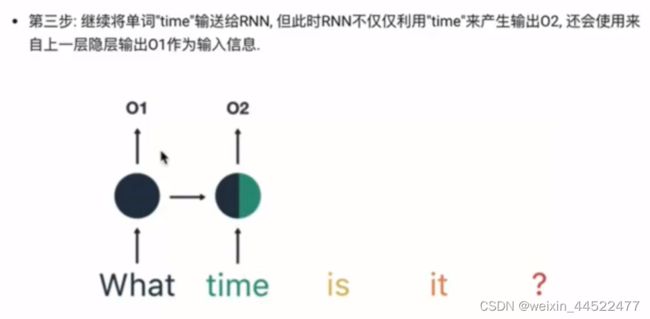
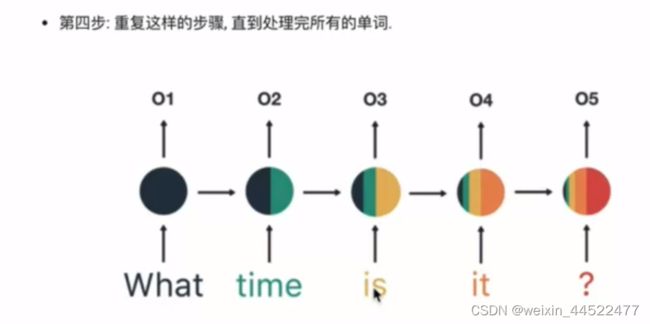
时间步的输入

学习了RNN模型的作用

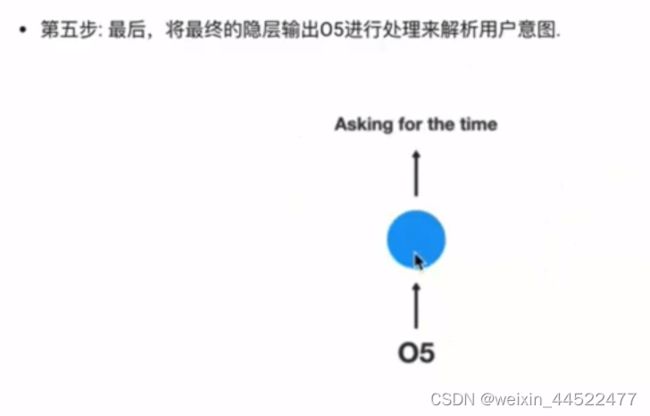
以一个用户意图识别对RNN的运行过程进行简单的分析

学习了RNN模型的分类

按照输入和输出的结构进行分类

N VS N

1 VS N

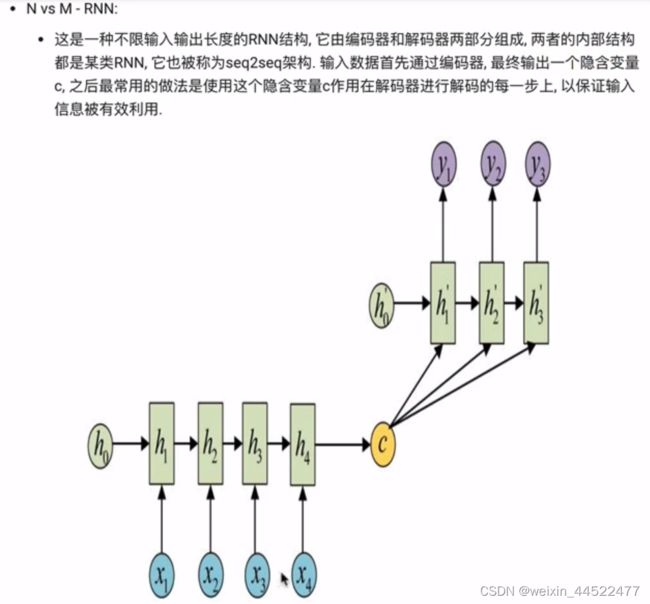
N vs M -RNN

遗忘门部分结构图与计算公式:
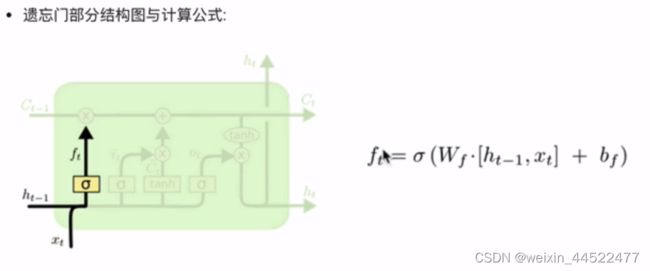
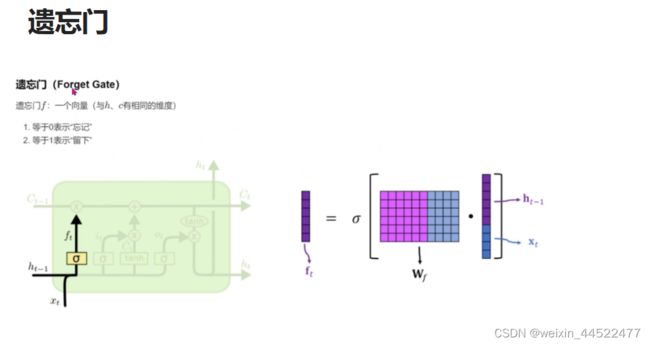
当前时间步输入x(t)与上一个时间步隐含状态h(t-1)拼接,得到[x(t),h(t-1)],通过一个全连接层做变换,最后通过sigmoid函数进行激活得到f(t)

拼接,全连接层,sigmoid
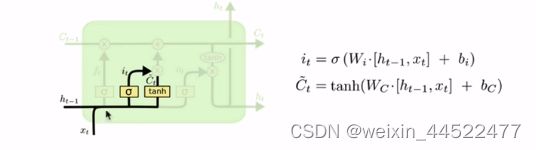
输入门部分

细胞状态的更新公式
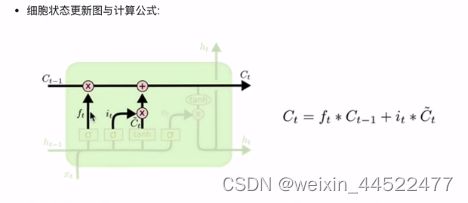
细胞状态更新分析
这里没有全连接层,对遗忘门和输入门的应用
输出
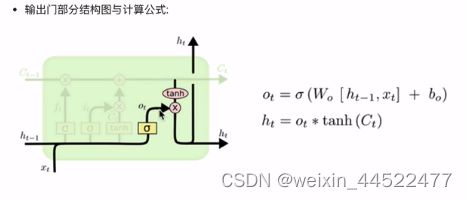
输出门结构分析

什么是Bi-LSTM
双向LSTM,将LSTM应用两次且方向不同,再将两次得到的LSTM结果进行拼接作为最终输出
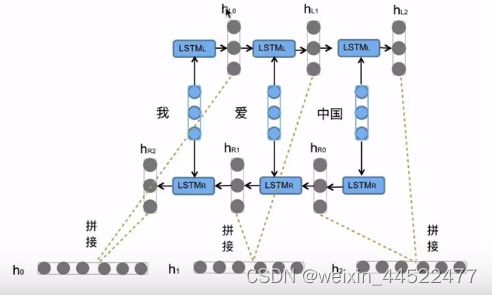
Bi-LSTM结构分析

pytorch中LSTM工具的使用
位置:torch.nn工具包中,通过torch.nnLSTM可调用
nn.LSTM类初始化主要参数解释:
input_size : 输入张量x中特征维度的大小
hidden_size:隐藏层h中特征维度的大小
num_layers:隐含层的数量
didirectional: 是否使用双向LSTM,true 使用,默认不适用
nn.LSTM类实例化对象主要参数解释
input:输入张量x
h0:初始化的隐藏张量h
c0 初始化的细胞状态张量c
import torch.nn as nn
import torch
# input_size ,hidden_size, num_layers
rnn = nn.LSTM(5,6,2)
# sequence_length ,batch_size, input_size
input = torch.randn(1,3,5)
# numlayers * num_directions, batch_size, hidden_size
h0 = torch.randn(2,3,6)
c0 = torch.randn(2,3,6)
# 以元组的形式
output , (hn,cn) = rnn(input,(h0,c0))
print(output)
print(hn)
print(cn)
D:\soft\Anaconda\envs\py3.9\python.exe D:/soft/pycharm/pythonProject2/lstm.py
D:\soft\Anaconda\envs\py3.9\lib\site-packages\numpy\_distributor_init.py:30: UserWarning: loaded more than 1 DLL from .libs:
D:\soft\Anaconda\envs\py3.9\lib\site-packages\numpy\.libs\libopenblas.FB5AE2TYXYH2IJRDKGDGQ3XBKLKTF43H.gfortran-win_amd64.dll
D:\soft\Anaconda\envs\py3.9\lib\site-packages\numpy\.libs\libopenblas.XWYDX2IKJW2NMTWSFYNGFUWKQU3LYTCZ.gfortran-win_amd64.dll
warnings.warn("loaded more than 1 DLL from .libs:"
tensor([[[ 0.0867, 0.0354, -0.0068, 0.0347, 0.2502, -0.2756],
[ 0.1433, 0.1281, -0.0776, -0.0699, -0.0900, 0.2889],
[ 0.2203, -0.0354, 0.3930, 0.2998, -0.1798, -0.0987]]],
grad_fn=<StackBackward>)
tensor([[[ 0.1750, 0.1526, -0.1788, 0.1234, 0.2230, -0.1545],
[-0.4637, 0.1530, 0.0303, 0.0616, 0.3010, 0.1652],
[ 0.0795, -0.1465, -0.0737, -0.1696, 0.0936, 0.1401]],
[[ 0.0867, 0.0354, -0.0068, 0.0347, 0.2502, -0.2756],
[ 0.1433, 0.1281, -0.0776, -0.0699, -0.0900, 0.2889],
[ 0.2203, -0.0354, 0.3930, 0.2998, -0.1798, -0.0987]]],
grad_fn=<StackBackward>)
tensor([[[ 0.9071, 0.2414, -0.2322, 0.2574, 0.4197, -0.4590],
[-0.8565, 0.5892, 0.1264, 0.1650, 0.4485, 0.2284],
[ 0.0987, -0.2620, -0.4472, -0.6427, 0.3347, 0.4593]],
[[ 0.1688, 0.0582, -0.0092, 0.0719, 0.5004, -0.5076],
[ 0.2919, 0.5513, -0.1347, -0.1001, -0.1380, 0.5266],
[ 0.3791, -0.0804, 0.5880, 0.5721, -0.3618, -0.1248]]],
grad_fn=<StackBackward>)
进程已结束,退出代码0
LSTM优势
缓解长序列问题中可能出现的梯度消失或爆炸
LSTM缺点
内部结构相对复杂
小结
LSTM :长短时记忆结构,有效捕捉长序列之间的语义关联,缓解梯度消失或爆炸现象

遗忘门结构分析

输入门结构分析

细胞状态更新分析

输出门结构分析

什么是Bi-LSTM?

Pytorch中LSTM工具的使用
torch.nn.LSTM
LSTM优势

LSTM缺点
![]()
GRU模型
GRU
门控循环单元结构,RNN变体,同LSTM一样能够有效捕捉长序列之间的语义关联,缓解梯度消失或爆炸,同时内部结构和LSTM跟简单
内部结构
输入的数据ht-1,xt
zt =
rt = [重置门]

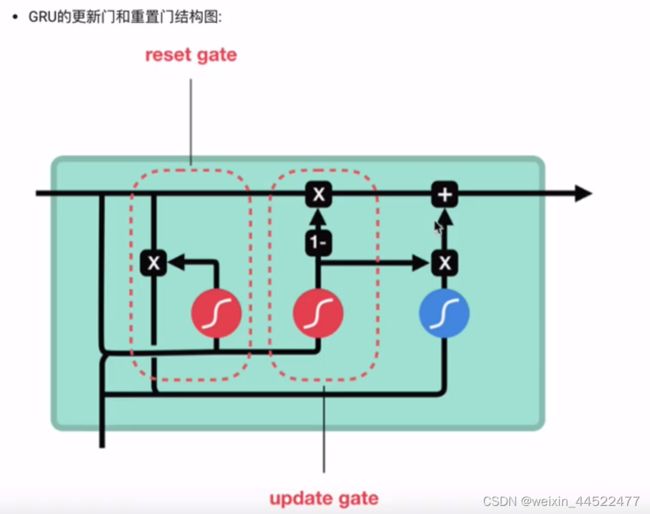
内部结构分析

Bi-GRU

Pytorch中GRU工具的使用
torch.nn.GRU
nn.GRU初始化主要参数解释
input_size
hidden_size
num_layers
bidirectional
nn.GRU实例化对象主要参数解释
input
h0
import torch.nn as nn
import torch
# input_size ,hidden_size, num_layers
rnn = nn.GRU(5,6,2)
# sequence_length ,batch_size, input_size
input = torch.randn(1,3,5)
# numlayers * num_directions, batch_size, hidden_size
h0 = torch.randn(2,3,6)
output , hn = rnn(input,h0)
print(output)
print(hn)
D:\soft\Anaconda\envs\py3.9\python.exe D:/soft/pycharm/pythonProject2/gru.py
D:\soft\Anaconda\envs\py3.9\lib\site-packages\numpy\_distributor_init.py:30: UserWarning: loaded more than 1 DLL from .libs:
D:\soft\Anaconda\envs\py3.9\lib\site-packages\numpy\.libs\libopenblas.FB5AE2TYXYH2IJRDKGDGQ3XBKLKTF43H.gfortran-win_amd64.dll
D:\soft\Anaconda\envs\py3.9\lib\site-packages\numpy\.libs\libopenblas.XWYDX2IKJW2NMTWSFYNGFUWKQU3LYTCZ.gfortran-win_amd64.dll
warnings.warn("loaded more than 1 DLL from .libs:"
tensor([[[-2.1081, -1.8786, 0.7801, 0.6195, -0.4054, 0.4824],
[ 0.1515, -1.2044, -0.5086, 0.1802, -0.9434, 0.3541],
[ 0.4296, 0.7295, 0.1732, -0.2709, 0.0179, 0.9309]]],
grad_fn=<StackBackward>)
tensor([[[-1.0261, -0.0409, -0.1843, -0.1713, -0.0056, 0.0401],
[-0.8273, 0.5856, 0.4567, 0.3900, -0.2781, 0.2099],
[-0.8233, -0.0060, -0.5231, -0.1884, -0.2216, 0.3113]],
[[-2.1081, -1.8786, 0.7801, 0.6195, -0.4054, 0.4824],
[ 0.1515, -1.2044, -0.5086, 0.1802, -0.9434, 0.3541],
[ 0.4296, 0.7295, 0.1732, -0.2709, 0.0179, 0.9309]]],
grad_fn=<StackBackward>)
进程已结束,退出代码0
GRU的优势

缺点:

并不能完全解决梯度消失的问题
小节总结
GRU
内部结构分析
Bi-GRU
Pytorch中GRU工具的使用
GRU的优势
GRU的缺点
注意力机制
什么是注意力
什么是注意力计算规则


当注意力权重矩阵和V都是三维张量且第一维代表为batch条数时,则做bmm运算bmm是一种特殊的张量乘法运算
bmm 运算演示:

第一个维度保持不变,nm mp 之后就是n*p
什么是注意力机制

说明

注意力机制的作用
在解码器端的注意力机制:
在编码器端的注意力机制

注意力机制实现步骤

https://zhuanlan.zhihu.com/p/149490072
二、怎么通过ATTENTION改变单词的注意力呢?
hidden state的传递方式有两种:一是,只把最后一步的hidden state传递出去。二是,把之前所有的hidden state都传递出去。
attention机制的特点:
attention需要把之前所有的hidden state都传递出去,
为每一个hidden state产生不同的权重
把每一个hidden state分别乘以softmax的权重,然后求和,作为decoder的输入

h1、h2、h3是三个法语单词依次输入后产生的hidden state,对他们分别打分,最终的权重求和得到蓝色的向量,然后将蓝色的向量与紫色向量拼接作为decoder新的输入。
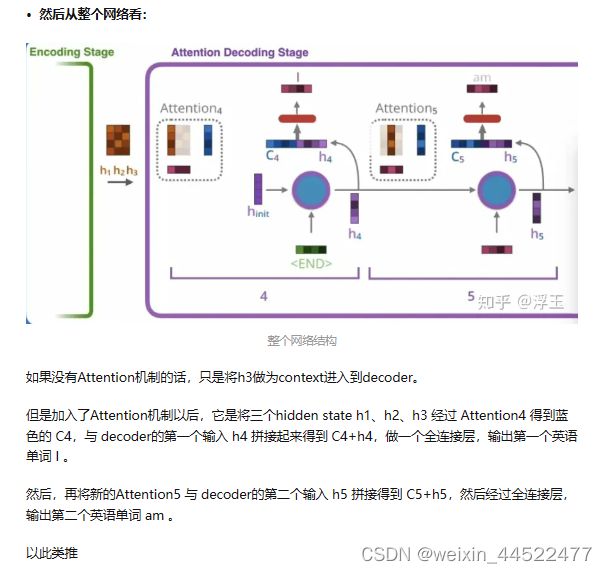
注:可以看到hidden state h1、h2、h3 是被反复使用的,它与decoder的每一个输入都用到一次。
那Attention4 与 Attention5有什么区别呢?
从图中,你可以看到,Attention4 与 Attention5里面,他们对于h1、h2、h3的权重是不同的,Attention4 中,h1的权重最大,说明它认为 第一个法语单词 Je 与英语单词 I 的关系最大。Attention5 中,h2的权重最大,说明它认为 第二个法语单词 suis 与英语单词 am 的关系最大。
这就是attention的作用,改变了每个单词的注意力。


import torch
import torch.nn as nn
import torch.nn.functional as F
class Attn(nn.Module):
def __init__(self,query_size,key_size,value_size1,value_size2,output_size):
"""
:param query_size: query的最后一维大小
:param key_size: key最后一维的大小
value = (1,value_size1,value_size2)
:param value_size1: 代表value的倒数第二维大小
:param value_size2: 代表value的倒数第一维大小
:param output_size: 输出的最后一维大小
"""
super(Attn, self).__init__()
self.query_size = query_size
self.key_size = key_size
self.value_size1 = value_size1
self.value_size2 = value_size2
self.output_size = output_size
# 初始化注意力机制实现第一步中需要的线性层
# query+key这两个线性层加和作为我们的输入尺寸,valuesize1,作为我们的输出尺寸
self.attn = nn.Linear(self.query_size+self.key_size,self.value_size1)
# 第三层需要的线性层
self.attn_combine = nn.Linear(self.query_size+self.value_size2,self.output_size)
def forward(self,Q,K,V):
# 第一步:按照计算规则进行计算
# 采用常规的第一种计算,Q,K进行纵轴凭借,做一次线性变换,最后使用softmax获得结果
# 最后一个维度上进行拼接
attn_weights = F.softmax(self.attn(torch.cat((Q[0],K[0]),1)),dim = 1)
# 权重矩阵与V做矩阵乘法计算,二者都是三维张量且第一维代表batch条数时,则用bmm运算
attn_applied = torch.bmm(attn_weights.unsqueeze(0),V)
# 通过取[0]降维,将Q与第一步获得结果进行凭借
output = torch.cat((Q[0],attn_applied[0]),1)
# 最后时第三步,第三步的结果上做一个线性变化并扩展,得到输出
# 因为要保证输出也是三维张量,因此使用unsqueeze(0)扩展维度
output = self.attn_combine(output).unsqueeze(0)
return output,attn_weights
query_size = 32
key_size = 32
value_size1 = 32
value_size2 = 64
output_size = 64
attn = Attn(query_size,key_size,value_size1,value_size2,output_size)
Q = torch.randn(1,1,32)
K = torch.randn(1,1,32)
V = torch.randn(1,32,64)
output = attn(Q,K,V)
print(output[0])
print(output[0].shape)
D:\soft\Anaconda\envs\py3.9\python.exe D:/soft/pycharm/pythonProject2/attn.py
D:\soft\Anaconda\envs\py3.9\lib\site-packages\numpy\_distributor_init.py:30: UserWarning: loaded more than 1 DLL from .libs:
D:\soft\Anaconda\envs\py3.9\lib\site-packages\numpy\.libs\libopenblas.FB5AE2TYXYH2IJRDKGDGQ3XBKLKTF43H.gfortran-win_amd64.dll
D:\soft\Anaconda\envs\py3.9\lib\site-packages\numpy\.libs\libopenblas.XWYDX2IKJW2NMTWSFYNGFUWKQU3LYTCZ.gfortran-win_amd64.dll
warnings.warn("loaded more than 1 DLL from .libs:"
tensor([[[-0.1365, -0.1259, -0.0329, -0.0605, 0.7238, 0.1879, 0.1530,
-0.5935, -0.4875, -0.1800, -0.0673, -0.3098, -0.7372, -0.3502,
0.0543, -0.3663, 0.2258, 0.2067, -0.0176, -0.3560, -0.0180,
0.1018, -0.1429, -0.2855, 0.3333, -0.0224, -0.3212, 0.1791,
0.3355, 0.2825, 0.1512, -0.2425, -0.0071, 0.3924, -0.1767,
-0.0978, -0.1758, -0.3391, -0.2964, 0.1843, 0.1408, 0.1242,
-0.0858, 0.0758, -0.2991, 0.0996, 0.2131, 0.2792, -0.7501,
0.6018, 0.2456, 0.4188, -0.0011, 0.4325, 0.2081, 0.0818,
-0.6174, -0.3048, 0.0489, -0.4158, -0.2528, -0.3071, 0.1895,
-0.1521]]], grad_fn=<UnsqueezeBackward0>)
torch.Size([1, 1, 64])
进程已结束,退出代码0
使用RNN模型构建人名分类器
关于人名分类问题
一个人名为输入,判断他最可能来自哪一个国家的人名。

问题
D:\soft\Anaconda\envs\py3.9\python.exe D:/soft/pycharm/pythonProject2/exrnn.py
D:\soft\Anaconda\envs\py3.9\lib\site-packages\numpy\_distributor_init.py:30: UserWarning: loaded more than 1 DLL from .libs:
D:\soft\Anaconda\envs\py3.9\lib\site-packages\numpy\.libs\libopenblas.FB5AE2TYXYH2IJRDKGDGQ3XBKLKTF43H.gfortran-win_amd64.dll
D:\soft\Anaconda\envs\py3.9\lib\site-packages\numpy\.libs\libopenblas.XWYDX2IKJW2NMTWSFYNGFUWKQU3LYTCZ.gfortran-win_amd64.dll
warnings.warn("loaded more than 1 DLL from .libs:"
n_letters: 57
进程已结束,退出代码0
删掉一个dll
D:\soft\Anaconda\envs\py3.9\python.exe D:/soft/pycharm/pythonProject2/exrnn.py
n_letters: 57
进程已结束,退出代码0
好勒
D:\soft\Anaconda\envs\py3.9\python.exe D:/soft/pycharm/pythonProject2/exrnn.py
Traceback (most recent call last):
File "D:\soft\pycharm\pythonProject2\exrnn.py", line 19, in <module>
import matplotlib.pyplot as plt
File "D:\soft\Anaconda\envs\py3.9\lib\site-packages\matplotlib\pyplot.py", line 2230, in <module>
switch_backend(rcParams["backend"])
File "D:\soft\Anaconda\envs\py3.9\lib\site-packages\matplotlib\__init__.py", line 672, in __getitem__
plt.switch_backend(rcsetup._auto_backend_sentinel)
File "D:\soft\Anaconda\envs\py3.9\lib\site-packages\matplotlib\pyplot.py", line 247, in switch_backend
switch_backend(candidate)
File "D:\soft\Anaconda\envs\py3.9\lib\site-packages\matplotlib\pyplot.py", line 267, in switch_backend
class backend_mod(matplotlib.backend_bases._Backend):
File "D:\soft\Anaconda\envs\py3.9\lib\site-packages\matplotlib\pyplot.py", line 268, in backend_mod
locals().update(vars(importlib.import_module(backend_name)))
File "D:\soft\Anaconda\envs\py3.9\lib\importlib\__init__.py", line 127, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "D:\soft\Anaconda\envs\py3.9\lib\site-packages\matplotlib\backends\backend_qtagg.py", line 12, in <module>
from .backend_qt import (
File "D:\soft\Anaconda\envs\py3.9\lib\site-packages\matplotlib\backends\backend_qt.py", line 73, in <module>
_MODIFIER_KEYS = [
File "D:\soft\Anaconda\envs\py3.9\lib\site-packages\matplotlib\backends\backend_qt.py", line 74, in <listcomp>
(_to_int(getattr(_enum("QtCore.Qt.KeyboardModifier"), mod)),
TypeError: int() argument must be a string, a bytes-like object or a number, not 'KeyboardModifier'
进程已结束,退出代码1
升级一下试试
pip install -U matplotlib
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
d2l 0.17.6 requires matplotlib==3.5.1, but you have matplotlib 3.6.2 which is incompatible.
d2l 0.17.6 requires numpy==1.21.5, but you have numpy 1.23.4 which is incompatible.
我感觉是我的版本太高了
# 从io中导入文件打开方式
from io import open
# 帮助使用正则表达式进行子目录的查询
import glob
import os
# 用于获得常见字母及字符规范化
import string
import unicodedata
# 导入随机工具random
import random
# 导入时间和数字的工具包
import time
import math
# 导入torch工具
import torch
# 导入nn准备构建模型
import torch.nn as nn
# 导入制图工具包
import matplotlib.pyplot as plt
# 获取data文件中的数据进行处理,以满足训练要求
# 获取常用的字符数量
# 获取所有常用字符包括字母和常用标点
# ascii_letters方法的作用是生成全部字母,包括a-z,A-Z
all_letters = string.ascii_letters + " .,;'"
# 获取常用字符数量
n_letters = len(all_letters)
# 输出效果
print("n_letters:",n_letters)
# 字符规范化之unicode转ascii函数
# 去掉语言中一些重音标记,俄语,法语这些有重音标记的
# def
但是我就是输入了之后,还报错,但是一点问题都没有了
D:\soft\Anaconda\envs\py3.9\python.exe D:/soft/pycharm/pythonProject2/exrnn.py
n_letters: 57
进程已结束,退出代码0
https://zhuanlan.zhihu.com/p/279218361
NLP中解决Mn问题
查了一下 unicodedata 里面关于 Mn 这个类的描述,它全称是 “Nonspacing Mark”,是 “Mark” 类下的一种。这里面主要包含的都是一些语调符号。上一个截图:

Mn是语调的问题
这里解释了 Mn 其实是 a nonspacing combining mark (zero advance width) (谷歌翻译: 一个非空格组合标志(零超前宽度))。
也就是说,这些 Mn 字符本身是没有具体的内容的,它的内容是依附于它前一个字符存在的,这也就解释了为什么我单个打印它们的时候显示的都是空白,但是检查长度的时候又非常的长(因为每一个 Mn 字符也会在 len 函数统计长度的时候加一)
而我的数据里出现的那些竖排的文字,是因为有些 Mn 符号的功能是在原本的字符的正上方或下方重复这个字符,我猜测应该是类似下面的这些
# 从io中导入文件打开方式
from io import open
# 帮助使用正则表达式进行子目录的查询
import glob
import os
# 用于获得常见字母及字符规范化
import string
import unicodedata
# 导入随机工具random
import random
# 导入时间和数字的工具包
import time
import math
# 导入torch工具
import torch
# 导入nn准备构建模型
import torch.nn as nn
# 导入制图工具包
import matplotlib.pyplot as plt
# 获取data文件中的数据进行处理,以满足训练要求
# 获取常用的字符数量
# 获取所有常用字符包括字母和常用标点
# ascii_letters方法的作用是生成全部字母,包括a-z,A-Z
all_letters = string.ascii_letters + " .,;'"
# 获取常用字符数量
n_letters = len(all_letters)
# 输出效果
# print("n_letters:",n_letters)
# 字符规范化之unicode转ascii函数
# 去掉语言中一些重音标记,俄语,法语这些有重音标记的
def unicodeToAscii(s):
# 清楚操作
return ''.join(
# 用unicodedata模块将文本标准化
# normalize()第一个参数指定字符串标准化的方法。
# NFC表示字符应该是整体组成
# NFD表示字符应该分解为多个组合字符表示
c for c in unicodedata.normalize('NFD',s)
# 语调类型
if unicodedata.category(c) != 'Mn'
and c in all_letters
)
# 构建一个持久化文件中读取内容到内存的函数
data_path = "./data/data/names/"
def readLines(filename):
"""从文件中读取每一行加载到内存中形成列表"""
# 打开指定文件并读取所有内容,使用strip()去掉两侧空白符,然后以'\n'进行切分
lines = open(filename,encoding='utf-8').read().strip().split('\n')
# 对应每一个lines列表中的名字进行ascii转换,使其规范化,最后返回一个名字列表
return [unicodeToAscii(line) for line in lines]
# 调用filename是数据集中某个具体的文件
filename = data_path + "Chinese.txt"
lines = readLines(filename)
print(lines)
D:\soft\Anaconda\envs\py3.9\python.exe D:/soft/pycharm/pythonProject2/exrnn.py
['Ang', 'AuYong', 'Bai', 'Ban', 'Bao', 'Bei', 'Bian', 'Bui', 'Cai', 'Cao', 'Cen', 'Chai', 'Chaim', 'Chan', 'Chang', 'Chao', 'Che', 'Chen', 'Cheng', 'Cheung', 'Chew', 'Chieu', 'Chin', 'Chong', 'Chou', 'Chu', 'Cui', 'Dai', 'Deng', 'Ding', 'Dong', 'Dou', 'Duan', 'Eng', 'Fan', 'Fei', 'Feng', 'Foong', 'Fung', 'Gan', 'Gauk', 'Geng', 'Gim', 'Gok', 'Gong', 'Guan', 'Guang', 'Guo', 'Gwock', 'Han', 'Hang', 'Hao', 'Hew', 'Hiu', 'Hong', 'Hor', 'Hsiao', 'Hua', 'Huan', 'Huang', 'Hui', 'Huie', 'Huo', 'Jia', 'Jiang', 'Jin', 'Jing', 'Joe', 'Kang', 'Kau', 'Khoo', 'Khu', 'Kong', 'Koo', 'Kwan', 'Kwei', 'Kwong', 'Lai', 'Lam', 'Lang', 'Lau', 'Law', 'Lew', 'Lian', 'Liao', 'Lim', 'Lin', 'Ling', 'Liu', 'Loh', 'Long', 'Loong', 'Luo', 'Mah', 'Mai', 'Mak', 'Mao', 'Mar', 'Mei', 'Meng', 'Miao', 'Min', 'Ming', 'Moy', 'Mui', 'Nie', 'Niu', 'OuYang', 'OwYang', 'Pan', 'Pang', 'Pei', 'Peng', 'Ping', 'Qian', 'Qin', 'Qiu', 'Quan', 'Que', 'Ran', 'Rao', 'Rong', 'Ruan', 'Sam', 'Seah', 'See ', 'Seow', 'Seto', 'Sha', 'Shan', 'Shang', 'Shao', 'Shaw', 'She', 'Shen', 'Sheng', 'Shi', 'Shu', 'Shuai', 'Shui', 'Shum', 'Siew', 'Siu', 'Song', 'Sum', 'Sun', 'Sze ', 'Tan', 'Tang', 'Tao', 'Teng', 'Teoh', 'Thean', 'Thian', 'Thien', 'Tian', 'Tong', 'Tow', 'Tsang', 'Tse', 'Tsen', 'Tso', 'Tze', 'Wan', 'Wang', 'Wei', 'Wen', 'Weng', 'Won', 'Wong', 'Woo', 'Xiang', 'Xiao', 'Xie', 'Xing', 'Xue', 'Xun', 'Yan', 'Yang', 'Yao', 'Yap', 'Yau', 'Yee', 'Yep', 'Yim', 'Yin', 'Ying', 'Yong', 'You', 'Yuan', 'Zang', 'Zeng', 'Zha', 'Zhan', 'Zhang', 'Zhao', 'Zhen', 'Zheng', 'Zhong', 'Zhou', 'Zhu', 'Zhuo', 'Zong', 'Zou', 'Bing', 'Chi', 'Chu', 'Cong', 'Cuan', 'Dan', 'Fei', 'Feng', 'Gai', 'Gao', 'Gou', 'Guan', 'Gui', 'Guo', 'Hong', 'Hou', 'Huan', 'Jian', 'Jiao', 'Jin', 'Jiu', 'Juan', 'Jue', 'Kan', 'Kuai', 'Kuang', 'Kui', 'Lao', 'Liang', 'Lu', 'Luo', 'Man', 'Nao', 'Pian', 'Qiao', 'Qing', 'Qiu', 'Rang', 'Rui', 'She', 'Shi', 'Shuo', 'Sui', 'Tai', 'Wan', 'Wei', 'Xian', 'Xie', 'Xin', 'Xing', 'Xiong', 'Xuan', 'Yan', 'Yin', 'Ying', 'Yuan', 'Yue', 'Yun', 'Zha', 'Zhai', 'Zhang', 'Zhi', 'Zhuan', 'Zhui']
进程已结束,退出代码0
# 构建人名类别(所属的语言)列表与人名对应关系字典
# 构建的category_lines 形如:{"English":["Lily","Su"]."Chinese":{
# 字典
category_lines = {}
# all_categories 形如:["english',```"Chinese"]
all_categories = []
# 读取指定路径下的txt文件,使用glob,path中可以使用正则表达式
# 采用glob可以运用正则表达式
# 所有的.txt文件我们都要遍历
for filename in glob.glob(data_path + '*.txt'):
# 获取每个文件的文件名,就是对应的名字类别
# os.path.basename把一个完整的文件名的路径传进来,把最后一个真实的文件名拿出来了,不要前面的斜杠的
# 如果是chinese.txt,这个os.path.basename就是chinese.txt
# .splitext 把文件名以.作为切割
# 取0 就是把chinese赋值到category
category = os.path.splitext(os.path.basename(filename))[0]
# 将其逐一装到all_categories列表中
all_categories.append(category)
# 然后读取每个文件的内容,形成名字列表
# line是个列表
lines = readLines(filename)
# 按照对应的类别,将名字列表写入到category_lines字典中
category_lines[category] = lines
# 查看类别总数
n_categories = len(all_categories)
print("n_categories:",n_categories)
# 随便查看其中的一些内容
print(category_lines['Italian'][:5])
D:\soft\Anaconda\envs\py3.9\python.exe D:/soft/pycharm/pythonProject2/exrnn.py
n_categories: 18
['Abandonato', 'Abatangelo', 'Abatantuono', 'Abate', 'Abategiovanni']
进程已结束,退出代码0
将人名转化为对应onehot张量表示
# 将人名转化为对应onehot张量表示
def lineToTensor(line):
# 首先初始化一个0张量,它的形状(len(line),1,n_letters)
# 代表人名中的每个字母用一个1 * n_letters的张量表示
tensor = torch.zeros(len(line),1,n_letters)
# 遍历这个人名中的每个字符索引和字符
# enumerate自动生成索引
for li,letter in enumerate(line):
# 使用字符穿方法find找到每个字符在all_letters中的索引
# 它也是我们生成onehot张量中1的索引位置
# li代表索引,第几个字符,第二个值为1,所以就是0,all_letters.find(letter)
tensor[li][0][all_letters.find(letter)] = 1
return tensor
# 调用
line = "Bai"
line_tensor = lineToTensor(line)
print("line_tensor:",line_tensor)
D:\soft\Anaconda\envs\py3.9\python.exe D:/soft/pycharm/pythonProject2/exrnn.py
line_tensor: tensor([[[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.]],
[[1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.]],
[[0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.]]])
进程已结束,退出代码0
# 构建RNN模型
class RNN(nn.Module):
def __init__(self,input_size,hidden_size,output_size,num_layers=1):
super(RNN, self).__init__()
self.hidden_size = hidden_size
self.input_size = input_size
self.output_size = output_size
self.num_layers = num_layers
# 实例化预定义的nn.RNN
# 传入的num_layers,是我传成了output_size
self.rnn = nn.RNN(input_size, hidden_size, num_layers)
# 实例化nn.Linear,这个线性层用于将nn.RNN的输出维度转化为指定的输出维度
self.linear = nn.Linear(hidden_size,output_size)
# 实例化nn中的预定义softmax层,用于从输出层获得类别结果
# 最后一个维度
self.softmax = nn.LogSoftmax(dim = -1)
def forward(self,input1,hidden):
"""
:param input: 代表输入张量,形状是1*n_letters
:param hidden: 代表RNN的隐层张量,形状是self.num_layers * 1 * self.hidden_size
:return:
"""
# 因为预定义的nn.RNN需要输入维度一定是三维的张量,所以这里使用unsqueeze(0)扩展一个维度
input1 = input1.unsqueeze(0)
# 1*1*n_letters
# 将input和hidden 输入到传统RNN的实例对象中,如果num_layers = 1 ,rr恒等于hn
rr,hn = self.rnn(input1,hidden)
return self.softmax(self.linear(rr)),hn
# 初始化一个全零的张量,初始的时候有时候h0并没有值
def initHidden(self):
"""初始化隐层张量"""
# 初始化一个(self.num_layers,1,self.hidden_size)形状的0张量
return torch.zeros(self.num_layers,1,self.hidden_size)
# 构建LSTM模型
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers=1):
super(LSTM, self).__init__()
self.hidden_size = hidden_size
self.input_size = input_size
self.output_size = output_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers)
self.linear = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim = -1)
def forward(self,input1,hidden,c):
input1 = input1.unsqueeze(0)
rr,(hn,c) = self.lstm(input1,(hidden,c))
return self.softmax(self.linear(rr)),hn,c
def initHiddenAndC(self):
c = hidden = torch.zeros(self.num_layers,1,self.hidden_size)
return hidden,c
# 构建GRU模型
class GRU(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers=1):
super(GRU, self).__init__()
self.hidden_size = hidden_size
self.input_size = input_size
self.output_size = output_size
self.num_layers = num_layers
# 还是传入num_layers
self.gru = nn.GRU(input_size, hidden_size, num_layers)
self.linear = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self,input1,hidden):
input1 = input1.unsqueeze(0)
rr,hn = self.gru(input1,hidden)
return self.softmax(self.linear(rr)),hn
def initHidden(self):
return torch.zeros(self.num_layers,1,self.hidden_size)
# 实例化参数
# 晕哟女鬼onehot编码,最后一维的尺寸n_letters
input_size = n_letters
# 定义隐层的最后一维的尺寸大小
n_hidden = 128
# 输出尺寸为语言类别总数n_categories
output_size = n_categories
# num_layers使用默认值,num_layers = 1
# 输入参数
# 我们以一个字母B作为RNN的首次输入,它通过lineToTensor转为张量
# 因此我们的lineToTensor输出是三维张量,而RNN类需要的是二维张量
# 因此需要使用squeeze(0)降低一个维度
input1 = lineToTensor('B').squeeze(0)
# 初始化一个三维的隐层0张量,也就是初始的细胞状态张量
hidden = c = torch.zeros(1,1,n_hidden)
# 调用
rnn = RNN(input_size,n_hidden,output_size)
# hidden = rnn.initHidden()
lstm = LSTM(input_size,n_hidden,output_size)
# hidden1 ,c = lstm.initHiddenAndC()
gru = GRU(input_size,n_hidden,output_size)
# hidden2 = gru.initHidden()
rnn_output,next_hidden = rnn(input1,hidden)
print("rnn:",rnn_output)
print("rnn_shape:",rnn_output.shape)
print("*******************")
lstm_output,next_hidden1,c = lstm(input1,hidden,c)
print("lstmL:",lstm_output)
print("lstm_shape:",lstm_output.shape)
print("*******************")
gru_output,next_hidden2 = gru(input1,hidden)
print("gru:",gru_output)
print("gry_shape:",gru_output.shape)
print("*******************")
D:\soft\Anaconda\envs\py3.9\python.exe D:/soft/pycharm/pythonProject2/exrnn.py
rnn: tensor([[[-2.8857, -2.9751, -2.9336, -2.9368, -2.8812, -2.8717, -2.8076,
-2.8691, -2.8848, -2.8996, -2.9362, -2.9168, -2.9329, -2.9825,
-2.8839, -2.8148, -2.7836, -2.8560]]], grad_fn=<LogSoftmaxBackward>)
rnn_shape: torch.Size([1, 1, 18])
*******************
lstmL: tensor([[[-2.9815, -2.9237, -2.8068, -2.9551, -2.9410, -2.8580, -2.8494,
-2.8283, -2.9247, -2.8943, -2.8933, -2.8106, -2.8922, -2.9442,
-2.8249, -2.9300, -2.9657, -2.8306]]], grad_fn=<LogSoftmaxBackward>)
lstm_shape: torch.Size([1, 1, 18])
*******************
gru: tensor([[[-2.9322, -2.9128, -2.9895, -2.9205, -2.8556, -2.8565, -2.9048,
-2.8533, -2.8799, -2.8864, -2.9474, -2.8793, -2.7914, -2.8412,
-2.9361, -2.8453, -2.8137, -3.0089]]], grad_fn=<LogSoftmaxBackward>)
gry_shape: torch.Size([1, 1, 18])
*******************
进程已结束,退出代码0
一定要注意输入参数是否正确
torch.topk演示
# torch.topk演示
x = torch.arange(1.,6.)
# tensor([1., 2., 3., 4., 5.])
print(x)
# torch.return_types.topk(
# values=tensor([5., 4., 3.]),
# indices=tensor([4, 3, 2]))
print(torch.topk(x,3))
tensor([1., 2., 3., 4., 5.])
torch.return_types.topk(
values=tensor([5., 4., 3.]),
indices=tensor([4, 3, 2]))
# 构建训练函数并进行训练
# 从输出结果中获得指定类别函数:
def categoryFromOutput(output):
# 从输出张量中返回最大的值和索引对象,我们这里主要需要这个索引
# 某tensor某维度中最高或最低的K个值。
# 加入就是值,索引
# 排名第一个的值
top_n,top_i, = output.topk(1)
# top_i对象中去除索引的值
# 一个元素张量可以用x.item()得到元素值,我理解的就是一个是张量,一个是元素。
# 取里面真实的值
category_i = top_i[0].item()
return all_categories[category_i],category_i
# # torch.topk演示
# x = torch.arange(1.,6.)
# # tensor([1., 2., 3., 4., 5.])
# print(x)
# # torch.return_types.topk(
# # values=tensor([5., 4., 3.]),
# # indices=tensor([4, 3, 2]))
# print(torch.topk(x,3))
# 输入参数
output = gru_output
# 调用
category,category_i = categoryFromOutput(output)
print("category:",category)
print("category_i:",category_i)
D:\soft\Anaconda\envs\py3.9\python.exe D:/soft/pycharm/pythonProject2/exrnn.py
category: Scottish
category_i: 15
# 随机产生我们的训练数据
def randomTraniningExample():
# 首先使用random的choice方法从all_categories随机选择一个类别
category = random.choice(all_categories)
# 然后在通过category_lines字典取category类别对应的名字列表
# 然后再在类别所属的字典里面,随机选一个名字
line = random.choice(category_lines[category])
# 有了类别和名字,然后把类别封装成一个tensor,
category_tensor = torch.tensor([all_categories.index(category)],dtype=torch.long)
line_tensor = lineToTensor(line)
return category,line,category_tensor,line_tensor
# 调用
for i in range(10):
category,line,category_tensor,line_tensor = randomTraniningExample()
print('category = ',category,'/ line =',line, '/ category_tensor = ',category_tensor)
print('line_tensor = ',line_tensor)
D:\soft\Anaconda\envs\py3.9\python.exe D:/soft/pycharm/pythonProject2/exrnn.py
category = Arabic / line = Dagher / category_tensor = tensor([0])
category = Arabic / line = Koury / category_tensor = tensor([0])
category = English / line = Izzard / category_tensor = tensor([4])
category = Portuguese / line = Cardozo / category_tensor = tensor([13])
category = Irish / line = Eoin / category_tensor = tensor([8])
category = German / line = Wagner / category_tensor = tensor([6])
category = Polish / line = Nosek / category_tensor = tensor([12])
category = Italian / line = Stilo / category_tensor = tensor([9])
category = Italian / line = Baldini / category_tensor = tensor([9])
category = Greek / line = Papadelias / category_tensor = tensor([7])
line_tensor = tensor([[[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.]],
[[1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.]],
[[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.]],
[[1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.]],
[[0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.]],
[[0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.]],
[[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.]],
[[0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.]],
[[1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.]],
[[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.]]])
进程已结束,退出代码0
torch.add
# torch.add
a = torch.randn(4)
print(a)
b = torch.randn(4,1)
print(b)
print("----------------")
# alpha先去乘以b,之后乘完之后的结果加上到a
print(torch.add(a,b,alpha=10))
D:\soft\Anaconda\envs\py3.9\python.exe D:/soft/pycharm/pythonProject2/exrnn.py
tensor([ 1.2572, 0.0752, 1.3322, -0.2834])
tensor([[ 0.1863],
[ 0.2954],
[-1.3686],
[ 1.2041]])
----------------
tensor([[ 3.1199, 1.9379, 3.1949, 1.5793],
[ 4.2112, 3.0293, 4.2862, 2.6706],
[-12.4285, -13.6104, -12.3535, -13.9691],
[ 13.2986, 12.1167, 13.3737, 11.7581]])
进程已结束,退出代码0
# 构建时间计算函数
def timeSince(since):
# 获得每次打印的训练耗时,since是训练开始时间
# 获得当前时间
now = time.time()
# 获得时间差,就是训练耗时
s = now - since
# 将秒转化为分钟,并取整
# 向下娶个整
m = math.floor(s/60)
# 计算剩下不够凑成1分钟的秒数
s -= m * 60
# 返回指定格式的耗时
return '%dm %ds' %(m,s)
# 输入参数
# 假设开始时间是10min之前
since = time.time() - 10*60
# 调用
period = timeSince(since)
print(period)
D:\soft\Anaconda\envs\py3.9\python.exe D:/soft/pycharm/pythonProject2/exrnn.py
10m 0s
进程已结束,退出代码0
问题:
RuntimeError: Expected hidden[0] size (x, x, x), got(x, x, x)
维度有问题