DQN tensorflow2 + OpenAI gym 实战
OpenAI gym
手动编环境是一件很耗时间的事情, 所以如果有能力使用别人已经编好的环境, 可以节约我们很多时间. OpenAI gym 就是这样一个模块, 他提供了我们很多优秀的模拟环境. 我们的各种 强化学习算法都能使用这些环境.
CARTPOLE-V1 环境介绍
CartPole 是gym提供的一个基础的环境,即车杆游戏,游戏里面有一个小车,上有竖着一根杆子,每次重置后的初始状态会有所不同。小车需要左右移动来保持杆子竖直,为了保证游戏继续进行需要满足以下两个条件:
- 杆子倾斜的角度 \thetaθ 不能大于15°
- 小车移动的位置 x 需保持在一定范围(中间到两边各2.4个单位长度)
对于 CartPole-v1 环境,其动作是两个离散的动作左移(0)和右移(1),环境包括小车位置、小车速度、杆子夹角及角变化率四个变量。下面以CartPole-v1 环境为例,来介绍 DQN 的实现。
Q-Learning
在 Q-Learning 算法中,我们把这个长期奖励记为 Q 值,我们会考虑每个 ”状态s-动作a“ 的 Q 值,和动作a的回报R。具体而言,它的计算公式为
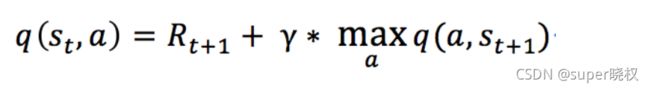
不过一般地,我们使用更为保守地更新 Q 表的方法,即引入松弛变量 alpha,按如下的公式进行更新,使得 Q 表的迭代变化更为平缓。

DQN
我们知道,神经网络的训练是一个最优化问题,最优化一个损失函数loss function,也就是标签和网络输出的偏差,目标是让损失函数最小化。为此,我们需要有样本,巨量的有标签数据,然后通过反向传播使用梯度下降的方法来更新神经网络的参数。
用Q-learning产生的数据来训练神经网络。实际Q值与目标Q值之差是神经网络优化的对象。

这里的y_j 就是目标Q值。当然了,一开始没有数据,要吧Q-Learning过程中产生的数据的结果存储到一定程度再计算目标Q值,处理好数据送去训练。
总代码如下
import argparse
import os
import random
import numpy as np
import gym
import tensorflow as tf
parser = argparse.ArgumentParser()
parser.add_argument('--train', dest='train', default=True)
parser.add_argument('--test', dest='test', default=True)
parser.add_argument('--gamma', type=float, default=0.95)
parser.add_argument('--lr', type=float, default=0.005)
parser.add_argument('--batch_size', type=int, default=32)
parser.add_argument('--eps', type=float, default=0.1)
parser.add_argument('--train_episodes', type=int, default=300)
parser.add_argument('--test_episodes', type=int, default=10)
args = parser.parse_args()
ALG_NAME = 'DQN'
ENV_ID = 'CartPole-v1'
# 经验放回池
class ReplayBuffer:
def __init__(self, capacity=10000):
self.capacity = capacity
self.buffer = []
self.position = 0
# 信息添加到经验池中
def push(self, state, action, reward, next_state, done):
if len(self.buffer) < self.capacity:
self.buffer.append(None)
self.buffer[self.position] = (state, action, reward, next_state, done)
self.position = int((self.position + 1) % self.capacity)
def sample(self, batch_size=args.batch_size):
batch = random.sample(self.buffer, batch_size)
state, action, reward, next_state, done = map(np.stack, zip(*batch))
"""
the * serves as unpack: sum(a,b) <=> batch=(a,b), sum(*batch) ;
zip: a=[1,4], b=[2,3], zip(a,b) => [(1, 2), (4, 3)] ;
the map serves as mapping the function on each list element: map(square, [2,3]) => [4,9] ;
np.stack((1,2)) => array([1, 2])
"""
return state, action, reward, next_state, done
class Agent:
def __init__(self, env):
self.env = env
self.state_dim = self.env.observation_space.shape[0]
self.action_dim = self.env.action_space.n
def create_model(input_state_shape):
model = tf.keras.models.Sequential([
# 全连接层
tf.keras.layers.Dense(32, activation='relu'),
tf.keras.layers.Dense(16, activation='relu'),
tf.keras.layers.Dense(self.action_dim)
])
model.build(input_shape=input_state_shape)
model.summary()
return model
self.model = create_model([None, self.state_dim])
self.target_model = create_model([None, self.state_dim])
self.model_optim = self.target_model_optim = tf.optimizers.Adam(learning_rate=args.lr)
self.epsilon = args.eps
self.buffer = ReplayBuffer()
# 更新目标网络参数
def target_update(self):
"""Copy q network to target q network"""
for weights, target_weights in zip(
self.model.trainable_weights, self.target_model.trainable_weights):
target_weights.assign(weights)
def choose_action(self, state):
if np.random.uniform() < self.epsilon:
return np.random.choice(self.action_dim)
else:
q_value = self.model(state[np.newaxis, :])[0]
return np.argmax(q_value)
# 学习部分
def replay(self):
for _ in range(10):
# sample an experience tuple from the dataset(buffer)
states, actions, rewards, next_states, done = self.buffer.sample()
# compute the target value for the sample tuple
# targets [batch_size, action_dim]
# target 是 32组数据预测结果 【动作为左的Q值 动作为右边的Q值】 这是过度的数据 既不是实际也不是目标Q值
target = self.target_model(states).numpy()
# next_q_values [batch_size, action_dim]
next_target = self.target_model(next_states)
next_q_value = tf.reduce_max(next_target, axis=1)
# 生成 [32,2]的数组 Q值表 [动作为左的目标Q值 动作为右边的目标Q值]
target[range(args.batch_size), actions] = rewards + (1 - done) * args.gamma * next_q_value
# use sgd to update the network weight
with tf.GradientTape() as tape:
q_pred = self.model(states) #算法运算出的实际Q值 model是一直被训练的网络, target[]数组是算法在产生数据时的目标Q值
loss = tf.losses.mean_squared_error(target, q_pred)
grads = tape.gradient(loss, self.model.trainable_weights)
self.model_optim.apply_gradients(zip(grads, self.model.trainable_weights))
def test_episode(self, test_episodes):
for episode in range(test_episodes):
state = self.env.reset().astype(np.float32)
total_reward, done = 0, False
while not done:
action = self.model(np.array([state], dtype=np.float32))[0]
action = np.argmax(action)
next_state, reward, done, _ = self.env.step(action)
next_state = next_state.astype(np.float32)
total_reward += reward
state = next_state
self.env.render()
print("Test {} | episode rewards is {}".format(episode, total_reward))
# 算法控制
def train(self, train_episodes=200):
if args.train:
for episode in range(train_episodes):
total_reward, done = 0, False
state = self.env.reset().astype(np.float32)
while not done:
action = self.choose_action(state)
next_state, reward, done, _ = self.env.step(action)
next_state = next_state.astype(np.float32)
self.buffer.push(state, action, reward, next_state, done)
total_reward += reward
state = next_state
# self.render()
if len(self.buffer.buffer) > args.batch_size:
self.replay()
self.target_update()
print('EP{} EpisodeReward={}'.format(episode, total_reward))
# if episode % 10 == 0:
# self.test_episode()
self.saveModel()
if args.test:
self.loadModel()
self.test_episode(test_episodes=args.test_episodes)
# 保存模型
def saveModel(self):
path = os.path.join('model', '_'.join([ALG_NAME, ENV_ID]))
if not os.path.exists(path):
os.makedirs(path)
self.model.save(os.path.join(path, 'model.hdf5'))
self.target_model.save(os.path.join(path, 'target_model.hdf5'))
print('Saved weights.')
# 加载模型
def loadModel(self):
path = os.path.join('model', '_'.join([ALG_NAME, ENV_ID]))
if os.path.exists(path):
print('Load DQN Network parametets ...')
self.model = tf.keras.models.load_model(os.path.join(path, 'model.hdf5'))
self.target_model = tf.keras.models.load_model(os.path.join(path, 'target_model.hdf5'))
print('Load weights!')
else:
print("No model file find, please train model first...")
if __name__ == '__main__':
env = gym.make(ENV_ID)
agent = Agent(env)
agent.train(train_episodes=args.train_episodes)
env.close()
参考:
Q-learning算法实践_gao2175的博客-CSDN博客_qlearning算法我们将会应用 Q-learning 算法完成一个经典的 Markov 决策问题 -- 走迷宫!项目描述:在该项目中,你将使用强化学习算法,实现一个自动走迷宫机器人。如上图所示,智能机器人显示在右上角。在我们的迷宫中,有陷阱(红色炸弹)及终点(蓝色的目标点)两种情景。机器人要尽量避开陷阱、尽快到达目的地。小车可执行的动作包括:向上走u、向右走r、向下走d、向左走...https://blog.csdn.net/gao2175/article/details/83340449
DQN从入门到放弃5 深度解读DQN算法 - 知乎0 前言如果说DQN从入门到放弃的前四篇是开胃菜的话,那么本篇文章就是主菜了。所以,等吃完主菜再 放弃吧!1 详解Q-Learning在上一篇文章 DQN从入门到放弃 第四篇中,我们分析了动态规划Dynamic Programming并且由… https://zhuanlan.zhihu.com/p/21421729
https://zhuanlan.zhihu.com/p/21421729
强化学习 8 —— DQN 代码 Tensorflow 2.0 实现 - 灰信网(软件开发博客聚合) https://www.freesion.com/article/60731143931/
https://www.freesion.com/article/60731143931/
[1] Mnih, Volodymyr, et al. "Playing atari with deep reinforcement learning." arXiv preprint arXiv:1312.5602 (2013).
[2] Mnih, Volodymyr, et al. "Human-level control through deep reinforcement learning." Nature 518.7540 (2015): 529-533.