注意力机制
文章目录
- 前言
- 文献阅读
-
- 摘要
- 介绍
- 结论
- 二、注意力机制
- 总结
前言
This week,the paper which describe several deep learning models frequently used in solving time series prediction problems has been read. The results show that long - term memory and convolutional neural network are the best choice for TSF. Then I learn about attention mechanism. There are two main questions to think about,for example,that why do we need attention mechanisms and how to figure out weight coefficients and common scoring methods.
本周阅读了文献《An Experimental Review on Deep Learning Architectures》主要讲述了在解决时间序列预测问题时常用到的几种深度学习的模型,并进行分析表明长短时记忆和卷积神经网络在处理TSF问题上是最佳选择。然后学习了注意力机制,为什么要有注意力机制以及怎么求权重系数以及常见的评分方法。
文献阅读
题目:An Experimental Review on Deep Learning Architectures
for Time Series Forecasting
作者:Pedro Lara-Ben´ıtez∗, Manuel Carranza-Garc´ıa and Jos´e C. Riquelme
摘要
近年来,深度学习技术在许多机器学习任务中优于传统模型。深度神经网络已经成功地应用于解决时间序列预测问题,因为它们有能力自动学习时间序列中存在的时间依赖性。然而,选择最方便的深度神经网络类型及其参数化是一项复杂的任务,需要相当多的专业知识。因此,有必要对所有现有架构对不同预测任务的适用性进行更深入的研究。在这项工作中,我们面临着两个主要挑战:全面回顾使用深度学习进行时间序列预测的最新工作和实验研究
比较最流行的体系结构的性能。比较涉及到对七种类型的深度学习模型在准确性和效率方面的深入分析。我们评估了在许多不同的架构配置和训练超参数下所提出的模型所获得的结果的排名和分布。所使用的数据集包括5万多个时间序列,分为12个不同的预测问题。通过在这些数据上训练超过38,000个模型,我们为时间序列预测提供了最广泛的深度学习研究。在所有研究的模型中,结果表明长短期记忆(LSTM)和卷积网络(CNN)是最好的替代方案,LSTM获得了最准确的预测。cnn在不同参数配置下的结果变异性较小,同时效率更高。
介绍
文献包括来自不同TSF领域的研究,考虑所有最流行的DL架构(多层感知器、循环和卷积)。研究了七种类型的深度模型的性能:多层感知器,Elman循环,长短期记忆,回声状态,门控循环
单元,卷积和时间卷积网络工作。为了评估这些模型,我们使用了12个来自不同领域的公开数据集如金融、能源、交通或旅游。我们比较这些模型在精度和效率方面,分析了不同超参数配置下得到的结果的分布。
用于时间序列预测的深度学习框架
时间序列是在固定时间间隔内记录的按时间顺序排列的观察序列。预测问题是指拟合一个模型来通过观察过去的值来预测序列的未来值。设时间序列的历史数据为X = {x1, x2,…,xT } ,H为期望的预测范围,任务是预测该序列的下一个值{xT +1,…,xT +H }.目标是最小化预测误差:
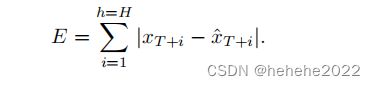
时间序列包括单变量序列和多变量序列,本文只考虑单变量序列分析,即时间顺序记录的单个观测。根据现有文献回顾最相关的DL网络类型,可分为三类:
- 全连接神经网络
----- MLP多层感知机 - 循环神经网络
-----ERNN(Elman循环神经网络);LSTM;ESN回声状态网络
-----GRU - 卷积网络
-----CNN;TCN(时间卷积网络)
多层感知机
MLP是最基本的前馈人工神经网络。架构是由三层结构:输入层、隐藏层和输出层,可以有一个或多个隐藏层。每一层都包含一组定义好的神经元,神经元与可训练的参数有关。研究表明MLP可以解决不同时间序列预测的问题,也证明了预处理步骤的重要性。但它不能捕获时序信息时间序列的顺序,因为它们独立的对待每个输入。
循环神经网络
RNN作为ANN的变体被引入用于时间相关数据。MLP忽略输入数据之间的时间关系时,RNN连将每一个时间步与前一个时间步连接起来,表达了数据的时间依赖性,为RNN提供了对序列数据的原生支持。
通过这个过程,网络不仅学习输入之间的模式,还可以学习序列之间的内部模式。
Elman循环神将网络
ERNN旨在解决处理数据中的时间模式问题。ERNN将前馈隐层改为循环层,循环层将隐层的输出连接到下一个时间步的隐藏层的输入。
长短时记忆网络
LSTM作为解决ERNN问题的一种方法被提出。LSTM能够对时间进行建模在更大范围内的依赖关系,而不会忘记短期模式。LSTM网络与ERNN的不同之处在于隐藏层,即LSTM存储单元,采用乘法输入门控制存储单元。
回声状态网络
回声状态网络(ESN)它们基于储层计算(RC),这简化了传统RNNS的训练过程。以前的RNN,如ERNN或LSTM必须为网络的所有神经元找到最佳值。相反,ESN只是调整输出神经元的权重,使训练问题成为简单的线性回归。
门控循环单元
GRU作为解决ERNN梯度爆炸和梯度消失问题的另一种方法,也可以被视为LSTM单元的简化。在GRU单元中,遗忘器和输入器被组合成一个更新门。GRU单元使用更新门和重置门它将学会决定哪些信息应该保留,不会随时间的推移而消失,以及哪些信息与问题无关。更新门负责决定有多少过去的信息应该传递给未来,而重置门决定有多少过去的信息应该忘记。
卷积神经网络
cnn是一个深度架构家族,最初是为计算机视觉任务设计的。cnn可以自动从具有高维原
始数据中提取特征,而不需要任何特征工程。该模型学习使用卷积操作从原始数据中提取有意义的特征,卷积操作是一个创建特征的滑动过滤器。最近的研究提出了一种更专业的CNN架构,称为时间卷积网络(Temporal Convo lutional Network,简称TCN)。TCN 指的是一种具有特殊特征的CNN:卷积是因果的,以防止信息丢失,架构可以处理任何长度的序列,并将其映射到相同长度的输出。为了便网络能够学习时间序列中存在的长期依赖关系,TCN架构利用了扩张的因果卷积。这种卷积增加了网络的感受野(与滤波器卷积的神经元),而不会失去分辨率,因为不需要池化操作。此外,TCN利用剩余连接来增加网络的深度,这样它就可以有效地处理较大的历史规模。
结论
在12个数据集中,LSTM模型在4个数据集上取得了最好的结果,在其余数据集上,LSTM模型在前3位,但在Tourism中, LSTM模型仅超过MLP排在第6位。此外,GRU似乎是一种非常一致的技术,因为它对大多数数据集都获得了最优预测,在12个数据集中,有10个数据集在前3个架构内。TCN和ERNN 模型在两个数据集上获得了最好的结果,与GRU相似。然而,这两种架构要不稳定得多,根据不同的数据集观察到非常不同的结果。在最佳结果方面,CNN的表现比TCN略差。
二、注意力机制
引进注意力机制的目的?
SEQ2SEQ模型:由编码器和解码器组成,基本思想就是利用两个RNN,一个RNN作为encoder,另一个RNN作为decoder。encoder负责将输入序列压缩成指定长度的向量,这个向量就可以看成是这个序列的语义,这个过程称为编码。而decoder则负责根据语义向量生成指定的序列,这个过程也称为解码.最简单的方式是将encoder得到的语义变量作为初始状态输入到decoder的RNN中,得到输出序列。可以看到上一时刻的输出会作为当前时刻的输入,而且其中语义向量C只作为初始状态参与运算,后面的运算都与语义向量C无关。decoder处理方式还有另外一种,就是语义向量C参与了序列所有时刻的运算,即上一时刻的输出仍然作为当前时刻的输入,但语义向量C会参与所有时刻的运算。

y1=f(c,h1’)
y2=f(c,h2’,y1)
y3=f(c,h3’,y2)
在机器翻译中,c代表整个句子,在翻译前要将句子对一遍进行记忆,存在的问题一是当句子很长时容易遗忘,第二个是对齐问题,不知道翻译的时候y应该对应那个输入(比如I–我,am—是,Chinese—中国人)。那么如何避免遗忘呢?需要存储,存储我们学到的东西。在SEQ2SEQ模型中是将学到的东西输入到下一个单元中,依次最终输入到c中,现在是每个单元对应一个输出,存储学习到的东西,这是编码的过程,还需要解码的过程,怎么用存储的东西来确定c语义向量。比如上面例子说的我是中国人,在翻译“是”(am)的时候,单单看“是”翻译不出来,还要结合“I”才能确定是“am”,每个词对当前的翻译都会产生不同作用即权重系数,用向量进行加权求和,相当于为每一个词分配了一个语义向量,而不是都使用一个语义向量C。
y1=f(c1,h1’)
y2=f(c2,h2’,y1)
y3=f(c3,h3’,y2)
权重系数如何确定?
当前向量Qt与输入句子中每个词向量(hi)的相关程度,关联比较大,那么分配的权重系数值就大,反之分配的小一些.算出Qt与HI的分值ati=score(qt,hi),再做归一化。
如何计算评分呢?
常见的方法有三种:

attention的编码图:

x是输入序列,y是输出序列,hi是编码器第i时刻的隐藏层状态,st是解码器第t时刻的隐藏层状态。最终目标是为了计算条件概率分布p(yt|y1,y2,…,yt-1)=g(yt-1,st,ct)。
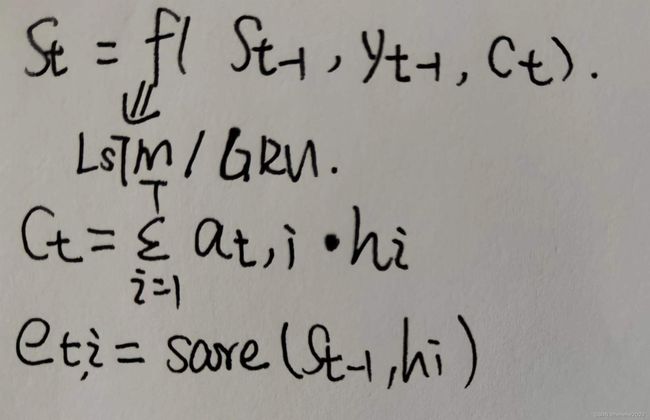
at,i表示解码输出第t个词时,与第i个输入序列词之间的相关因子。
代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
class Attn(nn.Module):
def __init__(self,query_size,key_size,value_size1,value_size2):
super(Attn,self).__init__()
self.query_size = query_size
self.key_size = key_size
self.value_size1 = value_size1
self.value_size2 = value_size2
self.attn = nn.Linear(self.query_size+self.key_size,value_size1)
def forward(self,q,k,v):
# attn_weights=(1,32)
attn_weights = F.softmax(self.attn(torch.concat((q[0],k[0]),1)),dim=1)
# attn_weights.unsqueeze(0)=(1,1,32)
# v=(1,32,64)
# attn_applied=(1,1,64)
output = torch.bmm(attn_weights.unsqueeze(0),v)
return output,attn_weights
总结
注意力机制主要是在seq2seq模型的基础上,我们在编码器和解码器之间增加一个注意力模块。注意力机制可以分为三步:一是信息输入;二是计算注意力分布α;三是根据注意力分布α 来计算输入信息的加权平均。