ATSS论文阅读笔记
ATSS论文阅读笔记
论文名称:Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection
论文链接:https://arxiv.org/abs/1912.02424
代码地址:https://github.com/sfzhang15/ATSS.
摘要
1、Anchor-based方法和Anchor-free的方法最重要的差异就是在如何定义正负训练样本;
2、ATSS(Adaptive Training Sample Selection)根据目标的统计分布自动选择正负样本,可以明显地缩短anchor-free与anchor-based之间的差距。
引言
近些年,Anchor-free的方法之所以被关注到是因为FPN与Focal Loss这两种方法的出现,这里简单说明下我个人的看法,FPN能够输出多个层级的特征,允许不同尺度的物体在不同层级的特征预测得到,如果没有FPN,想像一下如何使用Anchor free的方法,我能想到的就是YOLOv1,如果object的中心落在特征图网格内,则由该网格负责预测GT框,YOLOv1的缺点大家也很清楚,不同物体落入同一个网格的话,那么只能预测其中一个,另一个则无法预测。且每幅图片只能预测98个候选框,则显然是不够的。但有了FPN,上面两个缺点则可以较好地解决,不同尺度的物体落入的特征层级不同,则可以在不同层级检测出两个可能落入同一个网格的物体。另外多层级特征也就可以预测更多的候选框。也就可以提升模型的召回率。再来就是Focal loss,Focal loss告知在Dense prediction中正负样本的选取有多么重要,而Anchor free则是标准的不能再标准的Dense prediction了。因此说FPN与Focal loss的出现才让Anchor free算法重新受到了广泛的关注。
目前主流的Anchor-free的方法可以分成两种,1)通过定位几个预定的关键点,来确定物体的空间位置,这类方法算作keypoint-based methods,代表算法CornerNet和ExtremeNet。2)通过物体中心点以及中心点距离四条边界的距离,这类方法算作center-based methods,代表算法CenterNet,Foveabox,这些Anchor-free的检测器抛弃了与anchors相关的超参数,并且取得了与anchor-based方法想接近的效果。作者这里拿FCOS与RetinaNet作比较,探究造成anchor free的方法与anchor based的方法差异原因。
FCOS与RetinaNet的主要差异:
- RetinaNet在特征图上每个点会叠加多个不同长宽比的anchor,而FCOS则是在每个位置叠加一个anchor的中心点;
- RetinaNet是通过IoU来定义正负样本的,而FCOS则是通过anchor的中心点与GroundTruth的中心点的距离与尺度定义正负样本的。
- RetinaNet的回归策略是预测预设定的anchor box与物体GroundTruth的偏移量,而FCOS则是预测anchor中心点与GroundTruth中心的偏移量,以及点与各个边界的距离。
作者通过实验,证实**差异(2)**是导致两个检测器效果差异的主要原因。并证实了在同一个位置堆叠多个不同的anchor是不必要的操作,因此作者提出了ATSS,根据物体的统计分布来自动地挑选正负样本。最终在COCO上取得了SOTA的结果。
相关工作
本文的相关工作总结的比较到位,故在此整理下:
Two stage method:
最具代表的:Faster R-CNN
结构重新设计:R-FCN,TridentNet,Cascade R-CNN,ME R-CNN,MS-R-CNN
引入上下文信息和注意力机制(基本没看过):Inside-outside net[2],Thundernet 等等
多尺度训练:SNIP和AutoFocus
特征融合:FPN
更好地候选框与解决不平衡问题:Libra R-CNN
One stage method
最具代表性的:SSD
融合不同层上下文信息:RON,DSSD,STDN
从头训练:DSOD,ScratchDet
新的loss:Focal loss,ap-loss
anchor提炼:RefineDet, Freeanchor
结构重新设计:PFPNet
特征增强与对齐(基本没看过):
keypoint-based method
CornerNet、Grid R-CNN、ExtremeNet、RepPoints
Center-based method
YOLO、DenseBox、GA-RPN、FSAF、FCOS、CSP、FoveaBox
方法
作者通过设计对比实验,深究FCOS与RetinaNet两者的差异。首先控制差异(1),将RetinaNet每一层特征只分配一个anchor,anchor的大小为8S,S表示当前特征层下采样的倍数。此外作者还把FCOS一些提点方法补充到了RetinaNet上了,实验结果如下:
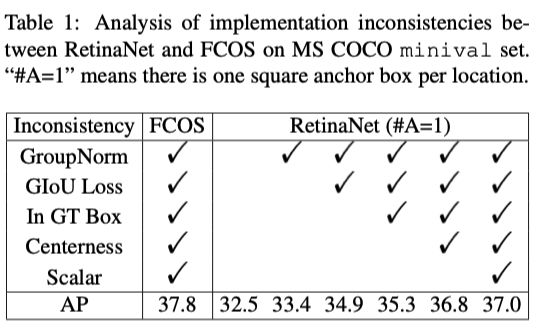
发现仍然有0.8%个点的差异,那这个部分差异从哪里来呢?只能来自剩下的两个差异了,差异(2)说白了就是分类子任务,差异(3)则是回归子任务。
分类
RetinaNet是通过IoU阈值来挑选正样本的,GT框与候选框的 I o U > Θ p IoU>\Theta_{p} IoU>Θp则认为该候选框为正样本而则 I o U < Θ n IoU<\Theta_{n} IoU<Θn则认为该候选框为负样本,其他样本则忽略。
而FCOS通过空间和尺度的约束来划分正负样本,如果anchor points在GT框内,则该point为候选点;然后通过point与各边界距离的最大值是否在该层级特征预设定的范围内,最终决定该point是否为正样本还是负样本。

作者通过以下的实验,两种挑选正负样本的方式,确实是导致FCOS与RetinaNet的差异的原因之一,FCOS使用IoU策略,效果下降。与RetinaNet基本一致,而RetinaNet使用空间和尺度的约束来挑选正负样本,效果提升至37.8%,与FCOS一致了。

**PS:**这里的实验没有太理解,FCOS如何接入IoU策略的,在没有anchor box的情况下,哪里来的IoU?
回归
RetinaNet是通过计算四个偏移量,anchor中心点与GT框中心点的偏移量与高宽的偏移量,而FCOS回归的则是中心点与四条边界的距离;在下图展示的十分明显。
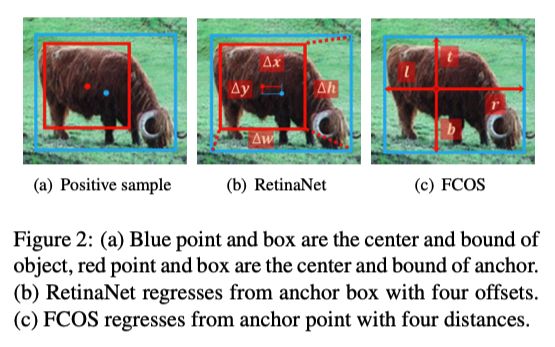
通过实验发现,无论是回归点还是回归候选框,两者的差异都不是很大,
说明差异(3)不是造成anchor-based与anchor-free方法效果差异的主要原因。进一步证实了差异(2)正负样本的挑选才是anchor-based与anchor-free方法效果差异的主要原因!
Adaptive Training Sample Selection
ATSS其实并没有很复杂,也是大家日常在挑选训练集的时候,可能都会用到的方法,只是这里用到了挑选正负样本上。ATSS算法步骤如下:
- 首先为每一个GT box挑选 中心点与其最近的K个anchor box(熟不熟悉,YOLOF的k-近邻算法 )作为候选框.
- 计算候选框与GT box的IoU,计算出其均值 m g m_{g} mg和方差 v g v_{g} vg,再计算IoU的阈值 t g = m g + v g t_{g} = m_{g} + v_{g} tg=mg+vg
- 最后挑选候选框与GT box的IoU大于阈值 t g t_{g} tg的作为最后的正样本,当然对正样本有些约束,要求正样本中心点必须在GT box内
- 如果一个anchor box被分配到多个GT box,选择最大IoU的那个 作为他的真值。
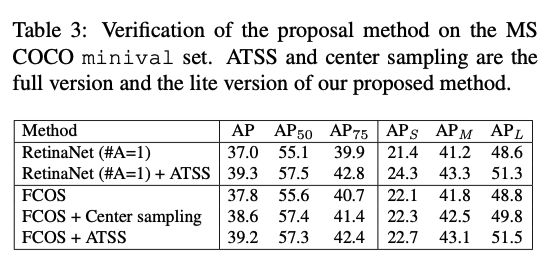
最后,在看下该策略的效果,普遍能涨2~3%个点。还是有些用的。
感想
本篇文章,最值得借鉴的是FCOS与RetinaNet差异性对比的实验设计,控制变量,逐步分析。确实考虑的足够细致,值的学习!而后续的ATSS不是很复杂,但作为涨点的技巧也是可以学习的。