HRNet:Deep High-Resolution Representation Learning for...(论文解读二十五)
Title: Deep High-Resolution Representation Learning for Human Pose Estimation(HRNet)
Code :PyTorch
From:CVPR 2019
Note data:2020/02/28
Abstract:区别以往的一些方法从高到低分辨率网络产生的低分辨率图像再恢复到高分辨率,HRNet整个过程都保持高分辨率
目录
Abstract
1 Introduction
2 Related Work
3 Method
4 Conclusion
Abstract
论文提出一种基于高分辨率的人体姿态检测模型HRNet;
网络结构:从高分辨率的子网开始,逐渐增加高分辨率到低分辨率的子网,形成多个阶段,讲多分辨率子网并行连接,对多尺度进行融合,融合规则为相同深度高分辨率和低分辨率特征图在中间有互相融合的过程;
创新:区别于以往的模型从高-低-高的过程,模型整个过程是保持高分辨不变,同时将低分辨率信息融合到高分辨率信息中,得到丰富的高分辨率表示;
动机:解决采样过程带来的一些问题。
1 Introduction
DCNNs已经达到了最先进的性能。大多数现有的方法通过网络传递输入,通常由高分辨率到低分辨率的子网串联组成,然后提高分辨率。
本文提出了一种新的架构,即高分辨率网络(HRNet),它能够在整个过程中保持高分辨率的表示。从一个高分辨率的子网作为第一个阶段开始,逐步增加一个高分辨率到低分辨率的子网,形成更多的阶段,并将多分辨率的子网并行连接。通过在并行多分辨率子网中反复交换信息来实现多尺度融合。估计由我们的网络输出的高分辨率表示的关键点。结果网络如图所示。

由上图可以看出网络的结构还是比较清晰的,保证在最高子网的特征图分辨率不变,下面几个子网卷积过程中虽然变小但提取了更多的语义信息再与高分辨率子网融合,更好的表达高分辨率网络达到了很好的结果。
与目前广泛使用的姿态估计网络相比,网络有两个优点。
- 并行连接高分辨率到低分辨率的子网,而不是像大多数现有解决方案那样串联。因此能够保持高分辨率,而不是通过从低到高的过程恢复分辨率,因此预测的热图在空间上可能更精确。
- 大多数现有的融合方案都聚合了低层和高层的表示。相反,通过重复的多尺度融合,利用相同深度和相似水平的低分辨率表征来增强高分辨率表征,反之亦然,因此高分辨率表征也具有丰富的姿态估计功能。因此预测的热图可能更准确。
2 Related Work
许多表现良好的模型都是通过由高到低和由低到高分辨率表示过程来逐渐提高模型性能的。在设计这两个过程中侧重点也不同,与此同时一些工作在从低到高的过程中仅仅采用双线性插值或者转置卷积实现,在一些工作中使用合并扩张卷积消除空间分辨率的损失。
网络并行地连接高到低的子网。它通过整个过程保持高分辨率的表示,以实现空间精确的热图估计。它通过重复融合由高到低的子网络产生的表示来生成可靠的高分辨率表示。不同于大多数现有的工作,它们需要一个单独的从低到高的上采样过程,并聚合低级和高级表示。该方法在不使用中间热图监控的情况下,具有较高的关键点检测精度和较高的计算复杂度及参数效率。
同时论文中也分析了当前存在的一些分类分割模型中出现的多尺度网络出现的问题(至于其合理性在乎作者如何理解吧。。。)
3 Method
设![]() 为
为![]() 阶段的子网,r为分辨率指标(其分辨率为第一子网分辨率的
阶段的子网,r为分辨率指标(其分辨率为第一子网分辨率的![]() )。S(如4)级的高低网络可表示为:
)。S(如4)级的高低网络可表示为:
![]()
并行多分辨率子网:
从一个高分辨率的子网作为第一个阶段开始,逐步增加一个高分辨率到低分辨率的子网,形成新的阶段,并将多分辨率的子网并行连接。因此,后一阶段的并行子网的分辨率由前一阶段的分辨率和一个额外的较低的分辨率组成。给出了一个包含4个子网络的网络结构实例
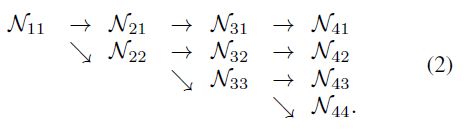
重复多尺度融合:
在并行子网之间引入交换单元,使得每个子网重复地接收来自其他并行子网的信息。下面是一个展示信息交换方案的例子。将第三阶段划分为几个(如3个)交换块,每个交换块由3个并行的卷积单元组成,每个卷积单元之间有一个交换单元,其表达式如下:
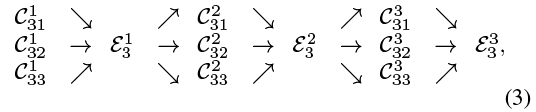
式中![]() 为
为![]() 阶段
阶段![]() 块第
块第![]() 分辨率的卷积单元,
分辨率的卷积单元,![]() 为对应的交换单元。
为对应的交换单元。
输入:![]()
输出响应:![]()
每一个输出是输入的一个聚合,可以用公式: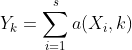
交换单元跨阶段有一个额外的输出映射:![]()
函数![]() 由从分辨率i到分辨率
由从分辨率i到分辨率 的上采样或下采样
的上采样或下采样 组成。例如,1个跨3个卷积与stride 2进行2次降采样,2个连续跨3个卷积与stride 2进行4次降采样。对于上采样,我们采用简单的最近邻采样,然后进行11个卷积来调整通道的数量。如果
组成。例如,1个跨3个卷积与stride 2进行2次降采样,2个连续跨3个卷积与stride 2进行4次降采样。对于上采样,我们采用简单的最近邻采样,然后进行11个卷积来调整通道的数量。如果![]() ,则a(·,·)只是一个标识连接:
,则a(·,·)只是一个标识连接:![]() =。
=。
下图是子网络的交换过程:
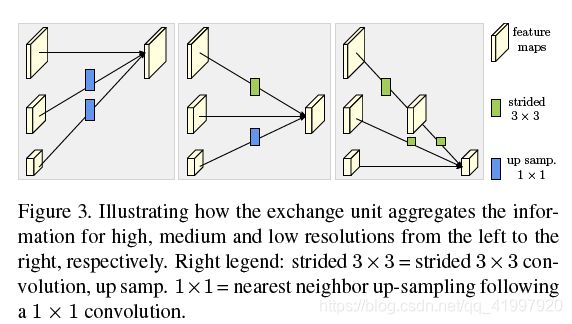
简单地从最后一个交换单元输出的高分辨率表示返回热图,这在经验上运行得很好。损失函数定义为均方误差,用于比较预测的热图和groundtruth热图。groundtruth heatmpas是在每个关键点的grouptruth位置上应用1像素为中心的二维高斯分布生成的。
网络实例化
根据ResNet的设计规则,将深度分配到每个阶段,将通道数目分配到每个分辨率,实例化了关键点热图估计网络。主体HRNet包括四个阶段,四个并行的子网,其分辨率逐渐降低到一半,相应的宽度(通道的数量)增加到原来的两倍。第一阶段包含4剩余单位,每个单位,ResNet-50一样,是由一个瓶颈宽度64,紧随其后的是一个3*3卷积特征图的宽度减少到c,第二,第三,第四阶段包含1、4、3交换块,分别。一个交换块包含4个剩余单元,每个单元包含两个3*3个卷积在每个分辨率中,一个交换单元跨分辨率。综上所述,共有8个交换单位,即,进行8次多尺度融合。
4 Conclusion
在这篇论文中,提出了一种用于人体姿态估计的高分辨率网络,产生了精确和空间精确的关键点热图。成功的原因有两个:(1)整个过程中保持高分辨率,不需要恢复高分辨率;(二)多次融合多分辨率表示,得到可靠的高分辨率表示。未来的工作包括应用于其他密集预测任务,如人脸对齐、目标检测、语义分割,以及以较少的方式聚合多分辨率表示的研究。