刘二大人 《PyTorch深度学习实践》第8讲 加载数据集(笔记)
指路☞ 《PyTorch深度学习实践》完结合集_哔哩哔哩_bilibili
目录
一、知识补充
二、课堂代码
三、作业
一、知识补充
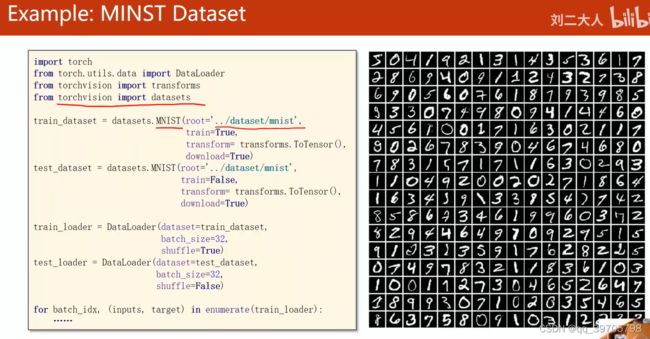
1、Dataset 和 DataLoader是构造数据集的两个类,其中Dataset是构造数据集,支持索引下标,拿出数据集中的一个样本;DataLoader是拿出一个mini-batch一组数据
2、梯度下降用的全部样本,提升计算速度;随机梯度下降用其中一个样本,可以克服鞍点,但时间长。so我们用mini-batch来均衡
3、内层用batch进行迭代,epoch是所有的样本进行前向传播和反向传播,即所有样本都参与训练
lteration: 内层循环迭代了多少次

4、shuffle :打乱顺序;dataset要能提供索引和长度len给dataLoader;batch_size =2 ,所以要分成两个两个一组
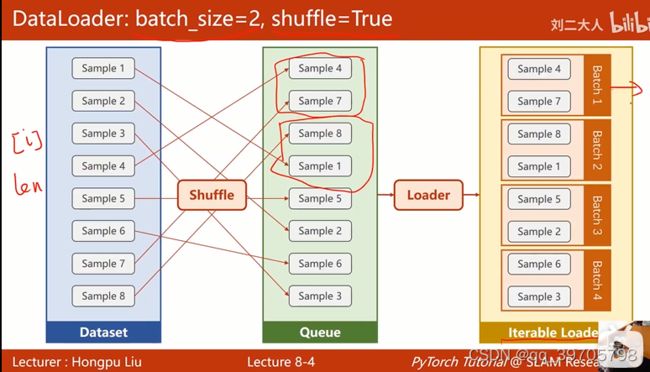
5、Dataset抽象类,不能实例化,只能用子类继承

dataloader可以实例
魔法方法,getitem方法进行下标操作,把其中的一个数据拿出来;len拿出整个数据的数量;


构造数据集两种方法:1,把所有数据加载到init里面,都读到内存里,再用getitem调出第i个元素;数据集本身容量不大
2,如果是图像文件,只在init里面做一些初始化,定义一个列表(文件名),只读文件名,根据文件名加载文件。标签小,可以读到内存里

num_workers= 2,表示2个进程
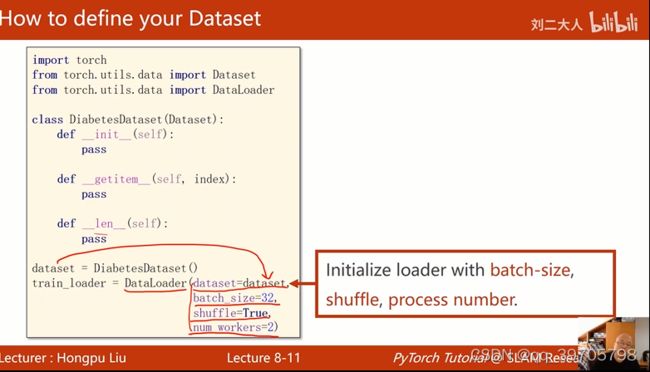
如果直接用dataloader进行训练,会报错,
改写成下面格式

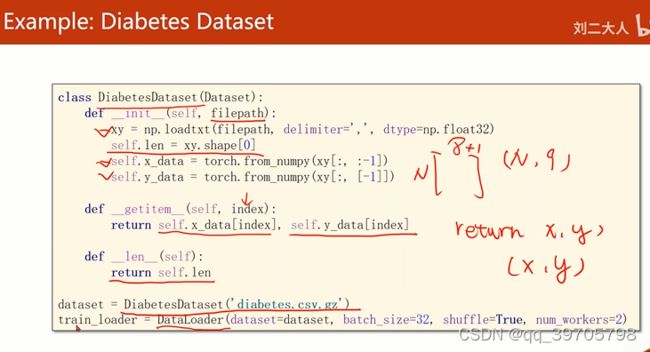
filepath: 文件路径
,是分隔符
self.len = xy.shape[0] ,xy是N行9列,拿到的shape就是(N,9)这个元组,取第0个元素,得到N的值
return self.x_data[index], self.y_data[index]返回一个元组,. 例如 return x,y返回一个元组(x,y)
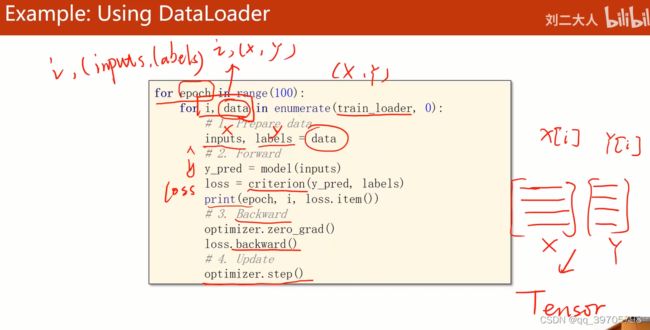
enumerate获得当前第几次迭代,train_loader中的元组放到data里面
inputs是x[i], labels 是y[i] 张量


训练的目标:乘客是否活下来

**************************************************************************************************************
二、课堂代码
import numpy as np
import torch
from torch.utils.data import Dataset, DataLoader
class DiabetesDataset(Dataset):
def __init__(self, filepath):
xy = np.loadtxt(filepath, delimiter=',', dtype = np.float32)
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:, :-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
dataset = DiabetesDataset('diabetes.csv')
train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True)
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
criterion = torch.nn.BCELoss(size_average = True)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
for epoch in range(100):
for i, data in enumerate(train_loader, 0):
inputs, labels =data
y_p = model(inputs)
loss = criterion(y_p, labels)
print(epoch, i, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
部分运行结果:
97 22 0.6825451850891113
97 23 0.5625300407409668
98 0 0.6624407768249512
98 1 0.662903904914856
98 2 0.6621147394180298
98 3 0.642607569694519
98 4 0.5830523371696472
98 5 0.6828585267066956
98 6 0.6623026728630066
98 7 0.7017647624015808
98 8 0.6037701368331909
98 9 0.6427971124649048
98 10 0.6421340703964233
98 11 0.6229970455169678
98 12 0.6818138360977173
98 13 0.6622029542922974
98 14 0.6227084398269653
98 15 0.6621364951133728
98 16 0.6031489372253418
98 17 0.6424006223678589
98 18 0.6431645154953003
98 19 0.5830283761024475
98 20 0.6229612231254578
98 21 0.6422742009162903
98 22 0.6230026483535767
98 23 0.7281836867332458
99 0 0.6027650237083435
99 1 0.5626972913742065
99 2 0.7023857235908508
99 3 0.7615448236465454
99 4 0.58334881067276
99 5 0.6226775646209717
99 6 0.6027751564979553
99 7 0.5433814525604248
99 8 0.6823439598083496
99 9 0.6026230454444885
99 10 0.6425051689147949
99 11 0.7031856775283813
99 12 0.6224838495254517
99 13 0.6230521202087402
99 14 0.6823972463607788
99 15 0.662615954875946
99 16 0.7028822898864746
99 17 0.6229579448699951
99 18 0.7622065544128418
99 19 0.6420165300369263
99 20 0.6223920583724976
99 21 0.6623877882957458
99 22 0.623490035533905
99 23 0.6176818609237671
Process finished with exit code 0**********************************************************************************************************