Computer vision for solid waste sorting: A critical review of academic research 机器视觉垃圾分选综述翻译
Computer vision for solid waste sorting: A critical review of academic research
应用于固体废弃物分类的计算机视觉:批判性的Review
Author: Weisheng Lu, Junjie Chen
https://doi.org/10.1016/j.wasman.2022.02.009
Abstract
垃圾分类被强烈建议应用于城市固体废弃物 (MSW) 的管理中(Waste management, 废弃物管理)。计算机视觉 (CV)、机器人技术和其他智能技术越来越多地应用于 MSW 分选中,特别是基于计算机视觉的垃圾分类正在经历前所未有的学术研究爆炸式增长。然而,很少有人关注它的发展历程、现状以及未来的前景和挑战。为了解决知识差距,本文对相关学术研究进行了批判性回顾,重点关注基于 CV 的 MSW 分类。本文介绍并比较了流行的 CV 算法,尤其是它们的技术原理和预测性能。本文还从垃圾来源、任务目标、应用领域和数据集可访问性等方面调查了学术研究成果的分布情况,发现了算法由传统机器学习转向深度学习的趋势,且随着计算能力的提升和算法的改进,CV 对垃圾分类的鲁棒性越来越强。同时学术研究在生活垃圾、商业和机构垃圾、建筑垃圾等不同领域的分布不均。而且,研究人员经常展示一些简化工况下效果和基于人工收集数据的研究。本文鼓励未来的研究工作考虑现实世界场景的复杂性,并在工业垃圾分类实践中测试 CV 算法。本文同时呼吁公开共享废弃物图像的数据集,以供感兴趣的研究人员训练和评估他们的 CV 算法有效性。
1. 引言 Introduction
在过去的几十年里,快速的工业化导致城市固体废弃物 (MSW) 的产生量猛增。例如,在2016年中,全球产生了 20.1 亿吨的 MSW,预计到 2030 年这个数字将激增至 25.9 亿吨 (Kaza 等人,2018) 。 MSW 的定义和组成因情况而异,而本文选择了世界银行在 2012 年的报告 (Hoornweg 和 Bhada-Tata,2012) 中使用的定义,其中 MSW 包含广泛的垃圾产生来源,例如住宅和市政服务 (RM)源、工业源、商业和机构来源(ICI),以及建筑和拆除 (C&D) 活动源。
典型的 MSW 管理周期包括垃圾产生、收集、处理和处置 (Hoornweg 和 Bhada-Tata,2012) 。垃圾分类是 MSW 管理中强烈推荐的一种做法 (Wang 等人,2020a;Xia 等人,2021) 。 “垃圾分类” (waste sorting) 一词通常与其他两个密切相关的术语一起出现:“垃圾分隔” (waste segregation) 和“垃圾分离” (waste separation) 。虽然没有通用、明确的定义,但在垃圾管理领域被广泛认可的是:(a) 垃圾分类主要是指在源头产生时 (如:生活场所、工作场所或建筑工地) 或在收集/倾倒点时,将它们分离为不同的种类 (Christensen 和 Matsufuji,2011) ;(b) “垃圾分类”可与“垃圾分离”互换使用,即,既可以在源头人工实行分类(Wang 等人,2020a),也可以在相对集中的地方分选(Gundupalli 等人,2017b)。在本研究中,我们接受这一传统定义,并使用“垃圾分类”一词来涵盖所有在源头和集中处理设施中的垃圾分类行为。
当垃圾在源头产生时,我们鼓励垃圾产生者根据其类型分类垃圾 (Christensen 和 Matsufuji,2011;Gundupalli 等人,2017b) ,如:上海生活垃圾中的“湿”食物垃圾和“干”可回收物 (Zuo 和 Yan,2019) ,香港建筑垃圾中的惰性和非惰性材料 (Lu 等,2015;Lu 和 Yuan,2021) ,或在公共商业区用于收集不同类型垃圾的分类垃圾箱 (Keramitsoglou 和 Tsagarakis,2018) 。然而,随着垃圾分类法的日益复杂化,居民和监管机构越来越难以区分不同的生活垃圾种类 (Chen 等人,2021) ,而计算机视觉 (CV) 的应用可能有助于在源头或收集时对 MSW 进行分类。有了足够的数据后,训练一个 CV 模型来鉴别各种 MSW 材料是完全可行的,CV 模型可以应用于手机等智能设备,并帮助用户确定其产生的垃圾的类型,以便进行适当的分类。CV 模型甚至可以部署到地面无人车 (UGV) 等机器人平台,从而在建筑内 (Paulraj et al., 2016) 或开放式的建筑工地 (Wang 等人,2020b;Wang 等人,2019b) 工作。
也可以在相对集中的地方进行垃圾的分类。在工厂中,收集到的固体废弃物由传送带运输,以通过一系列机械和机器人的分选 (Faibish 等人,1997;Gundupalli 等人,2017b;Huang 等人,2010;Mattone 等人,2000) 。在这个过程中,常采用的有两类分选方法,即直接分选和间接分选 (Gundupalli 等人,2017b;Huang 等人,2010) :直接分选通过施加重力、磁力或使用人工分选等直接分离废料。与之相对,间接分选首先使用传感器 (例如光学传感器、光谱仪、感应传感器和热成像仪) 来检测特定类型的废料,然后用机械或机器人对检测到的材料进行分选 (Gundupalli et al., 2017b; Huang等人,2010) 。基于 CV 的间接垃圾分类的潜力早已得到广泛认可。例如,Faibish 等人 (1997) 提出了一种具有立体视觉的机器人系统,用于检测和分离纸质物体以进行回收。Mattone等人 (2000) 正式解决移动传送带上的物品分类问题,提供了基于光学设备的解决方案。与高光谱成像 (HSI) 和 X 射线等其他传感技术相比,视觉传感器,例如 CCD (电荷耦合器件) 相机,具有成本效益高、易于维护和适用于各种垃圾的多功能性 (Rahman 等人,2014;Zulkifley 等人,2014) 。虽然传统方法更多地依赖于对昂贵的传感器硬件的巨额投资,但基于 CV 的分类只需要简单安装 RGB 相机,并利用算法的力量就可以对废料进行检测。在这样的垃圾分类系统中,CV作为“眼睛”和“大脑”,用于检测和识别传送带上的垃圾,使机器人能够自主执行分类操作。
尽管前景广阔,但 CV 在 MSW 分选中的作用有限,并且在很长一段时间内都处于研究中相对边缘的部分。开发缓慢的原因是特征的人工提取需要大量的工时,且早期算法的鲁棒性相对较低。令人兴奋的是,随着深度学习 (DL) 的发展,这种情况得到了改善,其中标志性的事件是 AlexNet 在 2012 ImageNet 大规模视觉识别挑战赛 (ILSVRC) 中取得了巨大成功 (Krizhevsky 等人,2012) 。 DL 技术可以通过两个方面解决传统 CV 算法的局限性:首先,借助深度学习在特征提取方面的强大功能,可以避免繁琐的手工提取特征,因为深度学习算法可以从大数据中自动学习不同垃圾种类展示出的视觉特征;其次,垃圾分类算法的鲁棒性可以通过向 DL 模型提供在不同环境中捕获的大量的视觉数据来提高。深度学习的潜在优势推动了相关研究工作的激增,已有关于人工智能在垃圾管理中的应用 (Abdallah等人,2020) 和通用自动化垃圾分类主题 (Gundupalli等人,2017b) 的综述文献。然而,据作者所知,以往还没有研究专门关注于 CV 在垃圾分类中的应用。
本研究旨在对有关将 CV 应用于垃圾分类的发展历程、现状、前景和挑战的学术研究进行全面的文献回顾。主要关注的是对普通数码相机拍摄的 RGB 图像的处理,因为这是最近取得大部分进展的领域,也代表了未来发展的主要趋势。该综述旨在解决以下问题:首先,垃圾分类的主要 CV 算法是什么?深度学习算法与传统算法有何不同,是什么让它们超越其他算法来推动最近的发文热潮?其次,学术研究的现状如何?以前的研究成果如何分布在不同的应用领域和垃圾来源?性能是如何评估的,这些年来它是如何发展的?再者,通过综合回顾,我们可以从以往的研究工作中吸取哪些经验教训?未来我们将预见哪些挑战和问题?
本文其余部分安排如下:在本章的介绍部分之后是第 2 部分,描述材料搜寻、选择和一些初步的分析。第 3 部分详细分析了垃圾分类的 CV 算法,第 4 部分从垃圾来源、任务目标、应用领域和数据集可访问性四个方面分析了研究成果。第 5 部分介绍了 CV 在垃圾分类方面的前景和挑战,第 6 节得出结论。
————精翻到此————
2. 相关文献材料收集 Bibliographic material collection
这篇综述中包含的材料仅限于 1997 年至 2021 年间发表的英文学术文献。我们使用“垃圾分类与计算机视觉”和“垃圾分类与图像识别”两个关键词组合,在 Web of Science (WoS) 平台上搜索相关出版物,因为它们直接反映了审查主题的两个主要主题,即“垃圾分类”和“计算机视觉”。手动筛选搜索结果以排除不相关的论文。适合性检查后,合并剩余记录,共有17篇论文。许多其他研究可能被排除在外,因为最初的搜索仅限于具有两个关键字组合的 WoS 数据库。为了找到遗漏的文献,依次检查了 17 篇论文引用的参考文献,以找到其他涉及该综述主题的文章。这种“滚雪球”方法将文献收藏扩大到 较大的86 篇出版物,其中包括 51 篇期刊文章、32 篇会议论文和 3 篇报告/预印本。扩展的文献收藏不仅包括来自其他著名数据库 (如 Scopus) 的出版物,还包括许多备受推崇的会议论文,特别是在计算机科学领域。
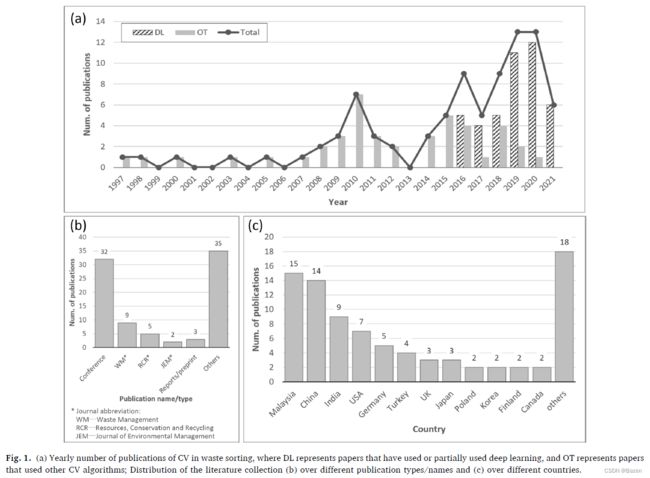
基于收集到的文献,分析了过去二十年研究生产力的演变。如图 1 (a) 所示,自 2016以来,学术研究成果经历了爆炸式增长,当时 AlphaGo 对李世石的历史性胜利进一步向公众推广了 DL 的概念。可以观察到,与 DL 相关的出版物数量呈上升趋势,而使用其他 CV 算法的出版物数量逐渐减少。请注意,2021 年的数字仅考虑了当年 7 月之前发表的文献,也是综述论文起草的时间。
图 1 (b) 和 (c) 显示了按出版物名称/类型和国家划分的文献收藏构成。如图 1 (b) 所示,过去 20 年产量最高的期刊是Waste Management和 Resources, Conservation and Recycling,总共已发表 14论文。如图1 (c) 所示,相关出版物数量排名前三位的国家分别是马来西亚、中国和印度,有趣的是,这些国家都是发展中国家。这可能与这些国家经济快速发展带来的垃圾产生量增加有关 (Bao et al., 2019, 2021) 。
3. 垃圾分类的计算机视觉算法 Computer vision algorithms for waste sorting
许多CV算法已被用于垃圾分类,包括图像预处理 (如去噪、阈值和分割) 、特征提取如尺度不变特征变换 (SIFT) 、定向梯度直方图(HOG) 和主成分分析 (PCA),以及用于分类的机器学习 (ML) 算法。其中,机器学习算法是至关重要的组成部分,因为它直接影响到垃圾分类的准确性和效率。本节总结了流行的机器学习算法的基本原理和应用场景,并比较了它们在识别不同废料方面的性能。请注意,虽然计算时间是性能评估的重要组成部分,但大多数研究并未提及它;因此,准确性在这里被用作主要的评估指标。
3.1 传统 ML 算法
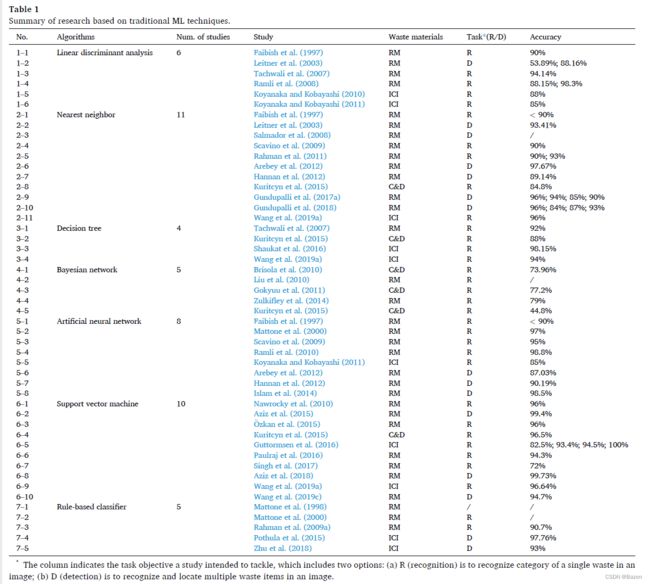
在 DL 出现之前,研究工作试图使用传统的 ML 模型从视觉数据中对不同的废料进行分类。这些模型通常结构简单,缺乏从原始图像中自动提取高级表示的能力;因此,它们需要输入手工设计的特征,例如 HOG 和灰度直方图。表 1 列出了以往研究使用的流行的传统机器学习算法,包括线性判别分析 (LDA)、最近邻 (NN)、决策树 (DT)、贝叶斯网络、人工神经网络 (ANN)、支持向量机 (SVM)、和基于规则的分类器。
3.1.1 线性判别分析 LDA
LDA 是一种常用的线性分类算法。给定一堆数据样本,该算法寻求优化从原始高维特征空间到低维子空间的线性映射,然后可以指定分类器将样本分成不同的类别 (Leitner et al. , 2003)。 LDA起源于Fisher 在 1936年对二分判别分析的研究,现已发展为多种变体和扩展,例如多重判别分析和二次判别分析。如表 1 所示,六篇文章在他们的研究中使用 LDA 作为分类器来识别/检测 RM 和 ICI 垃圾。该算法的预测性能随具体的垃圾类型、任务目标和使用的特征而变化,准确率从低至 53% 到超过 98% 不等。
3.1.2 最近邻 NN
NN 是一种非参数 ML 算法,它不对输入变量和输出类标签之间的映射分布做出强假设 (Brownlee,2016) 。 NN 算法的基本原理很简单:给定一组来自特征空间中不同类别的样本点和一个类别未知的查询点 q,该算法迭代计算 q 在 S 中与所有点之间的距离 (欧几里得或其他距离度量) ,并将 S 中最近点的类标签指定为 q 的类。 NN 算法的一个变体是 k-NN,它着手寻找 k 个最近点,然后通过多数投票决定类标签。基于 NN 的研究数量超过了所有其他传统的 ML 算法。尽管该算法很简单,但它在现有研究中的表现相当不错,其中大多数已经达到了超过 85% 的准确率。
3.1.3. 决策树 DT
DT算法将给定的数据样本 (即训练集) 转换为由节点、分支和叶子组成的树结构的表示。一个节点代表一个特征,一个叶子代表一个类标签;从节点伸出的分支代表对应特征的具体值。 DT 很容易被人类解释和解释 (Tachwali et al., 2007) 。随机森林是 DT 的一种变体算法,旨在解决 DT 对训练集过度拟合的偏好。尽管应用 DT 的研究数量相对较少,但其性能显着,在所有研究中准确率接近或超过 90%。
3.1.4 贝叶斯网络
贝叶斯网络是指利用变量之间因果关系的概率图形模型。在垃圾分类的具体案例中,贝叶斯网络给出了样本属于具有给定视觉特征 (例如颜色) 的垃圾类型的条件概率 (Gokyuu 等人,2011;Liu 等人,2010;Zulkifley 等人, 2014), 形状如面积比和纵横比 (Gokyuu et al., 2011), 纹理如灰度共生矩阵 (GLCM) (Xiao et al., 2020) 和 Jet (Liu et al., 2010)。朴素贝叶斯分类器是贝叶斯网络的一个子集,它假定特征之间具有很强的独立性。该模型主要用于 C&D 和 RM 垃圾分类,结果准确率 <80%。
3.1.5. 人工神经网络 ANN
ANN 通过模仿生物神经网络的结构来学习输入-输出映射 (Abdallah 等人,2020;Guo 等人,2021) 。最早的 ANN 模型之一是单层感知器,它只能学习线性可分离模式。一种更胜任且使用广泛的 ANN 结构是多层感知器 (MLP),它由一个输入层、一个或多个隐藏层和一个输出层组成。通过这种多层结构和非线性激活函数 (例如 sigmoid 和 tanh) 的使用,MLP 可以区分非线性可分的数据。人工神经网络已被用于各种废料的分类,从塑料到汽车行业的金属废料。许多基于人工神经网络的研究实现了超过 95% 的分类准确率。
3.1.6. 支持向量机 SVM
SVM 可以用少量的训练数据产生显着的分类精度。SVM 训练的目标是找到能够最好地分离不同类别的数据样本的最优超平面。最佳超平面是与所有类 (支持向量) 的最近点的距离最大的超平面 (Rogers 和 Girolami,2016) 。尽管 SVM 最初专注于线性二元分类问题,但它已被广泛扩展到通过一对多和核操作的策略来解决非线性超平面的多分类问题。 SVM 是基于 CV 的垃圾分类中的一种流行技术。所获得的性能是显着的:除一项研究外,所有研究都达到了超过 90% 的准确度。
3.1.7. 基于规则的分类器
基于规则的分类器是一种分类模型,它通过遵循一组“如果……那么……”规则来决定给定示例的类别。而在一些研究中 (Pothula 等人,2015;Rahman 等人,2009a;Zhu 等人,2018) ,规则被指定为数值特征与给定阈值的关系 (例如,“如果感兴趣区域的纵横比大小超过阈值,那么它很可能是一个细瓶子”) ,其他人 (Mattone 等,2000;1998) 通过采用模糊技术将数学数字转换为自然语言,根据经验观察制定规则。
3.2 深度学习 DL 算法
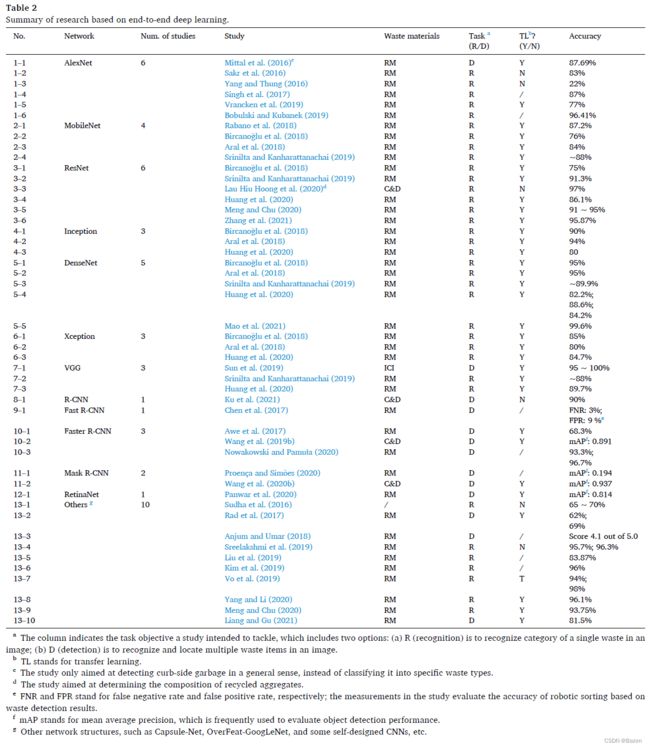
DL通过其深层结构利用大数据的力量来实现所谓的“端到端”训练。在典型的 DL 架构中,原始图像而不是手工制作的特征,直接馈送到由多个卷积层、池化层和全连接层组成的网络,通过该网络可以自动学习和提取图像中的隐藏特征,并最终被使用预测类标签。端到端的学习机制避免了繁琐的特征手工制作过程,从而大大扩展了基于 CV 的垃圾分类的适用性。此外,由于数据集包含广泛的垃圾样本,因此生成的 DL 模型往往比使用传统 ML 算法训练的模型更稳健。卷积神经网络 (CNN) 是一种最先进的 DL 算法,已成功应用于广泛的 CV 相关任务 (Yang et al., 2020, 2021) 。补充材料中的图 S1 显示了 VGG-16 的结构,这是一种著名的 CNN 架构,由 Visual Geometry Group (VGG) 提出,具有 16 个隐藏层。表 2 总结了之前的研究,这些研究根据他们使用的 CNN 架构将 DL 应用于支持 CV 的垃圾分类。
3.2.1. 流行的主干网络
在深度学习中,主干网络是指用于从输入图像中提取特征的 CNN 结构。在骨干网络之上,后续结构可以利用提取的特征来完成各种任务。其中一项任务是垃圾识别,其仅旨在判断给定图像是否属于预定类别之一。在这种情况下,骨干网络通常后面跟着一个全连接层和一个 Softmax 激活层,以输出一个向量,该向量指示输入是某些废料的概率,例如,Mao 等人 (2021)、Yang 和 Thung (2016)、Meng 和 Chu (2020)。通过整合基于补丁的分类或滑动窗口,提取的特征也可以直接用于定位图像上的垃圾 (Anjum 和 Umar,2018;Mittal 等,2016) 。
表 2 中的第 1-X 到第 7-X 行列出了经常用于垃圾分类的骨干网络。基于 AlexNet 和 ResNet 的研究数量超过了所有其他骨干架构。对于 AlexNet,所获得的准确度因情况而异,从对六种常见 MSW 分类的低至 22% (Yang 和 Thung,2016) 到对塑料/纸张的二元分类 (Bobulski 和 Kubanek) 的 96.41% 不等, 2019)。至于 ResNet,除一项研究外,所有研究的分类准确率均高于 85%。不建议直接比较报告中的准确度,因为它们的性能可能已经在不同的数据集上进行了评估,并且某些数据集可能比其他数据集更具挑战性。但是,通过比较基于相同数据集的研究并手动检查相关数据集的难度级别,可以识别出一个通用模式:ResNet、Inception、DenseNet 和 VGG 往往会产生更高的性能。在一般意义上,MobileNet 的表现比其他网络差;然而,该模型需要较少的计算能力,因此可能是实际工业部署中的优选选择。
深度学习模型的训练依赖于海量数据,这些数据在 WM 领域通常难以收集或访问。解决该问题的一种常见做法是使用迁移学习 (TL),该技术利用从源域学习的模型结构和参数,并将它们调整到只需要少量数据来进行参数微调的新域。调整 (Goodfellow 等人,2016) 。该技术已被大多数先前的研究使用。
3.2.2. R-CNN 系列和其他物体检测网络
基于主干提取的特征,可以完成更高级的任务。目标检测就是这样一项任务,其目的不仅在于确定给定图像是否包含感兴趣的目标,还在于使用边界框在图像上定位目标 (Zou 等人,2019 ) 。一些 CV 任务 (例如语义/实例分割) 更进一步提取与目标对应的像素区域 (Garcia-Garcia et al., 2017) 。在工业实践中,垃圾流通常处于高度杂乱的状态,其中不同的材料相互重叠。因此,与垃圾分类相比,垃圾目标检测通过在图像上精确定位垃圾的具体位置,代表了一个更有前景的研究方向。表 2 中的第 8-X 行至第 12-X 行显示了垃圾分类领域中 5 个流行的目标检测网络。
R-CNN (基于区域的卷积神经网络) (Girshick 等人,2014) 使用一种称为“选择性搜索”的算法从原始图像中找到候选区域提议 (RP) 。由于对图像上的所有 RP 重复多次特征提取,R-CNN 在效率方面表现不佳 (Ku 等人,2021) 。基于 R-CNN 开发了一系列算法。 Fast R-CNN 在某种意义上改进了原始 R-CNN,它不是为每个单独的 RP 单独提取特征,而是从输入图像中生成统一的特征图并从特征图中检测候选区域 (Girshick,2015) 。该改进显着减少了处理每个图像所需的时间。在Chen (2017) 的研究中,Fast R-CNN 用于检测和定位传送带上的垃圾,其假阴性率 (FNR) 为 3%,假阳性率 (FPR) 为 9%,计算效率为 0.22 s/图像。Ren等人 (2015) 提出了 Faster R-CNN,其计算时间减少到亚秒级。Awe等人 (2017)、Wang 等人 (2019b) 以及 Nowakowski 和 Pamuła (2020) 分别应用 Faster R-CNN 来检测 RM 垃圾、C&D 垃圾和电子垃圾,达到了预期的性能。 R-CNN 的另一个变体是 Mask R-CNN,与 Faster R-CNN 相比,它有一个额外的分支来提取与检测到的目标的每个单独实例相对应的像素 (Proença 和 Simoes,2020;Wang 等人, 2020b)。
还有另一种称为单阶段检测器的网络流,将目标检测视为单个回归问题,例如 YOLO (You Only Look Once) 、SSD (Single Shot MultiBox Detector) 和 RetinaNet。其中,RetinaNet 超越了 R-CNN 系列等许多两阶段检测器的精度,同时仍保持其在效率上的优势 (Lin et al., 2017) 。Panwar等人 (2020) 基于 RetinaNet 训练了他们的垃圾检测模型,以识别水体中的污染物,平均精度 (mAP) 达到 0.814。 mAP 定义为每个类别的平均精度平均值,是一种流行的目标检测评估指标。也有研究根据垃圾分类的特定领域问题设计了新的 CNN 框架。 Liang 和 Gu (2021) 开发了一种基于 CNN 的多任务学习架构,以便同时对上下文中的垃圾进行分类和定位。该架构集成了注意力机制、多级特征金字塔和联合学习子网络等组件,mAP 达到了 0.815。
3.2.3. 与传统机器学习算法集成
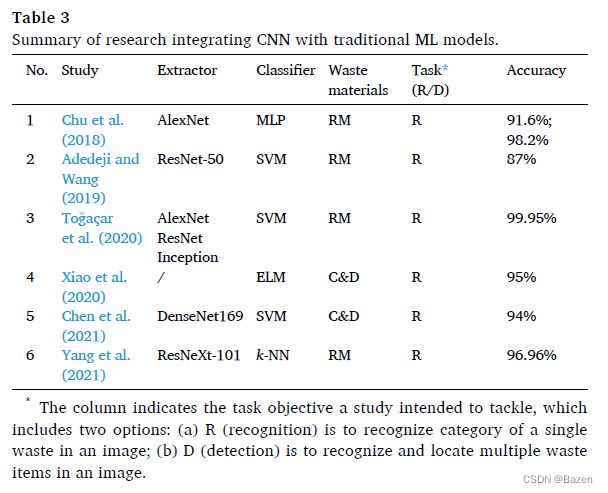
在上述研究中,CNN 模型充当特征提取器和分类器来识别或检测图像中的垃圾。然而,也有研究表明 CNN 仅用于特征提取,而分类是通过 SVM、MLP 和 k-NN 等传统 ML 模型进行的。表 3 提供了这些研究的总结。
CNN 与传统 ML 模型的集成有几个好处:
利用不同的机器学习模型。 CNN 擅长通过其深度网络学习特征,而传统的 ML 算法 SVM 是一种强大的分类工具。通过将两者结合起来,推测可以获得更高的性能。 Adedeji 和 Wang (2019) 采用了这种技术,提取了 ResNet-50 学习到的特征,并使用 SVM 进行垃圾分类。随着CNN的不断完善,这种“CNN+SVM”的优势正在逐渐减弱。因此,这不再是决定是否应采用与传统 ML 集成的主要考虑因素。
灵活融合不同功能。 CNN 和传统 ML 模型的结合使用可以轻松集成由不同网络提取的深层特征 (Togaçar 等人,2020) 或与来自其他模式 (例如重量和磁性) 的传感数据融合 (Chu 等人 , 2018),从而提高了准确性。为了自动化测量 C&D 垃圾成分,Chen 等人 (2021) 开发了一种混合模型,该模型集成了 DenseNet169 网络提取的视觉特征和其他传感器收集的重量和深度等物理特征。将混合特征输入到 SVM 进行垃圾成分分类,从而使准确度提高了 20% 以上。
适应新输入类别的可扩展性。在工业实践中,需要分类的新垃圾类别会动态增加的情况并不少见。在这种情况下,必须重新训练原始 DL 模型,这是一个漫长的过程。为了解决这个问题,Yang 等人 (2021) 采用了“ResNeXt + k-NN”结构。当添加新的垃圾类别时,不需要对 CNN 进行再培训。相反,k-NN 可以根据 ResNeXt 特征的相似性对新类别的样本进行分类。
4. 学术研究成果分析
1997年和2021年的学术研究成果从垃圾来源、任务目标、应用领域和数据集可访问性四个方面进行分析。 图 2 中的饼状图显示了这四个方面的出版物数量分布。
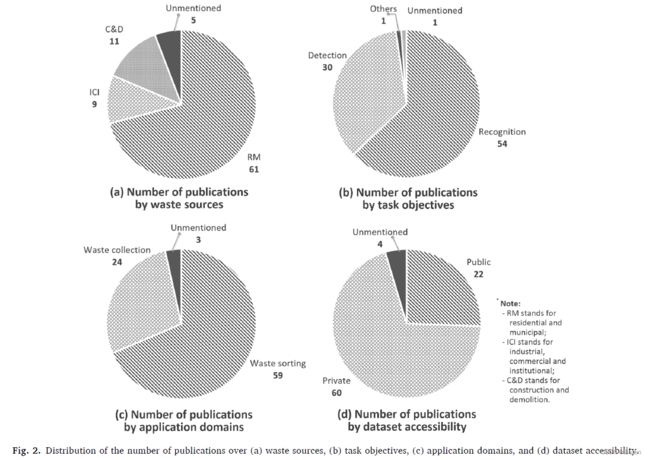
4.1. 垃圾来源
MSW 可以从三个来源产生,即 RM、ICI 和 C&D。图 2 (a) 显示了三个部门的学术产出分布,其中 RM 部门成为论文产出最多的部门,发表论文 (或报告) 61 篇,远远超过 ICI 部门的 9 篇论文和 C&D 部门的 11文件。
4.1.1. 住宅和城市垃圾
出版物数量的显着不平衡意味着主要关注启用 RM 垃圾分类与 CV。为了分离无机垃圾,Salmador 等人 (2008) 开发了一种智能垃圾分类系统,包括网络摄像头视觉、机械臂、用户界面和传送带。该系统的 CV 模块首先采用阈值和分水岭分割来提取垃圾,然后使用傅里叶描述符和矩等手工特征进行分类。Rahman等人 (2011, 2010, 2009a, b) 进行了一系列废纸分类工作,其中共现特征 (Rahman et al., 2009b) 和窗口特征 (Rahman et al., 2010) 与 k-NN 相结合,模板匹配和基于规则的分类器。作为垃圾流中的重要组成部分,利用 CV 促进塑料的分离引起了许多研究人员的关注 (Rahman 等,2009b;Ramli 等,2008;Tachwali 等,2007;Wang 等,2019c ;Zulkifley 等人,2014) 。 ¨Ozkan 等人 (2015) 研究了五种不同的特征提取算法,并将提取的特征馈送到 SVM 进行塑料分类。根据多数投票,该研究的平均准确率为 88%。一些研究人员专注于使用 CV 来区分常见的 RM 垃圾,例如玻璃、纸张、金属、塑料和纸板;此类研究的例子包括 Bobulski 和 Kubanek (2019)、Liu 等人 (2019 年) 和 To˘gaçar 等人 (2020) 。
4.1.2.工业、商业和机构垃圾
研究试图将 CV 应用于国民经济不同部门之间的 ICI 垃圾分类分散,例如核工业 (Shaukat 等人,2016;Sun 等人,2019) 、汽车工业 ( Koyanaka 和 Kobayashi,2010 , 2011 ;Wang 等人,2019a) 以及农业和粮食生产 (Guttormsen 等人,2016;Pothula 等人,2015;Verheyen 等人,2016;Zhu 等人,2018) 。由于核辐射的危险性,自动化机器人在核设施退役后分离核废料的需求量很大。基于视觉的自主识别被认为是此类机器人系统不可或缺的模块。Shaukat等人 (2016) 强调了具有 CMOS (互补金属氧化物半导体) 传感器的无源相机在成本效益和暴露于极端核环境下的可靠性方面优于其他传感器 (例如 X 射线、激光扫描仪和 HSI) 。Sun 等人 (2019) 集成了高斯过程分类 (GPC) 和深度卷积神经网络 (DCNN),以使用有限数量的标记 RGB-D 数据训练核废料检测模型。
在汽车行业,从报废汽车 (ELV) 中回收二次原材料具有经济效益 (Wang 等人,2019a) 。 Koyanaka 和 Kobayashi (2010, 2011) 使用 3D 成像相机系统测量 ELV 金属件的形状参数,然后将其输入判别分析仪和神经网络,用于分选铸铝、锻铝和镁。王等人 (2019a) 开发了一种基于计算机视觉的系统,用于从 ELV 中分离有色金属,其中比较了多种 ML 算法 (例如 SVM、k-NN 和 DT) 的性能。至于农业和食品生产行业,有几项工作专注于对作物和生物质的不同成分进行有效的基于 CV 的分类,以提高可用性 (Pothula 等人,2015;Verheyen 等人,2016;Zhu 等人 , 2018)。
4.1.3. 建筑和拆除垃圾
C&D 垃圾是 MSW 的重要组成部分,在一些城市占到总垃圾流的 40% (Hoornweg 和 BhadaTata,2012) 。传统的基于风选、筛选和人工分选的分选方法效率低下且往往不准确 (Xiao et al., 2020) ;因此,研究人员寻求将 CV 纳入分选线以提高效率和准确性。Lukka 等人 (2014) 和 Kujala 等人 (2015) 提出了一个名为 ZenRobotics Recycler 的机器人系统,用于 C&D 垃圾分类,其中 CV 是解决材料分类和物体抓取问题的重要模块。肖等人 (2020) 开发了一种方法来对五种典型的 C&D 垃圾进行分类,即木材、砖块、橡胶、岩石和混凝土。陈等人 (2022) 提出了一种单目视觉方法来估计运输卡车装载的 C&D 垃圾的成分。颗粒 (Brisola 等,2010) 和聚集体的分类也是 C&D 垃圾回收利用的一项具有挑战性的任务。Lau Hiu Hoong等人 (2020) 利用 CNN 开发了一种 (近乎) 实时的基于 CV 的方法来确定回收骨料的组成。 在王等人 (2020b, 2019b)、Faster RCNN 和 Mask R-CNN 分别在一组显示地面建筑垃圾的图像上进行训练。 训练后的模型在检测散布在建筑工地周围的 C&D 垃圾 (例如,钉子、螺钉和剩余的管道和电缆) 方面取得了很高的性能,然后将这些垃圾用于使机器人原型能够执行垃圾收集。
尽管进行了研究尝试,但利用 CV 来支持 C&D 垃圾分类的利用仍然有限——在超过 20 年的时间里只有 11 篇出版物。 考虑到总垃圾流中的巨大比例 (高达 40%) 的 C&D 垃圾以及对新技术的高需求以实现更好的回收实践,情况似乎更加糟糕和令人费解。
4.2.任务目标
根据他们要完成的任务,现有的研究可以分为两类,即垃圾识别和垃圾检测 (补充材料中的图 S2) 。前者旨在将垃圾图像分类为预定类别之一,而后者不仅识别垃圾类别,而且将它们定位在具有边界框或像素标签的图像上。
4.2.1. 垃圾识别
如图 2 (b) 所示,现有研究的大部分注意力都集中在垃圾识别任务上。在深度学习流行之前,垃圾识别的早期研究要么简化了问题,允许在图像上初步提取垃圾区域 (Nawrocky 等人,2010;Ramli 等人,2008;Tachwali 等人,2007) ,要么假设垃圾传送带上的物料只能一一出现在相机视野中 (Sreelakshmi et al., 2019) 。 Nawrocky 等人 (2010) 假设垃圾物品周围带有边界框的图像很容易获得,并将 SVM 应用于垃圾分类。基于垃圾不相互重叠的假设,Tachwali 等人 (2007) 使用背景减法技术从传送带图像中提取瓶子。
DL 的最新发展使得无需事先进行背景减法即可直接处理图像成为可能。此类作品的主要内容 (Aral 等人,2018;Bircanoglu 等人,2018;Rabano 等人,2018) 源自 Yang 和 Thung (2016) 的 TrashNet 项目。在该项目中,作者将垃圾分类简化为将给定的单个目标图像分类为垃圾类型的问题。大量的研究工作导致在公共数据集 (如 TrashNet) 上的高精度性能 (Yang 和 Thung,2016) 。 Yang 和 Li (2020) 开发了一种用于垃圾分类的轻量级神经网络 WasNet。 WasNet 结合了注意力机制,迫使网络更加关注与垃圾识别相关的敏感区域。通过应用数据增强,WasNet 在 TrashNet 上实现了 96.10% 的分类准确率。
张等人 (2021) 提出了一个带有自我监控模块的残差网络,用于在同一数据集上对可回收垃圾进行分类。通过应用遗传算法进行超参数优化,Mao 等人 (2021) 将 TrashNet 上的分类准确率提高到 99.60%。尽管取得了显着进展,但垃圾识别的性质决定了它在WM行业的应用场景非常有限。首先,由于垃圾识别只能将给定的图像分类到一个预定义的类别中,它不适合机器人的自动化垃圾分类,这不仅需要垃圾类别信息,还需要垃圾的位置和几何形状来指导机器人操作.其次,垃圾识别往往需要在相对简单的背景下出现单个垃圾项目,这在大多数现实生活场景中并非如此,垃圾材料通常在不同的环境中分散甚至相互重叠。基于以上分析,此类垃圾识别技术应主要考虑用于垃圾收集阶段的源头分类,可通过智能手机辅助居民区分不同的生活垃圾 (Srinilta and Kanharattanachai,2019;Yang et al.,2021) ) 或被当局用于向公众征求垃圾收集信息 (Singh 等人,2017;Yang 和 Li,2020) 。
4.2.2.废弃物检测
与同行相比,关注废弃物检测的研究比例仅超过四分之一。在实际工程应用中,同一图像上出现多个垃圾是很常见的。因此,分选操作不仅依赖于确定的类别,还依赖于垃圾的确切位置和几何形状 (Awe 等人,2017;Ku 等人,2021;Lau Hiu Hoong 等人,2020) 。垃圾检测不仅可以识别不同的垃圾类型,还可以识别它们在图像上的位置和几何边界,提供关键信息来推断它们的实际 3D 位置,以便随后用机械臂抓取或分类 (Shaukat 等,2016) 。垃圾检测为解决垃圾分类行业的需求提供了一个有前途的研究方向。
在垃圾分选过程中,大块的废料被随意扔到传送带上,不可避免地导致一些垃圾物品相互杂乱无章。克服这个问题是有效检测单个垃圾的一个具有挑战性的先决条件。王等人 (2019c) 从塑料瓶分类的具体案例谈到了这个问题。该研究整合了形态学操作、凸包分析和凹点计算,以识别“相邻”或“重叠”的垃圾。深度学习技术的发展使得直接训练端到端模型以识别复杂集群环境中的垃圾成为可能 (Awe 等人,2017;Ku 等人,2021;Mittal 等人,2016;Nowakowski 和 Pamuła, 2020;Rad 等人,2017;Sun 等人,2019) 。敬畏等人 (2017) 指出以前基于 TrashNet 的工作 (Yang and Thung, 2016) 只能识别单个目标图像,并强调了从垃圾簇中检测垃圾的重要性。通过微调的 Fast R-CNN,他们实现了 0.683 的 mAP,用于检测纸张等典型 MSW。
近年来,越来越多的研究人员意识到垃圾识别的局限性,并转向垃圾检测问题 (Anjum 和 Umar,2018;Liang 和 Gu,2021;Panwar 等,2020;Proença 和 Simoes, 2020;Wang 等人,2020b;Wang 等人,2019b)。 Proença 和 Simoes (2020) 意识到图像数据集在上下文中的重要性。因此,他们创建了 TACO (Trash Annotation in Context) 数据集,并在该数据集上实现了 Mask R-CNN,作为垃圾检测的基准。同样,Koskinopoulou 等人使用了 Mask RCNN。 (2021) 用于工业场景中的垃圾检测。潘瓦尔等人 (2020) 应用 RetinaNet 检测水体中的垃圾。 Liang and Gu (2021) 发布了一个新的数据集,每个图像中包含边界框注释和多个标签,并开发了一个多任务学习框架,可以高效检测有机、可回收、危险和其他垃圾。
4.3.应用场景
垃圾源头收集和垃圾处理设施分类是前人研究关注的两个应用场景。图 2 (c) 显示了两种情况下的学术出版物分布。
4.3.1. 垃圾源头收集
CV 在垃圾收集阶段的应用旨在从源头识别/检测垃圾目标,为 WM 部门制定收集计划提供信息 (Mittal 等,2016;Nowakowski 和 Pamuła,2020;Yang 和 Li , 2020),使用机器人系统实现初始源分离 (Paulraj et al., 2016; Rad et al., 2017),或协助公民对生活产生的垃圾进行分类 (Srinilta and Kanharattanachai, 2019; Yang et al., 2021) 。 Nowakowski 和 Pamuła (2020) 提出了一个 CNN 分类器来识别智能手机的电子垃圾 (例如冰箱、洗衣机和电视机) ,这可以促进垃圾产生者和收集公司之间的信息交换。Mittal尔等人 (2016) 开发了一款 Android 应用程序 SpotGarbage,用于自动检测和定位不受约束的真实世界图像中的垃圾。Singh 等人 (2017) 开发了一个系统,用于向公众征集有关未收集的路边垃圾的信息,其中使用 CV 来确定上传的信息是否有效。、
另一个值得注意的研究方向是围绕“智能垃圾箱”的开发。这种智能垃圾箱的一个突出特点是它们使用 CV 来检测垃圾箱的水平 (例如,空的、被占用的或已满的) ,然后可以通知市政部门进行垃圾收集 (Abdallah 等人,2020;Aziz 等人) 等人,2018;Islam 等人,2014;Sarc 等人,2019) 。汉南等人 (2012;2016) 和 Aziz 等人 (2015; 2018) 是该领域最具生产力的研究人员之一,并开发了一系列基于灰度光环矩阵、GLCM 和霍夫线检测等特征的 ML 垃圾水平检测方法。一些“智能垃圾箱”研究更进一步,并打算通过集成 CV 和机器人技术来自动隔离垃圾箱中的垃圾 (Jacobsen 等人,2020) 。现有的智能垃圾箱研究大多基于传统的机器学习模型;深度学习的应用及其与以前方法的性能比较的研究还没有很好地建立。
近年来,越来越多的研究关注海洋垃圾,这是一种人为的固体废弃物,被丢弃在海上或通过水道或生活和工业排放口到达大海 (Ribic等,1992) 。海洋垃圾的收集需要有关其类别和位置的信息,这些信息可以通过 CV 技术获得。Fulton等人 (2019) 比较了各种 DL 算法在水下环境中检测垃圾方面的性能,为使用自动水下航行器进行自动垃圾收集铺平了道路。Hong等人 (2020) 提出了一种生成方法来增强水下图像以视觉检测海洋垃圾。除了水下垃圾,一系列研究旨在从遥感图像中识别漂浮或近地表海洋垃圾,例如 Mace (2012)、Taddia 等人 (2021) 和Hu (2021) 。
4.3.2. 处置设施内的垃圾分类
如图 2 (c) 所示,机器人自动化垃圾分类的研究成果 (Chu 等人,2018;Gundupalli 等人,2017a,2018) 远远高于垃圾收集方面的研究成果。在垃圾分类设施中,支持 CV 的垃圾分类系统由硬件和软件组成:前者通常是低成本的摄像头,充当系统的“眼睛”;后者本质上是一堆计算机算法,作为系统的“大脑”,可以识别垃圾。 Gundupalli 等人回顾了自动分选技术。 (2017b) 比较了各种传感技术的性能,并得出结论,基于光学的传感器适用于多种材料,并且可以在很少的时间消耗下达到可接受的精度。
早在 20 世纪末,研究人员就已经概念化了这种使用机器视觉引导机器人进行垃圾分类的系统 (Faibish 等人,1997;Mattone 等人,2000;Mattone 等人,1998) 。早期的 CV 算法通常需要对特定废料进行刻意的特征手工制作,这将它们的适用性限制在非常有限的具有简单特征的废料范围内。此外,手工设计的特征通常不够健壮,无法适应实际分选任务的复杂性。人工智能,尤其是深度学习技术的发展,显着提高了 CV 算法的鲁棒性,并扩大了其适用于包括 RM、ICI 和 C&D 垃圾在内的广泛废料。然而,如前所述,现有的研究大多集中在垃圾识别问题上,这偏离了机器人自动化垃圾分类的最终目标。CV 用于自动垃圾分类的实际部署需要更多的研究工作来解决垃圾检测问题。
4.4. 数据集可访问性
根据其可访问性,现有的垃圾数据集要么是研究人员可以自由访问的“公共”数据集,要么是仅供其所有者使用的“私有”数据集。图 2 (d) 和图 3 (a) 通过数据集的可访问性显示了以前出版物的分布。

4.4.1. 私有数据集
以前的大多数研究都在私有数据集上评估了他们的模型。表 4 列出了两个值得注意的私有数据集的详细信息。在表中,“任务”列表示相应的数据集是用于“垃圾识别 (R) ”还是“垃圾检测 (D) ”。“背景”栏反映了图像背景的复杂程度:“简单”表示背景简单明了,而“背景”表示图像中的垃圾是在随机和复杂的现实生活环境中捕获的。图 3 (b) 展示了过去 20 年私人数据集上垃圾分类准确性的演变。该图呈现出一种波动模式,这与普遍认为同一领域的研究应显示出随时间逐步改进的模式相矛盾。这背后的一个基本问题是使用私有数据集使得难以为有意义的性能比较提供统一的标准和基准。例如,从室外和杂乱的环境中收集的垃圾图像比在控制良好的实验室环境中收集的图像更具挑战性;因此,直接比较从两个数据集训练的模型是没有意义的,因为后者得出的结果可能更好。该问题需要创建和共享公共垃圾数据集。

4.4.2.公共数据集
研究人员收集并公布了几个垃圾数据集。在著名的数据科学和机器学习在线平台 Kaggle 上,数据科学家、ML 工程师和行业从业者也发布了一些有用的数据集。表 5 列出了具有代表性的公共数据集的信息。
使用最广泛的公共数据集是 TrashNet,由 Yang 和 Thung (2016) 收集和公布。该数据集包括六种垃圾类型 (即纸张、玻璃、塑料、金属、纸板和垃圾) 的 2,527 张单目标照片,背景为白色海报板。图 3 (c) 描述了 TrashNet 上的精度演变。可以观察到明显的增长趋势。这表明,通过统一的公开可用数据集,可以集中研究工作以实现持续的性能改进。然而,尽管性能显着 (到 2021 年准确率达到 99.60%) ,但 TrashNet 数据集似乎过于理想化,无法用于实际应用。正如 (Meng and Chu, 2020) 所强调的那样,“在现实中拍摄背景干净的物体是不现实的”。 (Liang and Gu, 2021) 和 (Proença and Simoes, 2020) 也对以前的垃圾图像过于简单表示了类似的担忧。因此,需要具有在现实生活环境中收集的垃圾图像的数据集。 TACO 是朝着这个方向发展的一项显着举措。它包括 1,500 张 RM 垃圾的相关图像,涵盖范围广泛的垃圾 (28 个类别和 60 个子类) ,例如塑料袋、香烟和瓶子 (Proença 和 Simoes,2020) 。该数据集有高质量的边界框注释和像素级垃圾标签,可用于目标检测甚至实例分割。类似的研究重点是 WasteRL (Liang 和 Gu,2021 年) ,其中包括四个 RM 垃圾类别的 57,000 张图像。该数据集可通过相应作者的合理要求获得,因此不被视为表 4 中列出的“公共”数据集。
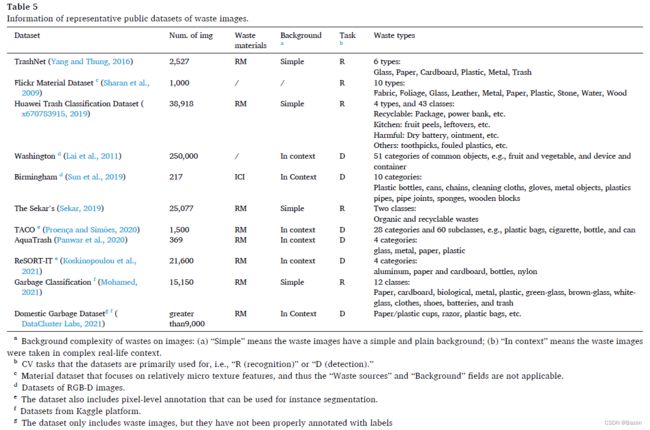
表 5 中的一个值得注意的观察是,除一个公共数据集外,所有数据集都面向 RM 垃圾。这并不奇怪,因为研究工作的主要部分都集中在 RM 垃圾分类上 (图 2 (a)) 。然而,由于其他两种垃圾类型,特别是 C&D 垃圾,也是 MSW 的重要来源,因此应更加关注公共 ICI 或 C&D 垃圾数据集的开发,以促进相关研究。
5. 挑战与前景
5.1.未来的挑战
在盛行 DL 的推动下,CV 在垃圾分类中的应用越来越受到关注。然而,我们的审查从现有研究中发现了多个经验教训,这可能对将当前的学术努力转化为实际应用构成挑战。
首先,目前的研究缺乏面向垃圾分类工业实践的公开可用的真实世界数据集。这导致难以在不同研究之间进行严格比较。大多数现有数据集由各自的研究团队私有。有开放访问的数据集,但它们中的大多数倾向于将工业需求过度简化为垃圾识别问题,垃圾目标出现在简单且控制良好的背景上 (Mohamed,2021;Sekar,2019;x670783915,2019;Yang 和 Thung , 2016)。一些研究已经着手在上下文中收集垃圾图像。然而,它们要么数量有限 (Panwar 等人,2020;Proença 和 Simoes,2020) ,要么缺乏高质量的注释 (DataCluster Labs,2021) 。此外,大部分公共数据集用于对 RM 垃圾进行分类。由于缺乏面向不同 MSW 类型的高质量公共数据集,因此很难基于统一的标准进行有意义的性能评估。这将分散研究工作的注意力,使其偏离不断改进垃圾分类的核心路线。
其次,现有研究或多或少地简化了他们提出的算法的目标或工作条件,这可能对其未来在工业应用中的部署构成挑战。在特定系统边界内的垃圾识别问题之前,例如,假设垃圾只能一件一件地扔到传送带上 (Sreelakshmi 等人,2019 年) ,或者不能与其他人重叠 (Tachwali 等人,2007 年) 。最近与 DL 相关的研究限制了它们从图像中识别单个目标的范围 (Aral 等人,2018;Yang 和 Thung,2016) 。这种具有严格约束的简化可能使开发的方法与实际分选设施中的非结构化环境不兼容,其中垃圾通常随机分布在杂乱的背景中 (Chen et al., 2021; Lu et al., 2022) 。
第三,虽然 C&D 垃圾在 MSW 流中占很大比例,但只有有限的研究致力于将 CV 用于其分类。 C&D 垃圾可占某些城市产生的总垃圾流的 40% (Hoornweg 和 BhadaTata,2012) ;在香港,拆建垃圾占最终填埋的材料的至少四分之一 (香港环保署,2020) 。与大量的 C&D 垃圾相比,有限的研究数量构成了巨大的挑战,这意味着迫切需要更多的研究关注。未能解决这一需求不仅会继续导致可回收的建筑材料不能得到适当的再利用,而且还会导致生产本可以回收的新材料和占用宝贵的土地资源进行垃圾填埋场的一系列环境问题。
第四,尽管 CV 在区分各种材料方面具有多功能性,但基于视觉的方法本质上无法表征垃圾的物理化学性质。具有不同理化性质的材料可以呈现相似的视觉特征。例如,玻璃可能看起来类似于一块透明塑料板,但显然,它们是两种不同类型的材料。在这种情况下,在没有提供其他有用信息的情况下,依靠 CV 来实现有效的分选将是一项挑战。
5.2.前景和未来方向
鉴于上述挑战,对未来基于 CV 的垃圾分类研究提出了几个方向。
针对各种垃圾来源的面向行业的公共数据集。需要具有高质量注释的公开可用数据集来为严格的性能评估提供基准。数据集一方面要面向行业的实际需求,提供真实的照片,另一方面要确保研究社区的自由和开放访问。一些最新的研究已经意识到以前过于简化的数据集的局限性,并努力创建能够捕捉现实变化的数据集,例如 TACO (Proença 和 Simoes,2020) 和 WasteRL (Liang 和 Gu,2021) 。然而,由于这些研究最近才发表,它们的影响仍然相对较低。应加大研究力度,为 ICI 和 C&D 垃圾创建和共享数据集。此类废照片的获取通常由相关部门的利益相关者垄断,因此行业从业者的参与至关重要。虽然一种理想且更可持续的方式是构建一个集中式数据库,其中可以通过众包征集各种垃圾类型及其注释的图像 (PEER,2018) ,但由于一系列法律和版权和保密等管理问题。在可预见的未来,垃圾数据集仍将由不同的各方收集、管理和公布,即通过分散的方式。因此,制定一个通用协议来指导如何构建数据集非常重要。例如,由于不同的国家/地区和部门产生不同类型的垃圾,建议将地理位置 (例如,国家或地理坐标) 和来源 (例如,RM、ICI 或 C&D) 作为注释数据字段或元数据包括在内在构建相关数据集时。
解决工程实践的需要。未来的研究有望更多地关注WM行业遇到的实际问题。例如,从传送带上分选垃圾需要的不仅仅是从单个目标图像中识别垃圾类型。因此,旨在检测和分类多种垃圾的垃圾检测在未来应该引起更多的研究关注。 CV算法的效率也是实际应用中不可缺少的考虑因素。虽然效率在某些场景 (例如智能手机辅助的生活垃圾分类) 中相对不那么重要,但在其他场景 (例如机器人自动垃圾分类) 中需要苛刻的时间性能。当考虑到垃圾回收设施每天可以接收数千吨 MSW 时尤其如此,并且分选速度直接影响整体吞吐量。然而,现有的绝大多数研究都没有报告他们算法的时间性能。建议未来的研究分享推理时间和算法的准确性。请注意,具有不同计算能力的硬件可能会导致相同算法的不同时间性能。因此,还应提及实现相应算法的具体硬件配置,以供读者参考。
用于 C&D 垃圾分类的计算机视觉。作为城市固体废弃物的主要组成部分,提高拆建垃圾分类效率从经济和环境角度来看都是有益的。鉴于 C&D 垃圾的庞大和异质特性,需要更多的研究工作来研究如何将 CV 及其相关算法集成到分选过程中。事实上,在经济利益和最近的技术发展的刺激下,正在发生显着的变化。到 2018,经过审查的研究中只有五项与 C&D 垃圾相关,但自 2019 年以来,在不到三年的时间里,就该主题发表了多达六项研究。增幅达到120%。出版热潮反映了越来越多的研究针对在 C&D 垃圾分类中使用 CV 的趋势。在不久的将来,这种趋势有望持续。
多模态传感数据融合。尽管预计 CV 在垃圾分类中的性能在不久的将来会继续提高,但视觉传感器在传感材料的理化特性方面具有固有的弱点。融合来自不同模式的传感数据 (Chu et al., 2018; Kuritcyn et al., 2015; Tachwali et al., 2007) 可以同时利用视觉传感器的成本效益和其他传感器的能力,例如,重量计、近红外光谱 (NIR) 和感应传感器,用于检测垃圾的理化特性。它可以提高分类精度,提高系统的鲁棒性。然而,新兴的 DL 提出了新的挑战,因为 CNN 提取的特征与物理特征的个位数相比可能达到数十万。因此,建议未来的研究进一步研究 CV 提取的视觉特征如何与来自不同领域的其他特征有效融合。
6. 总结 Conclusions
垃圾分类是实现有效 MSW 管理的关键步骤。 CV 在垃圾分类中的应用已经被概念化并正在研究中超过 20 年。在新兴的深度学习技术的推动下,该领域目前正在经历前所未有的发展。在此背景下,本文对学术研究进行了批判性回顾,以了解基于 CV 的垃圾分类领域的过去、现在和未来。用于垃圾分类的流行 CV 算法可以分为两种类型:传统的 ML 和 DL 算法。传统的 ML 算法需要手工制作的视觉特征作为输入,而 DL 算法可以自动从原始图像中提取隐藏特征。由于其在鲁棒性和自动化端到端训练方面的优势,DL 已成为实现固体废弃物分类的主要 CV 算法。研究发现,学术研究在 RM、ICI 和 C&D 部门之间分布不成比例。虽然现有的研究主要集中在使用 CV 在集中处置设施进行垃圾分类,但也有研究旨在通过机器视觉促进垃圾收集。以前的研究倾向于将他们的研究范围限制在 W. Lu 和 J. Chen简化工作条件 (例如,在实验室环境中使用一小组人工收集的图像) 的垃圾识别任务上.只有少数研究使用公开可用的二级数据集进行模型训练和评估。
批判性审查确定了进一步推广 CV 以进行垃圾分类所面临的几个挑战。其中包括 (a) 缺乏可供感兴趣的研究人员用来训练其模型的全面、可共享的数据集,(b) 过度简化的工作条件导致研究与现实生活实践之间的联系脱节,(c) 对 C&D 浪费的关注较少分类,以及 (d) CV 在区分具有相似外观的材料方面的局限性。未来的研究工作应努力创建和共享面向垃圾来源多样性的行业级数据集。还建议研究人员通过关注垃圾检测问题来适应实际的工业需求,同时同等重视算法的效率。 C&D 垃圾分类和多模式特征融合是另外两个有希望的方向,应该得到更多的关注。