迁移学习——A Tutorial on Principal Component Analysis
《A Tutorial on Principal Component Analysis》学习
arXiv
文章目录
- 摘要
- 一、介绍
- 二、动机:一个玩具例子
- 三、框架:改变基础
-
- 3.1一个原始的基础
- 3.2基底
- 3.3剩余的问题
- 四、方差和目标
-
- 4.1噪声和旋转
- 4.2冗余
- 4.3协方差矩阵
- 4.4对角化协方差矩阵
- 4.5总结的假设
- 五、用特征向量分解求解主分量
- 六、使用SVD的更通用的解决方案
-
- 6.1奇异值分解
- 6.2解读SVD
- 6.3奇异值分解和主成分分析
- 七、讨论
-
- 7.1降维的极限与统计
- 附录A:线性代数
- 附录B:代码
- Reference
摘要
这个手稿集中在建立一个坚实的直觉如何和为什么主成分分析工作。这手稿结晶这一知识从简单的直觉,背后的数学PCA。本教程不回避非正式地解释思想,也不回避数学。我们希望通过解决这两个方面的问题,各级读者将能够更好地理解PCA,以及何时、如何和为什么应用这种技术。
一、介绍
主成分分析(PCA)是现代数据分析的标准工具——在从神经科学到计算机图形学的不同领域——因为它是一种简单的、非参数的方法,可以从混乱的数据集中提取相关信息。
通过最小的努力,PCA为如何将复杂的数据集减少到更低的维度,以揭示其背后有时隐藏的、简化的结构提供了路线图。
我们将继续增加数学的严密性,把它放在线性代数的框架内,以提供一个显式的解决方案。我们将看到PCA如何以及为什么与奇异值分解(SVD)的数学技术密切相关。
二、动机:一个玩具例子
以图1中物理图中的一个简单玩具问题为例

假设我们正在研究物理学家理想弹簧的运动。这个系统由一个质量为m的球和一个无质量无摩擦的弹簧组成。球在远离平衡的一小段距离被释放(即弹簧被拉伸)。因为弹簧是理想的,它沿着x轴,以固定的频率,围绕平衡无限振荡。
潜在的动力学可以表示为一个单一变量x的函数。
具体来说,我们在我们感兴趣的系统周围放置了三个电影摄像机。在120赫兹的频率下,每个电影摄像机记录一个图像,表明球的二维位置(投影)。
不幸的是,我们甚至不知道真正的x、y和z轴是什么,所以我们选择了三个相机位置 a ~ , b ~ 和 c ~ \tilde a,\tilde b和\tilde c a~,b~和c~,对系统进行任意角度的选择。我们测量的角度甚至可能不是90度!
在玩具的例子中,这意味着我们需要处理空气,不完美的相机,甚至摩擦在一个不太理想的弹簧。噪声污染了我们的数据集,只会进一步混淆动态。这个玩具例子是实验者每天都要面对的挑战。
三、框架:改变基础
主成分分析的目标是找出最有意义的基础来重新表达数据集。我们希望这种新的基础能够过滤掉噪音,揭示隐藏的结构。
3.1一个原始的基础
在我们的数据集中,在某一时刻,摄像机A记录了一个相应的球的位置 ( x A , y A ) (x_A,y_A) (xA,yA)。一个样本或试验可以表示为6维列向量
X ⃗ = [ x A y A x B y B x C y C ] \vec{X}=\begin{bmatrix}x_A\\y_A\\x_B\\y_B\\x_C\\y_C\end{bmatrix} X=⎣ ⎡xAyAxByBxCyC⎦ ⎤
其中,每个摄像机贡献了一个球的位置到整个矢量 X ⃗ \vec{X} X的二维投影。如果我们以120赫兹的频率记录球的位置10分钟,
那么我们就记录了 10 × 60 × 120 = 72000 10× 60 × 120 = 72000 10×60×120=72000个矢量。
我们的原始基础反映了我们测量数据的方法。
我们如何在线性代数中表达这个朴素的基?在二维情况下, { ( 1 , 0 ) , ( 0 , 1 ) } \{(1,0),(0,1)\} {(1,0),(0,1)}可以被重铸为单独的行向量。由这些行向量构成的矩阵是 2 × 2 2 × 2 2×2单位矩阵 I \mathbf I I
我们可以通过构造 m × m m × m m×m单位矩阵来推广到m维的情况
B = [ b 1 b 2 ⋮ b m ] = [ 1 0 ⋯ 0 0 1 ⋯ 0 ⋮ ⋮ ⋱ ⋮ 0 0 ⋯ 1 ] = I \mathbf B=\begin{bmatrix}\mathbf b_1\\\mathbf b_2\\\vdots\\\mathbf b_m\end{bmatrix}=\begin{bmatrix}1&0&\cdots&0\\ 0&1&\cdots&0\\ \vdots&\vdots&\ddots&\vdots\\ 0&0&\cdots&1\end{bmatrix}=\mathbf I B=⎣ ⎡b1b2⋮bm⎦ ⎤=⎣ ⎡10⋮001⋮0⋯⋯⋱⋯00⋮1⎦ ⎤=I
其中每一行是正交基向量 b i \mathbf b_i bi,有m个分量。我们可以把朴素的基础作为有效的起点。我们所有的数据都是在这个基础上记录的,因此它可以简单地表示为 { b i } \{\mathbf b_i\} {bi}的线性组合。
3.2基底
有了这种严谨,我们现在可以更精确地表述PCA所问的问题:是否存在另一种基,即原始基的线性组合,可以最好地重新表达我们的数据集?
事实上,PCA做出了一个严格但强大的假设:线性。线性通过限制潜在基的集合极大地简化了问题。有了这个假设,PCA现在被限制为将数据重新表示为其基向量的线性组合。
设X为原始数据集,其中每一列为我们的数据集(即 X ~ \tilde X X~)的单个样本(或时刻)。在玩具的例子中,X是一个m × n矩阵,其中m = 6, n = 72000。
设Y是另一个与线性变换p相关的m × n矩阵,X是原始记录数据集,Y是该数据集的新表示。
P X = Y (1) \mathbf{PX=Y}\tag{1} PX=Y(1)
让我们定义下面的量。
- p i \mathbf p_i pi是 P \mathbf P P的行
- x i \mathbf x_i xi是 X \mathbf X X的列(或单独的 X ⃗ \vec X X)
- y i \mathbf y_i yi是 Y \mathbf Y Y的列向量。
方程式1表示基的变化,因此可以有多种解释。
- P \mathbf P P是一个将X转换为Y的矩阵。
- 几何上, P \mathbf P P是旋转和拉伸,将 X \mathbf X X再次转换为 Y \mathbf Y Y
- P , { p 1 , … , p m } , \mathbf P, \{\mathbf p_1,…,\mathbf p_m\}, P,{p1,…,pm},是一组新的基向量,用来表示 X \mathbf X X的列。
后一种解释不明显,但可以通过写出 P X \mathbf{PX} PX的显式点积看出。
P X = [ p 1 ⋮ p m ] [ x 1 ⋯ x n ] Y = [ p 1 ⋅ x 1 ⋯ p 1 ⋅ x n ⋮ ⋱ ⋮ p m ⋅ x 1 ⋯ p m ⋅ x n ] \mathbf{PX}=\begin{bmatrix}\mathbf p_1\\\vdots\\\mathbf p_m\end{bmatrix}\begin{bmatrix}\mathbf x_1&\cdots&\mathbf x_n\end{bmatrix}\\ \mathbf Y=\begin{bmatrix}\mathbf p_1\cdot\mathbf x_1&\cdots& \mathbf p_1\cdot\mathbf x_n\\\vdots&\ddots&\vdots\\\mathbf p_m\cdot\mathbf x_1&\cdots&\mathbf p_m\cdot\mathbf x_n\end{bmatrix} PX=⎣ ⎡p1⋮pm⎦ ⎤[x1⋯xn]Y=⎣ ⎡p1⋅x1⋮pm⋅x1⋯⋱⋯p1⋅xn⋮pm⋅xn⎦ ⎤
我们可以记下 Y \mathbf Y Y每一列的形式。
y i = [ p 1 ⋅ x i ⋮ p m ⋅ x i ] \mathbf y_i=\begin{bmatrix}\mathbf p_1\cdot\mathbf x_i\\\vdots\\\mathbf p_m\cdot\mathbf x_i\end{bmatrix} yi=⎣ ⎡p1⋅xi⋮pm⋅xi⎦ ⎤
我们认识到 y i \mathbf y_i yi的每个系数都是 x i \mathbf x_i xi与 p \mathbf p p中相应行的点积。换句话说, y i \mathbf y_i yi的第 j j j个系数是 p \mathbf p p中第 j j j行上的投影。这实际上是一个方程的形式,其中 y i \mathbf y_i yi是对 { p 1 , … , p m } \{\mathbf{p_1},…,\mathbf{p_m}\} {p1,…,pm}。因此, p \mathbf p p的行是一组新的基向量用来表示 X \mathbf X X的列。
3.3剩余的问题
通过假设线性,问题可以简化为寻找适当的基底变换。行向量 { p 1 , … , p m } \{\mathbf{p_1},…,\mathbf{p_m}\} {p1,…,pm}将成为 X \mathbf X X的主要组成部分。现在出现了几个问题。
- 重新表达 X \mathbf X X的最好方式是什么?
- 什么是基底 P \mathbf P P的最佳选择?
这些问题必须通过问自己我们希望Y展示什么特性来回答。显然,要得到一个合理的结果,需要额外的线性假设。
四、方差和目标
现在最重要的问题来了:什么最能表达数据的意思?
4.1噪声和旋转
任何数据集中的测量噪声必须很低,否则无论采用何种分析技术,都无法提取信号的信息。噪声不存在绝对尺度,而是所有的噪声相对于信号强度被量化。常用的度量方法是信噪比(SNR),即方差的 σ 2 \sigma^2 σ2,
S N R = σ s i g n a l 2 σ n o i s e 2 SNR=\frac{\sigma^2_{signal}}{\sigma^2_{noise}} SNR=σnoise2σsignal2
高信噪比 ( ≫ 1 ) (\gg1) (≫1)表示测量精度高,低信噪比表示数据噪声大。
让我们仔细查看图2中摄像机a的数据。

通过假设合理良好的测量,我们定量地假设测量空间中方差最大的方向包含感兴趣的动态。在图2中,方差最大的方向不是 x ^ A = ( 1 , 0 ) \hat x_A =(1,0) x^A=(1,0),也不是 y ^ A = ( 0 , 1 ) \hat y_A =(0,1) y^A=(0,1),而是沿着云的长轴的方向。
因此,通过假设,兴趣动态沿方差最大、信噪比可能最高的方向存在。
最大化方差(并通过假设信噪比)对应于找到朴素基的适当旋转。这种直觉对应于找到图2中 σ 2 σ^2 σ2信号所示的方向。
在图2的二维情况中,最大方差的方向对应于数据云的最佳拟合线。因此,将原始基旋转到与最佳拟合线平行的位置,就可以揭示二维情况下弹簧的运动方向。
4.2冗余
图3可能反映了两个任意测量类型r1和r2之间可能的绘图范围。

图3的右边面板描述了高度相关的记录。这种极端情况可以通过几种方法实现:
- 如果摄像机A和B很近,图是 ( x A , x B ) (x_A,x_B) (xA,xB)
- 一个 ( x A , x ^ A ) (x_A,\hat x_A) (xA,x^A)的图,其中 x A x_A xA是在米中, x ^ A \hat x_A x^A是在英寸中。
很明显,在图3的右侧面板中,只记录单个变量比同时记录两个变量更有意义。为什么?因为可以用最佳拟合直线从 r 2 r_2 r2算出 r 1 r_1 r1(反之亦然)。只记录一个响应可以更简洁地表达数据,减少传感器记录的数量(2→1个变量)。事实上,这就是降维背后的核心思想。
4.3协方差矩阵
在2个变量的情况下,通过找到最佳拟合线的斜率并判断拟合的质量,很容易识别冗余情况。我们如何量化这些概念并将其推广到任意更高的维度?考虑两组均值为零的度量
A = { a 1 , a 2 , … , a n } , B = { b 1 , b 2 , … , b n } A=\{a_1,a_2,\dots,a_n\},B=\{b_1,b_2,\dots,b_n\} A={a1,a2,…,an},B={b1,b2,…,bn}
式中下标为样本数。A、B的方差分别定义为:
σ A 2 = 1 n ∑ i a i 2 , σ B 2 = 1 n ∑ i b i 2 \sigma^2_A=\frac{1}{n}\sum_ia^2_i,\sigma^2_B=\frac{1}{n}\sum_ib^2_i σA2=n1i∑ai2,σB2=n1i∑bi2
A和B之间的协方差是一个简单的泛化。
covariance of A and B ≡ σ A B 2 = 1 n ∑ i a i b i \text{covariance of A and B}\equiv\sigma^2_{AB}=\frac{1}{n}\sum_ia_ib_i covariance of A and B≡σAB2=n1i∑aibi
协方差衡量的是两个变量之间线性关系的程度。较大的正值表示数据正相关。同样,较大的负值表示数据为负相关。协方差的绝对值衡量的是冗余度。还有一些关于协方差的事实。
- σ A B \sigma_{AB} σAB当且仅当A和B不相关时(如:图2,左面板)。
- A = B A = B A=B时, σ A B 2 = σ A 2 \sigma^2_{AB} = \sigma^2_A σAB2=σA2。
我们可以等价地把A和B转换成相应的行向量。
a = [ a 1 a 2 … a n ] b = [ b 1 b 2 … b n ] \mathbf a=[a_1a_2\dots a_n]\\ \mathbf b=[b_1b_2\dots b_n] a=[a1a2…an]b=[b1b2…bn]
这样我们就可以用点积矩阵的计算来表示协方差
σ a b 2 ≡ 1 n a b T (2) \sigma^2_{\mathbf{ab}}\equiv\frac{1}{n}\mathbf{ab}^T\tag{2} σab2≡n1abT(2)
最后,我们可以将两个向量推广到任意数。将行向量 a \mathbf a a和 b \mathbf b b分别重命名为 x 1 \mathbf x_1 x1和 x 2 \mathbf x_2 x2,并考虑额外的索引行向量 x 3 , … , x m \mathbf x_3,…,\mathbf x_m x3,…,xm。
定义一个新的 m × n m × n m×n矩阵 X \mathbf X X。
X = [ x 1 ⋮ x m ] \mathbf X=\begin{bmatrix}\mathbf{x_1}\\\vdots\\\mathbf{x_m}\end{bmatrix} X=⎣ ⎡x1⋮xm⎦ ⎤
对 X \mathbf X X的一种解释如下。
每一行 X \mathbf X X对应于特定类型的所有测量值。 X \mathbf X X的每一列对应一个特定试验的一组测量值(这是3.1节中的 X ⃗ \vec X X)。现在我们得到协方差矩阵 C X \mathbf{C_X} CX的定义。
C X ≡ 1 n X X T \mathbf{C_X}\equiv\frac{1}{n}\mathbf{XX^T} CX≡n1XXT
考虑矩阵 C X = 1 n X X T \mathbf{C_X}=\frac{1}{n}\mathbf{XX^T} CX=n1XXT。 C X \mathbf{C_X} CX的第i j个元素是第i个测量类型的向量与第j个测量类型的向量之间的点积。我们可以总结出 C X \mathbf{C_X} CX的几个性质:
- C X \mathbf{C_X} CX是一个平方对称的 m × m m × m m×m矩阵(附录a的定理2)
- C X \mathbf{C_X} CX的对角线项是特定测量类型的方差。
- C X \mathbf{C_X} CX的非对角线项是测量类型之间的协方差。
C X \mathbf{C_X} CX捕获所有可能的测量对之间的协方差。协方差值反映了我们测量中的噪声和冗余。
- 在对角线项中,通过假设,大的值对应有趣的结构。
- 在非对角线术语中,大的幅度对应高冗余。
假设我们可以操纵 C X \mathbf{C_X} CX。我们将建议定义我们的操作协方差矩阵 C Y \mathbf{C_Y} CY,我们想在 C Y \mathbf{C_Y} CY中优化什么特征?
4.4对角化协方差矩阵
我们可以通过陈述我们的目标(1)最小化冗余(通过协方差的大小衡量)和(2)最大化信号(通过方差衡量)来总结最后两个部分。优化后的协方差矩阵 C Y \mathbf{C_Y} CY是什么样的?
- C Y \mathbf{C_Y} CY中所有非对角线项都应为零。因此, C Y \mathbf{C_Y} CY一定是一个对角矩阵。或者换种说法, Y \mathbf{Y} Y是装饰相关的。
- Y \mathbf{Y} Y中每个连续的维度应该根据方差进行排序。
有许多对角化 C Y \mathbf{C_Y} CY的方法,值得注意的是PCA选择了最简单的方法:PCA假设所有基向量 { p 1 , … , p m } \{\mathbf{p_1},…,\mathbf{p_m}\} {p1,…,pm}是正交的,即 P \mathbf{P} P是一个标准正交矩阵。为什么这个假设最简单?
设想PCA是如何工作的。在图2的简单示例中, P \mathbf{P} P充当广义旋转,使基与最大方差轴对齐。在多个维度上,这可以通过一个简单的算法来实现
- 在m维空间中选择一个 X \mathbf{X} X中方差最大的归一化方向。将这个向量保存为 p 1 \mathbf{p_1} p1。
- 找到另一个方差最大的方向,但是,由于正交条件,限制搜索的所有方向正交于所有之前选择的方向。将这个向量保存为 p i \mathbf{p_i} pi
- 重复这个过程,直到选择m个向量
得到的 p \mathbf{p} p的有序集合是主要成分。
原则上,这个简单的算法是可行的,然而,这与为什么标准正交假设是明智的真正原因不符。这种假设的真正好处是,存在一个有效的分析解决方案来解决这个问题。我们将在以下部分讨论两个解决方案
注意我们用秩序方差的规定得到了什么。我们有一个方法来判断主要方向的重要性。即,与每个方向 p i \mathbf{p_i} pi相关的方差根据相应的方差对每个基向量 p i \mathbf{p_i} pi进行排序,从而量化每个方向的“主”程度。
4.5总结的假设
这一节提供了一个总结的假设背后的PCA和暗示,当这些假设可能表现不佳。
- 线性
线性把问题框定为基的改变。一些研究领域已经探索了如何将这些概念扩展到非线性状态(见讨论)。 - 大的方差具有重要的结构。
这个假设还包含了数据具有高信噪比的信念。因此,相关方差较大的主成分代表有趣的结构,而方差较低的主成分代表噪声。请注意,这是一个强有力的,有时是不正确的假设(参见讨论)。 - 主成分是正交的。
这个假设提供了一个直观的简化,使PCA可以用线性代数分解技术进行分解。以下两部分将重点介绍这些技术。
我们已经讨论了推导PCA的所有方面-剩下的是线性代数解。第一个解决方案有些直接,而第二个解决方案涉及到理解一个重要的代数分解。
五、用特征向量分解求解主分量
基于特征向量分解的一个重要性质,我们得到了主成分分析的第一个代数解。同样,数据集是 X \mathbf X X,一个 m × n m × n m×n的矩阵,其中m为测量类型的数量,n为样本的数量。目标总结如下
求 Y = P X \mathbf Y = \mathbf{PX} Y=PX中的某个标准正交矩阵 P \mathbf P P,使 C Y ≡ 1 n Y Y T \mathbf{C_Y}\equiv\frac{1}{n}\mathbf {YY^T} CY≡n1YYT是一个对角矩阵。 P \mathbf P P的行是 X \mathbf X X的主成分。
我们先把 C Y \mathbf{C_Y} CY写成未知变量的形式。
C Y = 1 n Y Y T = 1 n ( P X ) ( P X ) T = 1 n P X X T P T = P ( 1 n X X T ) P T C Y = P C X P T \mathbf{C_Y}=\frac{1}{n}\mathbf {YY^T}\\ =\frac{1}{n}(\mathbf {PX})(\mathbf {PX})^T\\ =\frac{1}{n}\mathbf{PXX^TP^T}\\ =\mathbf {P}(\frac{1}{n}\mathbf{XX^T})\mathbf P^T\\ \mathbf{C_Y}=\mathbf{PC_XP^T} CY=n1YYT=n1(PX)(PX)T=n1PXXTPT=P(n1XXT)PTCY=PCXPT
注意,我们已经确定了 X \mathbf X X的协方差矩阵在最后一行。
我们的计划是认识到任何对称矩阵 A \mathbf A A是由其特征向量的正交矩阵对角化的(由附录A中的定理3和4)。
对于一个对称矩阵,定理4提供了 A = E D E T \mathbf A = \mathbf {EDE}^T A=EDET,其中 D \mathbf D D是一个对角矩阵, E \mathbf E E是 A \mathbf A A的特征向量作为列排列的矩阵。
现在,关键来了。我们选择矩阵 P \mathbf P P作为一个矩阵其中每一行 p i \mathbf p_i pi是一个特征向量为 1 n X X T \frac{1}{n}\mathbf{XX^T} n1XXT。通过这个选择, P ≡ E T \mathbf P\equiv\mathbf{E^T} P≡ET。利用这个关系和附录 A ( P − 1 = P T ) A (\mathbf P^{−1} =\mathbf P^T) A(P−1=PT)定理1,我们可以完成对 C Y \mathbf {C_Y} CY的求值。
C Y = P C X P T = P ( E T D E ) P T = P ( P T D P ) P T = ( P P T ) D ( P P T ) = ( P P − 1 ) D ( P P − 1 ) C Y = D \begin{aligned} \mathbf {C_Y}&=\mathbf{PC_XP^T}\\ &=\mathbf{P}(\mathbf{E^TDE})\mathbf{P}^T\\ &=\mathbf{P}(\mathbf{P^TDP})\mathbf{P}^T\\ &=(\mathbf{PP^T})\mathbf D(\mathbf{PP^T})\\ &=(\mathbf{PP^{-1}})\mathbf D(\mathbf{PP^{-1}})\\ \mathbf {C_Y}&=\mathbf D \end{aligned} CYCY=PCXPT=P(ETDE)PT=P(PTDP)PT=(PPT)D(PPT)=(PP−1)D(PP−1)=D
很明显, P \mathbf P P的选择对角化了 C Y \mathbf {C_Y} CY,这是PCA的目标。我们可以总结矩阵 P \mathbf P P和 C Y \mathbf {C_Y} CY中主成分分析的结果。
- X \mathbf X X的主分量是 C X = 1 n X X T \mathbf{C_X}=\frac{1}{n}\mathbf {XX^T} CX=n1XXT的特征向量。
- C Y \mathbf {C_Y} CY的第i个对角线值是 X \mathbf X X沿 p i \mathbf p_i pi的方差。
在实践中,计算数据集 X \mathbf X X的主成分分析需要
- 减去每个测量类型的平均值和
- 计算 C X \mathbf {C_X} CX的特征向量。这个解决方案在附录B中包含的Matlab代码中进行了演示
六、使用SVD的更通用的解决方案
我们导出了主成分分析的另一种代数解,在此过程中,发现主成分分析与奇异值分解(SVD)密切相关。事实上,这两者是如此密切相关,以至于这两个名字经常被互换使用。我们将看到的是SVD是理解基的变化的更一般的方法。
6.1奇异值分解
设 X \mathbf X X是一个任意的 n × m n × m n×m矩阵, X T X \mathbf{X^TX} XTX是一个秩 r r r平方对称的 m × m m × m m×m矩阵。
- { v ^ 1 , v ^ 2 , … , v ^ r } \{\hat{\mathbf v}_1,\hat{\mathbf v}_2,…,\hat{\mathbf v}_r\} {v^1,v^2,…,v^r}是标准正交 m × 1 m × 1 m×1特征向量的集合,其特征值为 { λ 1 , λ 2 , … , λ r } \{\lambda_1,\lambda_2,…,\lambda_r\} {λ1,λ2,…,λr}的对称矩阵 X T X \mathbf{X^TX} XTX。
( X T X ) v ^ i = λ i v ^ i (\mathbf X^T\mathbf X)\hat{\mathbf v}_i = \lambda_i\hat{\mathbf v}_i (XTX)v^i=λiv^i - σ i ≡ λ i \sigma_i\equiv\sqrt{\lambda_i} σi≡λi为正实,称为奇异值。
- { u ^ 1 , u ^ 2 , … , u ^ r } \{\hat{\mathbf u}_1,\hat{\mathbf u}_2,…,\hat{\mathbf u}_r\} {u^1,u^2,…,u^r}是 u ^ i ≡ 1 σ i X v ^ i \hat{\mathbf u}_i\equiv\frac{1}{\sigma_i}\mathbf X\hat{\mathbf v}_i u^i≡σi1Xv^i定义的 n × 1 n × 1 n×1向量的集合。
最终的定义包括两个意想不到的新属性。
u ^ i ⋅ u ^ j = { 1 if i = j 0 otherwise \hat{\mathbf{u}}_{\mathbf{i}} \cdot \hat{\mathbf{u}}_{\mathbf{j}}= \begin{cases}1 & \text { if } i=j \\ 0 & \text { otherwise }\end{cases} u^i⋅u^j={10 if i=j otherwise
∥ X v i ^ ∥ = σ i \| \mathbf{X}{\hat{\mathbf { v }_i}} \|=\sigma_{i} ∥Xvi^∥=σi
我们现在有了所有组成分解的部分。标量形式的奇异值分解只是第三个定义的重述。
X v ^ i = σ i u ^ i (3) \mathbf{X\hat{v}_i}=\sigma_i\mathbf{\hat u}_i\tag{3} Xv^i=σiu^i(3)
X \mathbf{X} X乘以一个特征向量 X T X \mathbf{X^TX} XTX等于一个标量乘以另一个向量。
特征向量集合 { v ^ 1 , v ^ 2 , … , v ^ r } \{\mathbf{\hat v}_1,\mathbf{\hat v}_2,…,\mathbf{\hat v}_r\} {v^1,v^2,…,v^r}和向量集 { u ^ 1 , u ^ 2 , … , u ^ r } \{\mathbf{\hat u}_1,\mathbf{\hat u}_2,…,\mathbf{\hat u}_r\} {u^1,u^2,…,u^r}都是r维空间中的标准正交集或基。
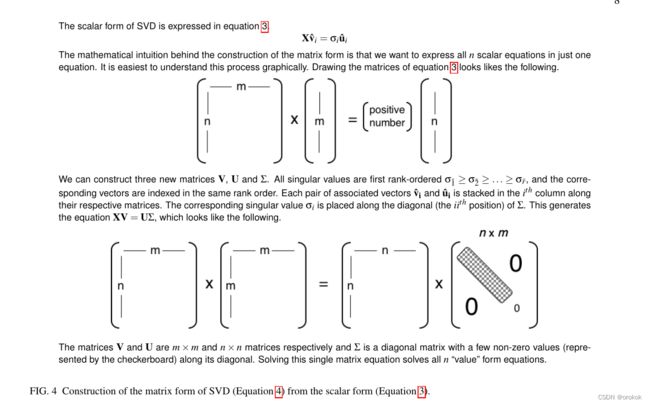
我们可以按照图4中规定的结构,在一次矩阵乘法中总结所有向量的结果。我们首先构造一个新的对角矩阵 Σ \Sigma Σ。

其中 σ 1 ~ ≥ σ 2 ~ ≥ ⋯ ≥ σ r ~ \sigma_{\tilde 1}\ge\sigma_{\tilde 2}\ge\dots\ge\sigma_{\tilde r} σ1~≥σ2~≥⋯≥σr~是奇异值的秩有序集。同样地,我们构造伴随的正交矩阵,
V = [ v ^ 1 ~ v ^ 2 ~ … v ^ m ~ ] U = [ u ^ 1 ~ u ^ 2 ~ … u ^ m ~ ] \mathbf V=[\mathbf{\hat v_{\tilde 1}\hat v_{\tilde 2}\dots\hat v_{\tilde m}}]\\ \mathbf U=[\mathbf{\hat u_{\tilde 1}\hat u_{\tilde 2}\dots\hat u_{\tilde m}}] V=[v^1~v^2~…v^m~]U=[u^1~u^2~…u^m~]
我们已经附加了一个额外的 ( m − r ) (m - r) (m−r)和 ( n − r ) (n - r) (n−r)标准正交向量来分别“填充”矩阵 V \mathbf V V和 U \mathbf U U
图4提供了一个图形表示,说明所有部分如何组合在一起形成SVD的矩阵版本。
X V = U Σ \mathbf{XV}=\mathbf{U\Sigma} XV=UΣ
其中 V \mathbf V V和 U \mathbf U U的每一列执行标量形式的分解(方程3)。
因为V是正交的,我们可以在两边同时乘以 V − 1 = V T \mathbf V^{−1} = \mathbf V^T V−1=VT,从而得到分解的最终形式。
X = U Σ V T (4) \mathbf{X}=\mathbf{U\Sigma V^T}\tag{4} X=UΣVT(4)
虽然没有动机,但这种分解是相当强大的。方程4表明,任意矩阵X可以被转换为正交矩阵、对角矩阵和另一个正交矩阵(或旋转、拉伸和第二次旋转)。
6.2解读SVD
SVD的最后一种形式是简洁而厚重的陈述。让我们把方程3重新解释为
X a = k b \mathbf{Xa}=k\mathbf b Xa=kb
其中 a 和 b \mathbf a和\mathbf b a和b是列向量,k是标量常数。
集合 { v ^ 1 , v ^ 2 , … , v ^ m } \{\mathbf{\hat v}_1,\mathbf{\hat v}_2,…,\mathbf{\hat v}_m\} {v^1,v^2,…,v^m}类似于 a \mathbf a a和集合 { u ^ 1 , u ^ 2 , … , u ^ n } \{\mathbf{\hat u}_1,\mathbf{\hat u}_2,…,\mathbf{\hat u}_n\} {u^1,u^2,…,u^n}类似于 b \mathbf b b。
唯一的是 { v ^ 1 , v ^ 2 , … , v ^ m } \{\mathbf{\hat v}_1,\mathbf{\hat v}_2,…,\mathbf{\hat v}_m\} {v^1,v^2,…,v^m}和 { u ^ 1 , u ^ 2 , … , u ^ n } \{\mathbf{\hat u}_1,\mathbf{\hat u}_2,…,\mathbf{\hat u}_n\} {u^1,u^2,…,u^n}是向量的标准正交集合,它们分别张成m维和n维空间。
我们可以利用方程4使这个模糊的假设更加精确。
X = U Σ V T U T X = Σ V T U T X = Z \begin{aligned} \mathbf{X} &=\mathbf{U} \Sigma \mathbf{V}^{T} \\ \mathbf{U}^{T} \mathbf{X} &=\Sigma \mathbf{V}^{T} \\ \mathbf{U}^{T} \mathbf{X} &=\mathbf{Z} \end{aligned} XUTXUTX=UΣVT=ΣVT=Z
我们已经定义了 Z ≡ Σ V T \mathbf{Z}\equiv\Sigma \mathbf{V}^{T} Z≡ΣVT,注意前面的列 { u ^ 1 , u ^ 2 , … , u ^ n } \{\mathbf{\hat u}_1,\mathbf{\hat u}_2,…,\mathbf{\hat u}_n\} {u^1,u^2,…,u^n}现在是 U T \mathbf{U}^{T} UT中的行。
将此方程与方程1比较, { u ^ 1 , u ^ 2 , … , u ^ n } \{\mathbf{\hat u}_1,\mathbf{\hat u}_2,…,\mathbf{\hat u}_n\} {u^1,u^2,…,u^n}的作用与 { p ^ 1 , p ^ 2 , … , p ^ m } \{\mathbf{\hat p}_1,\mathbf{\hat p}_2,…,\mathbf{\hat p}_m\} {p^1,p^2,…,p^m}相同。
因此, U T \mathbf{U}^{T} UT是从 X \mathbf{X} X到 Z \mathbf{Z} Z的基底变换,就像之前一样,我们在变换列向量,我们可以再次推断我们在变换列向量。
事实上,标准正交基 U T \mathbf{U}^{T} UT(或 P \mathbf{P} P)变换列向量意味着 U T \mathbf{U}^{T} UT是一个张成 X \mathbf{X} X列的基。
跨列的基底被称为 X \mathbf{X} X的列空间。列空间形式化了任何矩阵可能的“输出”的概念。
SVD有一个有趣的对称性,我们可以定义一个类似的量——行空间
V X = Σ U ( X V ) T = ( Σ U ) T V T X T = U T Σ V T X T = Z \begin{aligned} \mathbf{V}\mathbf{X} &= \Sigma \mathbf{U} \\ (\mathbf{X}\mathbf{V})^T&=(\Sigma \mathbf{U})^{T} \\ \mathbf{V}^{T} \mathbf{X}^T &=\mathbf{U}^{T}\Sigma\\ \mathbf{V}^{T} \mathbf{X}^T &=\mathbf{Z} \end{aligned} VX(XV)TVTXTVTXT=ΣU=(ΣU)T=UTΣ=Z
我们已经定义了 Z ≡ U T Σ \mathbf{Z}\equiv\mathbf{U}^{T}\Sigma Z≡UTΣ,同样, V T \mathbf{V}^{T} VT的行(或 V \mathbf{V} V的列)是将 X T \mathbf{X}^T XT转换为 Z \mathbf{Z} Z的标准正交基。因为 X \mathbf{X} X的转置, V \mathbf{V} V是一个跨越 X \mathbf{X} X的行空间的标准正交基。行空间同样形式化了什么是可能的“输入”到一个任意矩阵的概念。
6.3奇异值分解和主成分分析
可见PCA和SVD是密切相关的。让我们回到原始的 m × n m × n m×n数据矩阵 X \mathbf{X} X,我们可以定义一个新的矩阵 Y \mathbf{Y} Y为 n × m n × m n×m矩阵。
Y ≡ 1 n X T \mathbf{Y}\equiv\frac{1}{\sqrt n}\mathbf{X}^T Y≡n1XT
Y \mathbf{Y} Y的每一列均值都是0。通过分析 Y T Y \mathbf{Y^TY} YTY, Y \mathbf{Y} Y的选择变得很清楚。
Y T Y = ( 1 n X T ) T ( 1 n X T ) = 1 n X X T Y T Y = C X \begin{aligned} \mathbf{Y}^{T} \mathbf{Y} &=\left(\frac{1}{\sqrt{n}} \mathbf{X}^{T}\right)^{T}\left(\frac{1}{\sqrt{n}} \mathbf{X}^{T}\right) \\ &=\frac{1}{n} \mathbf{X} \mathbf{X}^{T} \\ \mathbf{Y}^{T} \mathbf{Y} &=\mathbf{C}_{\mathbf{X}} \end{aligned} YTYYTY=(n1XT)T(n1XT)=n1XXT=CX
通过构造 Y T Y \mathbf{Y}^{T}\mathbf{Y} YTY等于 X \mathbf{X} X的协方差矩阵。由第5节可知, X \mathbf{X} X的主成分是 C X \mathbf{C}_{\mathbf{X}} CX的特征向量。
如果我们计算 Y \mathbf{Y} Y的SVD,矩阵 V \mathbf{V} V的列包含 Y T Y = C X \mathbf{Y}^{T}\mathbf{Y}=\mathbf{C}_{\mathbf{X}} YTY=CX的特征向量。
因此, V \mathbf{V} V的列是 X \mathbf{X} X的主分量。
V \mathbf{V} V张成 Y ≡ 1 n X T \mathbf{Y}\equiv\frac{1}{\sqrt n}\mathbf{X}^T Y≡n1XT的行空间。
因此, V \mathbf{V} V也必须张成列空间为 1 n X T \frac{1}{\sqrt n}\mathbf{X}^T n1XT。我们可以得出结论,找到主分量等于找到一个正交基它张成 X \mathbf{X} X的列空间
七、讨论
主成分分析(PCA)利用线性代数的解析解揭示复杂数据集中简单的底层结构,因此具有广泛的应用前景。
图5提供了实现PCA的简要摘要。

在弹簧的例子中,PCA识别出大部分的变化存在于单个维度(运动方向 x ^ \mathbf{\hat x} x^),尽管记录了6个维度。
PCA是完全非参数的:任何数据集都可以插入,得到一个答案,不需要调整参数,也不考虑数据是如何记录的。
从一个角度来看,PCA是非参数化(即插即用)的事实可以被认为是一个积极的特征,因为答案是唯一的,独立于用户。
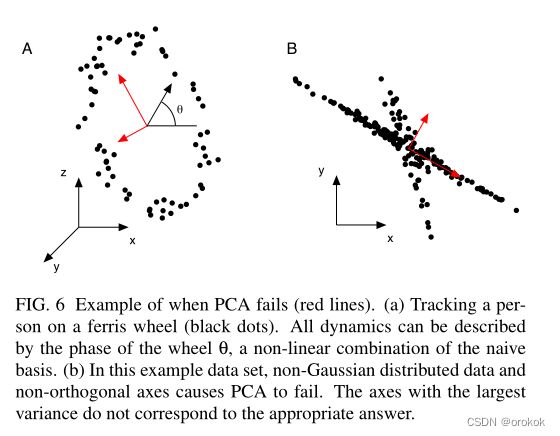
从另一个角度来看,PCA对数据的来源是不可知的这一事实也是一个弱点。例如,考虑在图6a中跟踪一个坐在摩天轮上的人。用车轮进动角 θ θ θ这一单一变量可以清晰地描述数据点,但主成分分析无法恢复这一变量。
7.1降维的极限与统计
更深层次的鉴赏PCA的限制需要考虑一些潜在的假设,在串联,更严格的描述的数据来源。一般来说,这种方法背后的主要动机是去关联数据集,即去除二阶依赖性。
PCA要求探索的每条新道路都必须与前一条道路垂直,但显然这一要求过于严格,数据(或城镇)可能会沿非正交轴线排列,如图6b。图6提供了这类数据的两个示例,其中PCA提供了不满意的结果。
在维数减少的情况下,衡量成功的一个标准是减少的表示在多大程度上可以预测原始数据。
在统计术语中,我们必须定义一个误差函数(或损失函数)。
可以证明,在一个共同的损失函数,均方误差(即L2范数)下,PCA提供了数据的最优简化表示。
这意味着选择主成分的正交方向是预测原始数据的最佳方案。
对于图6的示例,这种说法怎么可能是正确的呢?我们从图6中得到的直觉表明,这个结果在某种程度上是有误导性的。
这个悖论的解决方案就在于我们所选择的分析目标。分析的目标是去关联数据,或者换句话说,目标是消除数据中的二阶依赖关系。
在图6的数据集中,变量之间存在更高阶的依赖关系。因此,在揭示数据的所有结构时,去除二阶依赖关系是不够的。
存在多种消除高阶依赖关系的解决方案。
例如,在图6a中,可以检查数据的极坐标表示。这种参数化方法通常被称为核PCA。
另一个方向是对数据集中的依赖性进行更通用的统计定义,例如,要求减少维度的数据在统计上是独立的。这类算法,称为独立成分分析(ICA),已被证明在许多领域成功的PCA失败。
附录A:线性代数
附录B:代码
Reference
A Tutorial on Principal Component Analysis