机器学习—集成学习(ensemble learning)
一、集成学习
集成学习是将多个弱机器学习器结合,构建一个有较强性能的机器学习器的方法,也就是通过构建并合并多个学习器来完成学习任务,其中构成集成学习的弱学习器称为基学习器、基估计器。
1、根据集成学习的各基估计器类型是否相同,可以分为:同质和异质。
同质:指个体学习器全是同一类型。
异质:指个体学习器包含不同类型的学习算法。
2、根据个体学习器的生成方式,将集成学习方法可以分为两类:boosting和bagging
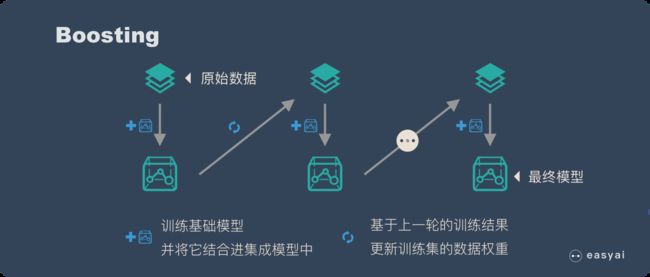
boosting:它的特点是各个弱学习器之间有依赖关系。
bagging:它的特点是各个弱学习器之间没有依赖关系,可以并行拟合。
二、集成学习常用的方法
1、Bagging
(1)Bagging算法流程:
输入为样本集D={(x,y1),(x2,y2),...(xm,ym )} ,弱学习器算法, 弱分类器迭代次数T。
输出为最终的强分类器f(x)
对于t=1,2...,T:
a)对训练集进行第t次随机采样,每个样本被采样的概率为1/m,共采集m次,得到包含m个样本的采样集Dm
b)用采样集Dm训练第m个弱学习器Gm(x)
如果是分类算法预测,则T个弱学习器投出最多票数的类别或者类别之一为最终类别。如果是回归算法,T个弱学习器得到的回归结果进行算术平均得到的值为最终的模型输出。
(2)在scikit-learn中,Bagging方法使用统一的分类元估计器BaggingClassifier或者回归元估计器BaggingRegressor,输入的参数和随机子集抽取策略可指定。其中控制着子集大小(对于样例和特征)的参数为max_samples和max_features,bootstrap和bootstrap_features控制着样例和特征的抽取是有放回还是无放回的。
(3)使用BaggingClassifier()进行集成学习
# SVM
import numpy as np
from sklearn import svm,datasets
import matplotlib.pyplot as plt
from sklearn.ensemble import BaggingClassifier
from sklearn.model_selection import train_test_split
X,y=datasets.make_classification(n_samples=1000,n_features=10,
n_informative=5,n_redundant=2,
n_classes=3,random_state=42)
X_train,X_test,y_train,y_test=train_test_split(X,y,train_size=0.8,random_state=42)
kernel='poly'
clf_svm=svm.SVC(kernel=kernel,gamma=2) # 设置模型参数
clf_svm.fit(X_train,y_train)
y_svm_pred=clf_svm.predict(X_test)
svm_wrong_num=len(y[np.where(y_svm_pred!=y_test)])
print('SVM预测错误的样本数量为:',svm_wrong_num)![]()
# 将支持向量机作为基估计器,使用Bagging进行预测
clf_bagging=BaggingClassifier(svm.SVC(kernel=kernel,gamma=2))
clf_bagging.fit(X_train,y_train)
y_bag_pred=clf_bagging.predict(X_test)
bag_wrong_num=len(y[np.where(y_bag_pred!=y_test)])
print('Bagging预测错误的样本数量为:',bag_wrong_num)![]()
我们从上面可以看到使用支持向量机对测试预测错误的样本数为52,使用Bagging集成学习,将预测错误的样本数量降低到了38,说明Bagging集成学习的分类效果有一定的提高。
2、随机森林
(1)随机森林是Bagging算法的一种改进,它的思想仍是bagging,但进行了独有的改进。
随机森林使用了CART决策树作为弱学习器,这让我们想到了梯度提升树GBDT。第二,在使用决策树的基础上,RF对决策树的建立做了改进,对于普通的决策树,我们会在节点上所有的n个样本特征中选择一个最优的特征来做决策树的左右子树划分,但是RF通过随机选择节点上的一部分样本特征,这个数字小于n,假设为N,然后在这些随机选择的N个样本特征中,选择一个最优的特征来做决策树的左右子树划分,这样进一步增强了模型的泛化能力。
(2)scikit-learn的ensemble模块提供了RandomForestClassifier分类和RandomForestRegression回归两个类。
(3)使用随机森林进行集成学习
import numpy as np
from sklearn import tree,datasets
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
X,y=datasets.make_classification(n_samples=1000,n_features=10,
n_informative=5,n_redundant=2,
n_classes=3,random_state=42)
X_train,X_test,y_train,y_test=train_test_split(X,y,train_size=0.8,random_state=42)
clf_tree=tree.DecisionTreeClassifier(criterion='gini',max_depth=3)
clf_tree.fit(X_train,y_train)
y_tree_pred=clf_tree.predict(X_test)
tree_wrong_num=len(y[np.where(y_tree_pred!=y_test)])
print('决策树预测错误的样本数量为:',tree_wrong_num)![]()
# 随机森林
clf_rfc=RandomForestClassifier(n_estimators=50,criterion='gini',
max_depth=3,random_state=0)
clf_rfc.fit(X_train,y_train)
y_rfc_pred=clf_rfc.predict(X_test)
rfc_wrong_num=len(y[np.where(y_rfc_pred!=y_test)])
print('随机森林预测错误的样本数量为:',rfc_wrong_num)![]() 我们从上面可以知道单个决策树预测错误的样本数是54个,使用随机森林后统计的预测错误样本数量为43个,比单个决策数有所下降,说明随机森林的集成学习对数据集的分类性能有提高。
我们从上面可以知道单个决策树预测错误的样本数是54个,使用随机森林后统计的预测错误样本数量为43个,比单个决策数有所下降,说明随机森林的集成学习对数据集的分类性能有提高。
3、AdaBoost
(1)Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。理论上任何学习器都可以用于Adaboost.但一般来说,使用最广泛的Adaboost弱学习器是决策树和神经网络。对于决策树,Adaboost分类用了CART分类树,而Adaboost回归用了CART回归树。
(2)scikit-learn的ensemble模块提供了AdaBoostClassifier分类和AdaBoostRegression回归。
(3)使用Adaboost进行集成学习
import numpy as np
from sklearn import datasets
from sklearn.ensemble import AdaBoostClassifier
from sklearn.model_selection import train_test_split
X,y=datasets.make_classification(n_samples=1000,n_features=10,
n_informative=5,n_redundant=2,
n_classes=3,random_state=42)
X_train,X_test,y_train,y_test=train_test_split(X,y,train_size=0.8,random_state=42)
adaboost=AdaBoostClassifier(base_estimator=tree.DecisionTreeClassifier(max_depth=3))
adaboost.fit(X_train,y_train)
y_adaboost_pred=adaboost.predict(X_test)
adaboost_wrong_num=len(y[np.where(y_adaboost_pred!=y_test)])
print('adaboost预测错误的样本数量为:',adaboost_wrong_num)![]()
4、梯度树提升(Gradient Tree Boosting,GBDT)
(1)GBDT(Gradient Boosting Decision Tree) 又叫 MART(Multiple Additive Regression Tree),是一种迭代的决策树算法,该算法由多棵决策树组成,所有树的结论累加起来做最终答案。它在被提出之初就和SVM一起被认为是泛化能力较强的算法。
(2)在scikit-learn的ensemble模块中,提供了GBDT的分类GradientBoostingClassifier()和GBDT的回归GradientBoostingRegressor()。两者的参数类型完全相同,但有些参数比如损失函数loss的可选择项是不相同的。
(3)使用GBDT进行集成学习
import numpy as np
from sklearn import datasets
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import train_test_split
X,y=datasets.make_classification(n_samples=1000,n_features=10,
n_informative=5,n_redundant=2,
n_classes=3,random_state=42)
X_train,X_test,y_train,y_test=train_test_split(X,y,train_size=0.8,random_state=42)
gboost=GradientBoostingClassifier()
gboost.fit(X_train,y_train)
print('Gradient Tree Boost分类器对预测集预测的平均准确率为:\n',gboost.score(X_test,y_test))
![]()
5、XGBoost
(1)XGBoost是一个优化的分布式梯度增强库,具有设计高效、灵活、可移植的特点,在梯度增强框架下实现了机器学习算法。
(2)XGBoost为scikit-learn提供了专门的API,但scikit-learn不自带XGBoost,要使用XGBoost,需使用pip命令安装:
pip install xgboost(3)使用XGBoost进行集成学习
from xgboost import XGBClassifier
import xgboost as xgb
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
X,y=datasets.make_classification(n_samples=1000,n_features=10,
n_informative=5,n_redundant=2,
n_classes=3,random_state=42)
X_train,X_test,y_train,y_test=train_test_split(X,y,train_size=0.8,random_state=42)
xgboost=XGBClassifier()
xgboost.fit(X_train,y_train)
y_xgboost_pred=xgboost.predict(X_test)
xgboost_wrong_num=len(y[np.where(y_xgboost_pred!=y_test)])
print('XGBoost分类器对测试集预测错误的样本数量为:',xgboost_wrong_num)![]()
三、实例(数据集digits)
使用scikit-learn的datasets模块自带的数据集digits分别使用Bagging、AdaBoost、XGBoost及GradientBoosting集成学习方法,对其进行分类。
from sklearn.ensemble import BaggingClassifier,RandomForestClassifier
from sklearn.ensemble import AdaBoostClassifier,GradientBoostingClassifier
from xgboost import XGBClassifier
from sklearn import tree,datasets
import numpy as np
from sklearn.model_selection import train_test_split
digits=datasets.load_digits()
X=digits.data
y=digits.target
X_train,X_test,y_train,y_test=train_test_split(X,y,train_size=0.8,random_state=42)
d_tree=tree.DecisionTreeClassifier()
bagging=BaggingClassifier(base_estimator=tree.DecisionTreeClassifier())
r_forest=RandomForestClassifier()
adaboost=AdaBoostClassifier(base_estimator=tree.DecisionTreeClassifier())
gboost=GradientBoostingClassifier()
xgboost=XGBClassifier()
model_name=['Bagging','随机森林','AdaBoost','XGBoost','决策树']
models={bagging,r_forest,adaboost,gboost,xgboost,d_tree}
import time
for name_idx,model in zip([0,1,2,3,4],models):
start=time.perf_counter()
model.fit(X_train,y_train)
end=time.perf_counter()
print(model_name[name_idx],'模型拟合时间为:',end-start)
y_pred=model.predict(X_test)
wrong_pred_num=len(y[np.where(y_pred!=y_test)])
print(model_name[name_idx],'预测错误的样本数量为:',wrong_pred_num)
time.sleep(2)运行结果为:
Bagging 模型拟合时间为: 0.301932599999418
Bagging 预测错误的样本数量为: 10
随机森林 模型拟合时间为: 0.7709702000011021
随机森林 预测错误的样本数量为: 11
AdaBoost 模型拟合时间为: 0.08479459999944083
AdaBoost 预测错误的样本数量为: 57
XGBoost 模型拟合时间为: 0.05042159999902651
XGBoost 预测错误的样本数量为: 54
决策树 模型拟合时间为: 8.682290799999464
决策树 预测错误的样本数量为: 11从结果中可以看出:Bagging的预测错误样本数量最少,随机森林、决策树次之。
从拟合模型所用的时间来看:AdaBoost所用时间最短,但准确率最低,说明AdaBoost不太适合这个数据集digits的分类。