scikit learn工具箱pipeline模块:串联方法
scikit learn工具箱pipeline模块:串联方法
pipeline模块
scikit learn工具箱的pipeline模块提供了将算法模型串联/并联的工具,多个estimator并联起来用于模型结果比较,或者将多个estamitors级联成一个estamitor,比如将特征提取、归一化、分类组织在一起,形成一个典型的机器学习问题工作流。
使用Pipeline的优点在于:
1.直接调用fit和predict方法来对pipeline中的所有算法模型进行训练和预测。
2.可以结合grid search对整个pipeline上estimator的参数进行选择.
3.安全。pipeline可以有效控制transformer和predictor上训练数据的一致性,防止交叉验证时测试数据泄漏给训练好的模型。
scikit learn的pipeline模块提供了以下函数:
- pipeline.FeatureUnion(transformer_list[, …]) 并联拼接多个transformer的结果用于模型比较
- pipeline.Pipeline(steps[, memory]) 串联连接多个estimator,中间的模型可以是transformer,也可以是estimator,但最后一个必须是estimator.
- pipeline.make_pipeline(*steps, **kwargs) 根据给定的estimator列表构造串联Pipeline
- pipeline.make_union(*transformers, **kwargs) 根据给定的transformer构造并联FeatureUnion.
可以看出,上面函数中,Pipeline()和make_pipeline()都是用于构造串联Pipeline的,FeatureUnion()和make_union() 则是构造并联FeatureUnion的。
串联Pipeline的使用
直接加载sklearn工具箱的pipeline方法的Pipeline函数,例如:
from sklearn.pipeline import Pipeline
from sklearn.naive_bayes import GaussianNB
from sklearn.preprocessing import StandardScaler
...
Pipeline(memory=None,
steps=[('standardscaler',
StandardScaler(copy=True, with_mean=True, with_std=True)),
('gaussiannb',
GaussianNB(priors=None, var_smoothing=1e-09))])
Pipeline函数中:
steps 是一个由(key, value)对构建的列表,其中key是包含要给予此步骤的名称的字符串,value是estimator名称。
memory 是可选参数,可以设置为None或者字符串,这里memory参数应该符合joblib的Meory模块接口,这样做可以将模型训练的结果保存到磁盘上,避免重复计算。Memory适合复杂的输入、输出,特别是在non-hashable的数据和大型数组这样的输入输出上。
或者用make_pipeline函数, 上面的代码可以写为:
from sklearn.naive_bayes import GaussianNB
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import make_pipeline
make_pipeline(StandardScaler(), GaussianNB())
在pipeline 中的estimator参数可以通过.steps属性查看。
例1 :pca+svm
以经典的手写数字识别数据为例, 首先用pca方法得到几个最显著的特征,之后用SVM做分类。
from sklearn import svm
from sklearn.datasets import load_digits
from sklearn.decomposition import PCA
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
print(__doc__)
digits = load_digits()
X, y = digits.data, digits.target
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
# 1) take 3 best ranked features
pca = PCA(n_components=3)
# 2) svm
clf = svm.SVC(kernel='linear')
# 3) pipeline
pipe= make_pipeline(pca, clf)
print(pipe.steps[0])
print(pipe.steps[1])
pipe.fit(X_train, y_train)
y_pred = pipe.predict(X_test)
print('anova_svm with only 3 best ranked features')
print('===================================')
print(classification_report(y_test, y_pred))
# 1) pca
pca = PCA(n_components=30)
# 2) svm
clf = svm.SVC(kernel='linear')
# 3) pipeline
pipe = make_pipeline(pca, clf)
print(anova_svm.steps[0])
print(anova_svm.steps[1])
pipe.fit(X_train, y_train)
y_pred = pipe.predict(X_test)
print('anova_svm with only 30 best ranked features')
print('===================================')
print(classification_report(y_test, y_pred))
输出:
Automatically created module for IPython interactive environment
('pca', PCA(copy=True, iterated_power='auto', n_components=3, random_state=None,
svd_solver='auto', tol=0.0, whiten=False))
('svc', SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto', kernel='linear',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False))
anova_svm with only 3 best ranked features
===================================
precision recall f1-score support
0 0.93 0.95 0.94 43
1 0.38 0.59 0.46 37
2 0.67 0.84 0.74 38
3 0.79 0.80 0.80 46
4 0.96 0.93 0.94 55
5 0.50 0.14 0.21 59
6 0.96 0.96 0.96 45
7 0.71 0.78 0.74 41
8 0.41 0.39 0.40 38
9 0.63 0.75 0.69 48
avg / total 0.70 0.70 0.69 450
('selectkbest', SelectKBest(k=10, score_func=))
('svc', SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto', kernel='linear',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False))
anova_svm with only 30 best ranked features
===================================
precision recall f1-score support
0 0.98 1.00 0.99 43
1 0.95 1.00 0.97 37
2 0.97 1.00 0.99 38
3 0.98 0.93 0.96 46
4 1.00 1.00 1.00 55
5 0.97 0.97 0.97 59
6 0.98 0.98 0.98 45
7 1.00 0.98 0.99 41
8 0.95 0.92 0.93 38
9 0.96 0.96 0.96 48
avg / total 0.97 0.97 0.97 450
从上面例子可以看出,pca提取的特征数量对pipeline的分类效果有比较明显的影响,如果调整pca的特征个数参数使得分类效果最佳呢?
可以载入from sklearn.model_selection import GridSearchCV调参工具,例如:
from sklearn import svm
from sklearn.datasets import load_digits
from sklearn.decomposition import PCA
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
print(__doc__)
digits = load_digits()
X, y = digits.data, digits.target
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
pca = PCA()
clf = svm.SVC(kernel='linear')
pipe = Pipeline(steps=[('pca', pca), ('clf', clf)])
# Search for best feature numbers
param_grid = {
'pca__n_components': [3,20,30,40,50,64],
}
search = GridSearchCV(pipe, param_grid, cv=5, return_train_score=False)
search.fit(X_train, y_train)
print("Best parameter (CV score=%0.3f):" % search.best_score_)
print(search.best_params_)
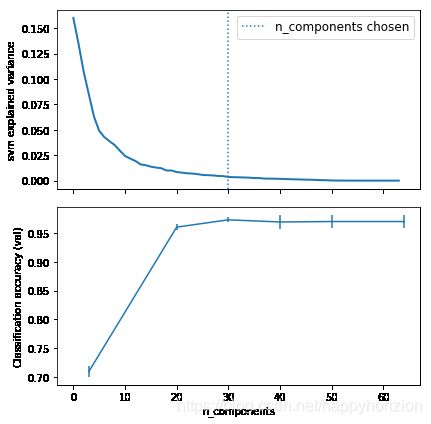
# Plot the svm spectrum
pca.fit(X_test, y_test)
fig, (ax0, ax1) = plt.subplots(nrows=2, sharex=True, figsize=(6, 6))
ax0.plot(pca.explained_variance_ratio_, linewidth=2)
ax0.set_ylabel('svm explained variance')
ax0.axvline(search.best_estimator_.named_steps['pca'].n_components,
linestyle=':', label='n_components chosen')
ax0.legend(prop=dict(size=12))
# For each number of components, find the best classifier results
results = pd.DataFrame(search.cv_results_)
components_col = 'param_pca__n_components'
best_clfs = results.groupby(components_col).apply(
lambda g: g.nlargest(1, 'mean_test_score'))
best_clfs.plot(x=components_col, y='mean_test_score', yerr='std_test_score',
legend=False, ax=ax1)
ax1.set_ylabel('Classification accuracy (val)')
ax1.set_xlabel('n_components')
plt.tight_layout()
plt.show()
y_pred = search.predict(X_test)
print(classification_report(y_test, y_pred))
得到输出:
Automatically created module for IPython interactive environment
Best parameter (CV score=0.973):
{'pca__n_components': 30}
precision recall f1-score support
0 0.98 1.00 0.99 43
1 0.95 1.00 0.97 37
2 0.97 1.00 0.99 38
3 0.98 0.93 0.96 46
4 1.00 1.00 1.00 55
5 0.97 0.97 0.97 59
6 0.98 0.98 0.98 45
7 1.00 0.98 0.99 41
8 0.95 0.92 0.93 38
9 0.96 0.96 0.96 48
avg / total 0.97 0.97 0.97 450
可见,当pca的特征数量为30左右的时候,pca+svm组成的pipeline分类结果最好。pipeline在训练集和测试集上都有97%左右的正确率。
参考
Sklearn中Pipeline的使用:https://blog.csdn.net/qq_41598851/article/details/80957893
Joblib工具箱Memory类:https://blog.csdn.net/donger_soft/article/details/45247201
sklearni中用joblib保存模型:https://blog.csdn.net/mach_learn/article/details/40430469