DL-Paper精读:LSTM + Transformer 架构模型
Transformer Language Models with LSTM-based Cross-Utterance Information Representation
https://arxiv.org/abs/2102.06474arxiv.org
Background
近来,源于某个神奇的需求,需要研究Transformer和LSTM相结合的模型架构。这两者作为自然语言领域两个时代的王者,似乎对立的戏份远大于合作。常理来说,在Transformer刚刚被提出来的一两年内,应该有很多关于这方面的研究工作,但很奇怪地是并未搜索到比较出名的工作。难道是这两者组合效果不佳,水火不容?这篇文章是收录于ICASSP2021的一个工作,旨在将LSTM结合到Transformer结构中,通过一种交叉的信息表达,来获得更强大更鲁棒的语言模型。
对该工作的研究,主要集中在其网络架构的设计和代码的实现方面。由于对于语言方面的不了解,不太清楚文中所给出的0.9%, 0.6% and 0.8% absolute WER reductions on AMI corpus代表怎样的意义。
Architecture
文中针对常见的Transformer Language models(TLM)和TLM-XL(一种使用分段递归来实现超长序列预测的方法)进行改造,具体结构如下。TLM的核心部分是重复的Transformer模块,由多头自适应(Masked MHA)和FFN模块组成。而TLM-XL的区别在于,在计算MHA时将上个block的输入与本次的输入进行concat,共同计算。

文中提出的LSTM + TLM架构(称为R-TLM)如下,网络其他部分不未进行改动,主要是在MHA模块的前端插入了LSTM模块,对于输入X,首先通过LSTM进行处理,输出与原输入进行一个fusion之后,再作为输入传到MHA中,执行政策的Transformer block的操作。其中LSTM的h/c等使用上一个block的输出。
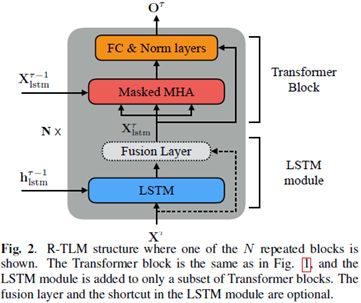
对于R-TLM架构的优势,文中解释如下:
-
在测试re-score阶段,对于 past utterance(对于utterance实在理解不够)中的单词错误,LSTM模块的隐含信息能够有效缓解其影响,提高鲁棒性;
-
R-TLM能够同时提供LSTM和Transformer模块所提供的补充历史信息和基于注意力的信息表示,提高了模型能力;
-
R-TLM作为两种模型的结合体,能够解决单个模型在不同大小数据集上性能表现不同的问题(一般LSTM在小数据集上比Transformer表现更好,但Transformer在预训练后表现很突出)。
Implementation
Creation:
LSTM
if rnnenc and rnndim != 0: # merge_type为gating或project时,将输入输出进行concat再通过linear层统一维度
if merge_type in ['gating', 'project']:
self.rnnproj = nn.Linear(rnndim + d_model, d_model)
self.rnn_list = nn.ModuleList([nn.LSTM(d_model, rnndim, 1) for i in range(len(self.rnnlayer_list))])Transformer
for i in range(n_layer):
# dropatt = dropatt * 2 if (i == 0 and rnnenc) else dropatt
use_penalty = i in self.attn_pen_layers
self.layers.append( RelPartialLearnableDecoderLayer( n_head, d_model, d_head, d_inner, dropout, tgt_len=tgt_len, ext_len=ext_len, mem_len=mem_len, dropatt=dropatt, pre_lnorm=pre_lnorm, penalty=use_penalty) )两者的层数一致,也就是说每个Transformer block前分别建立一个LSTM
Forward:
其中第一层的LSTM被单独拿出来在循环之前进行了计算。所以每个LSTM的输入为core_out, 经过LSTM模块之后,输出的rnn_out与原来的core_out进行组合作为新的输入喂给下一个Transformer模块;而LSTM输出的rnn_hidden被作为下一个LSTM的输入hidden_state。
for i, layer in enumerate(self.layers):
if self.future_len != 0:
dec_attn_mask = dec_attn_mask_future if i in self.layer_list else dec_attn_mask_normal
mems_i = None if mems is None else mems[i]
# Perform Attention Layer
core_out, attn_pen = layer(core_out, pos_emb, self.r_w_bias,
self.r_r_bias, dec_attn_mask=dec_attn_mask,
mems=mems_i)
# gs534 - rnn in the middle of a transformer layer
if self.rnnenc and i+1 in self.rnnlayer_list:
# performe LSTM module
rnn_out, rnn_hidden = self.forward_rnn(i+1, core_out, rnn_hidden, stepwise, future_seqlen)
# merge input and output of LSTM
if self.merge_type == 'project':
core_out = torch.relu(self.rnnproj(torch.cat([rnn_out, core_out], dim=-1)))
# core_out = (self.rnnproj(torch.cat([rnn_out, core_out], dim=-1)))
elif self.merge_type == 'gating':
core_gating = torch.sigmoid(self.rnnproj(torch.cat([rnn_out, core_out], dim=-1)))
core_out = rnn_out * core_gating + core_out * (1 - core_gating)
else:
core_out = rnn_out
attn_pen_list.append(attn_pen)
hids.append(core_out)Thoughts
对于LSTM + Transformer这样一个架构,实在是心存疑虑。接下来会复现该工程,证明其可行性,同时尝试向其他工作中嵌入。探索这样一个结构,将LSTM和Attention同时在一个网络中相互嵌套,来实现更高的精度,感觉首先应该想清楚的,是它们两者所输出的结果分别蕴含着怎样的信息,它们是否能够简单的进行组合,或者是否有更合理地互补组合方法。文中虽然通过实验证明了其可行性,并一定程度地提高了精度,但是一来这些提高是否真的有意义,或者说是否是两种模型的互补是否真的有机地起作用了(感觉如果两者真的能够很好地组合,从不同视角去解析信息,应该带来更高的精度提高才对)。其次文中提出的fusion layer,是否有探究,它到底是起到了怎样的作用,究竟是在训练之后找到了更好地组合权重,还是其实是偷偷将LSTM的输出进行了屏蔽。。。整体的工作研究,尚需更多的验证。