深度学习第四课——目标检测(week 3)
目录
三、目标检测
3.1 目标定位
3.2 特征点检测
3.3 目标检测
3.4 卷积的滑动窗口实现
3.5 Bounding Box预测
3.6 交并比(IoU)
3.7 非极大值抑制
3.8 Anchor Boxers
3.9 YOLO算法
3.10 候选区域(可选)
三、目标检测
图像分类:遍历所有图片,判断是不是汽车
定位分类:不仅要判断是不是汽车,还要判断出他的位置
多个对象:多个对象时,如何检测并判断位置;如不仅要检测汽车,还要检测人和障碍物

所以图片分类的思路可以帮助学习分类定位,而对象定位的思路又有助于学习对象检测
3.1 目标定位
例如,输入一张图片到多层卷积网络,他会输出一个特征向量,并反馈给softmax单元来预测图片类型。如果在构建一个自动驾驶系统,那么对象可能会包括:行人、汽车、摩托车、背景
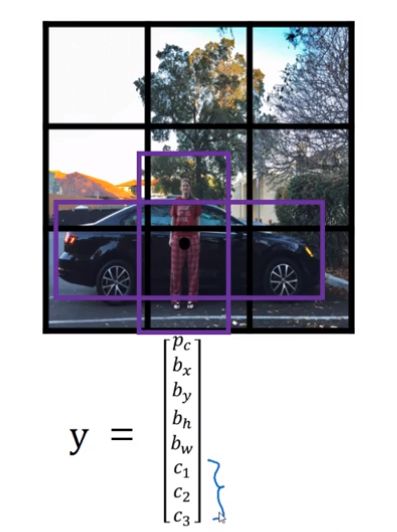
如果还想定位汽车的位置,我们可以让神经网络多输出几个单元,输出一个边界框,也就是多输出四个数字,标记为 bx,by,bh,bw,这四个数字是被检测对象边界框的参数化表示。
先约定图片左上角为(0, 0),右下为(1, 1);边界框中心点坐标为(bx, by),高度为 bh,宽度为bw

本例中,bx=0.5, by=0.7,bh=0.3, bw=0.4
目标标签Y 的定义如下:
他是一个向量,第一个组件Pc表示是否含有对象,即如果对象属于前三类,则Pc=1;如果是背景,则Pc=0。可以这样理解Pc,他表示被检测对象属于某一分类的概率,背景分类除外,如果检测到对象,就输边界框参数bx,by,bh,bw ,如果Pc=1,则输出c1,c2,c3,表示该对象属于1-3的哪一类
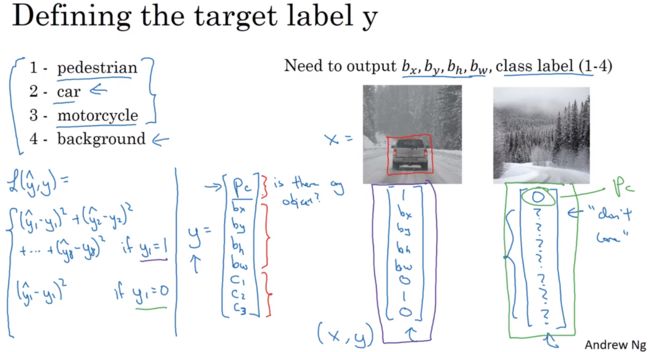
训练神经网络的损失函数,其参数为类别Y 和网络输出Y^ ,损失函数可以表示为L(Y^, Y);
这里假设平方误差的损失函数,Y=0时,就不需考虑除Pc之外其他的了,只有Y1。而实际中,可以不用对c1、c2、c3 和 softmax 激活函数应用对数损失函数,并输出其中一个元素值;通常做法是对边界框坐标应用平方误差或类似方法,对Pc应用逻辑回归函数,甚至采用平方预测误差也是可以的
结果证明:利用神经网络输出批量实数来识别图片中的对象,是个非常有用的算法。
3.2 特征点检测
概括的说,神经网络可以通过输出图片上特征点的(x, y)坐标,来实现对目标特征的识别。
假设正在构建一个人脸识别应用,希望算法可以给出眼角的具体位置,可以让神经网路最后一层多输出两个数字 lx 和 ly,作为眼角的坐标值,如果想知道两只眼睛的四个眼角的位置,那么从左到右,依次用四个特征点来表示这四个眼角,对神经网络稍做修改,输出第一个特征点(l1x, l1y),第二个特征点(l2x, l2y),依此类推。这四个脸部特征点的位置就可以通过神经网络输出了。
还可以根据嘴部的关键点输出值来确定嘴的形状,从而判断人物实在微笑还是皱眉,也可以i提取鼻子周围的关键特征点;
为了便于说明,可以设定特征点的个数,假设脸部有64个特征点,有些点甚至可以帮助你定义脸部轮廓或下颌轮廓。选定特征点个数,并生成包含这些特征点的标签训练集,然后利用神经网络输出脸部关键特征点的位置。
具体做法是,准备一个卷积神经网络和一些特征集,将人脸图片输入卷积网络,输出1或0,1表示有人脸,0表示没有人脸,然后输出(l1x, l1y)。。。直到(l64x, l64y)。这只是一个识别脸部表情的基本构造模块。
AR(增强现实),帮助解决其他如脸部扭曲,头戴皇冠等问题,当然为了解决这些问题,需要一个标签训练集,即X 和 Y的集合,这些特征点都是认为辛苦标注的
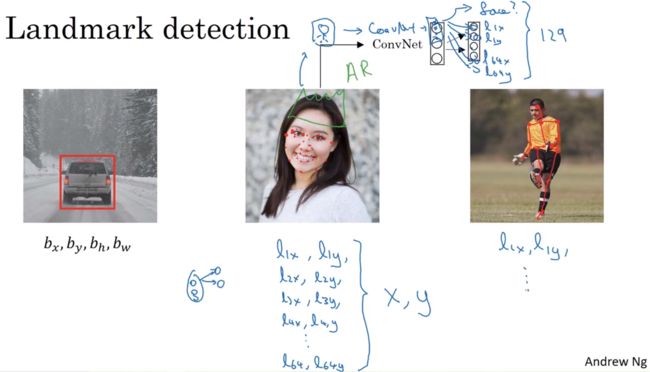
最后还可以标注胸部、肩部等部位的中点来确定人体姿态。然后通过神经网络标注任务姿态的关键特征点,再输出这些标注过的特征点,就相当于输出了人物的姿态动作, 当然要实现这些,需要设定这些关键特征点,从胸部中心点(l1x, l1y)一直往下直到(l32x, l32y)。
而标签在所有图片中必须保持一致,比如特征点1始终是右眼的外眼角,特征点2是右眼的内眼角等等,这就是特征点检测。
3.3 目标检测
采用基于滑动窗口的目标检测算法,通过卷积网络进行对象检测
假设想构建一个汽车检测算法,步骤是:首先创建一个标签训练集,也就是X和Y表示适当剪切的汽车图片样本,出于我们对这个训练集的期望,一开始就可以使用适当剪切的图片,就是整张图片X几乎都被汽车占据。可以照张照片,然后剪切,剪掉汽车以外的部分,使汽车居于中心位置并基本占据整张图片,有了这个标签训练集,就可以开始训练卷积网络了。
输入这些适当剪切过的图像,卷积网络输出Y ,0或1 表示有没有汽车,训练完这个卷积网络,就可以用它来实现滑动窗口目标检测。

具体做法,假设这是一张测试图片,首先选定一个特定大小的窗口,比如图片下方这个窗口(红色小方块),将这个小方块输入卷积网络,卷积网络开始预测,即判断红色方框内有没有汽车


滑动窗口目标检测算法接下来会继续处理第二个图像,继续输入给卷积网络,然后处理第三个图像,依次重复


直到这个窗口滑过图像的每一个角落,为了滑动的更快,这里选用的步幅比较大,思路是以固定步幅滑动窗口,遍历图像的每个区域,把剪切后的小图像输入卷积网络,对每个位置按0或1进行分类,这就是所谓的图像滑动窗口操作
重复上述操作,不过这次选择一个更大的窗口,截取更大的区域,并输入给卷积网络处理,可以根据卷积网络对输入大小的要求调整这个区域,再以某个固定步幅滑动窗口,重复以上操作,遍历整个图像,输出结果
第三次也选用一个更大的,这样一来,无论汽车在哪个位置,总有一个窗口可以检测它,希望卷积网络对该输入区域的输出结果为1,说明网络检测到图上有辆车,这种算法叫做 滑动窗口目标检测
因为我们以某个步幅滑动这些方框窗口,遍历整张图片,对这些方形区域进行分类,判断里面有没有汽车,滑动窗口目标检测算法也有很明显的缺点,就是计算成本,因为图片中剪切除太多的小方块了,卷积网络要一个个处理,如果选用的步幅很大,显然会减少输入卷积网络的窗口个数,但是粗粒度可能会影响性能;反之,如果采用小粒度或小步幅,传递的小窗口会特别多,意味着超高的计算成本

所以在神经网络兴起之前,人们通常采用更简单的分类器进行对象检测,比如简单的线性分类器,至于误差,因为每个分类器的计算成本都很低,他只是一个线性函数,所以滑动窗口目标检测算法表现良好,是个不错的算法。然而 卷积网络运行单个分类任务的成本却高很多,像这样滑动窗口太慢了,除非采用超细粒度或极小步幅,否则无法准确定位图片中的对象
不过现在已经有了解决方案
3.4 卷积的滑动窗口实现
如何在卷积层上应用这个算法
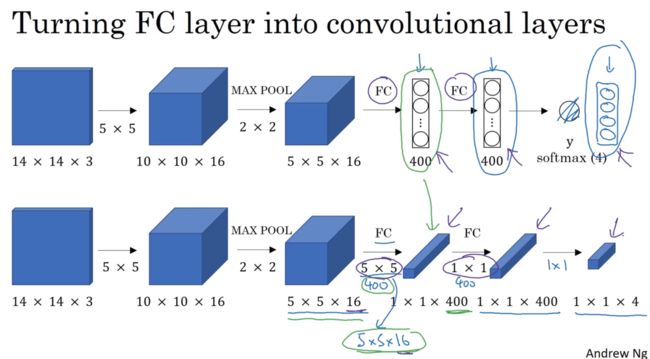
为了构建滑动窗口的卷积应用,首先要知道如何把神经网络的全连接层转化成卷积层
假设对象检测算法输入一个14×14×3 的图像,过滤器是 5×5 ,16个,输出 10×10×16 ,然后通过参数为2×2 的最大池化操作,图像减小到 5×5×16,然后添加一个连接400个单元的全连接层,接着再添加一个全连接层,最终通过softmax单元输出Y,有4个数字表示Y,分别对应softmax单元所输出的4个分类出现的概率
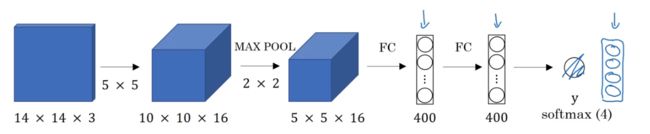
下面要演示的就是如何把这些全连接层转化成卷积层
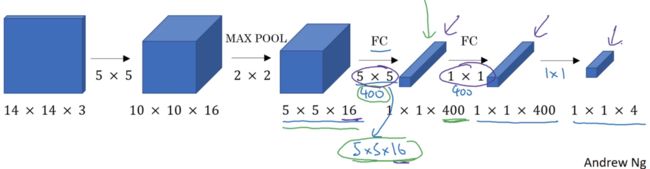
到第一个全连接层,我们可以用5×5×16的过滤器来实现,数量是400个,输出结果为1×1×400,我们不再把它看作一个含有400个节点的集合,而是一个1×1×400的输出层,从数学角度看,它和全连接层是一样的,因为这400个节点中每个节点都有一个5×5×16的过滤器,所以每个值都是上一层上这些5×5×16激活值经过某个任意线性函数的输出结果。我们再添加另外一个卷积层,这里用1×1卷积,有400个,所以下一层的维度是1×1×400,它其实就是上个网络中的这一全连接层,最后经由1×1过滤器的处理,得到一个softmax激活值,最终得到这个1×1×4的输出层,而不是4个数字。
掌握了卷积知识,再看看如何通过卷积实现滑动窗口对象检测算法。
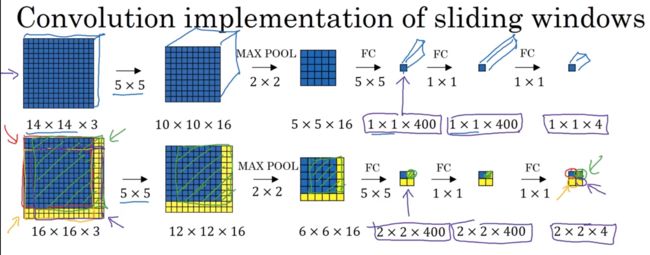
假设向滑动窗口卷积网络输入14×14×3的图片,神经网络最后的输出层即softmax单元的输出,是1×1×4
现在给这个输入图片加上黄色条块,在最初的滑动窗口算法中,你会把这片蓝色区域输入卷积网络,生成0或1分类,接着滑动窗口,步幅为2个像素,将这个绿色区域输入卷积网络,得到另一个标签0或1;继续将橘色区域输入卷积网络,得到另一个标签;最后对右下的紫色区域及逆行最后一次卷积

我们在这个16×16×3小图像上滑动窗口,卷积网络运行了4次,于是输出了4个标签,结果发现,这4次卷积操作中的很多操作都是重复的。
这时得到的输出层为2×2×400,然后应用1×1过滤器,得到2×2×400,再一次全连接操作,最终得到一个2×2×4的输出层。最终输出层的4个子方块中,蓝色的是图像左上部分14×14的输出,右上角方块是图像右上部分的对应输出,依次都是。具体计算以绿色为例,如下所示
也就是说用四个小的计算,代表大区域的计算,其中共有区域还可以共享很多计算,这就是全连接层转化为卷积层的好处
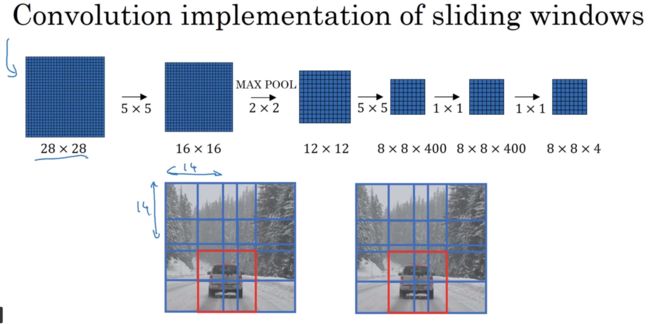
更大的例子,输入一个28×28×3的图像,最后得到8×8×4的输出,首先在左上角14×14区域应用滑动窗口,对应输出层左上角 ,接着以步幅为2不断向右移动,然后向下移动。因为最大池化为2×2,相当于以大小为2的步幅在原始图片上应用神经网络
MAXPOOLING之后,滑窗每移动一格相当于MAXPOOLING之前滑窗移动两格,因为MAXPOOLING可以看成把四个小方块合成一个了
总结一下滑动窗口的实现过程,在图片上剪切出一块区域,假设大小是14×14,把他输入到卷积网络,继续下一块重复操作,直到某个区域识别到汽车,正如上面看到的,我们不用依靠连续的卷积操作来识别图片中的汽车。
比如我们可以对28×28的整张图片进行卷积操作,一次得到所有预测值,如果足够幸运,神经网络便可以识别出汽车的位置
以上就是在卷积层上应用滑动窗口算法的内容,它提高了整个算法的效率,不过仍有一个缺点,就是边界框可能不够准确
这个算法将原本需要一个个输入的,现在通过卷积计算,将一张图片每次的window同时进行卷积,最终得到的就是结果
3.5 Bounding Box预测
下面来看看如何得到更精准的边界框:
如果跑的框没有一个可以完美匹配汽车位置,最适合的也是歪的,甚至最适合的框不是正方形,而是稍微有点长方形,长宽比有点向水平方向延伸

其中一个能得到更精准的边界框的算法是 YOLO 算法,YOLO的意思你只看一次(YOLO = You Only Look Once)
比如你的输入图像是100×100的,然后再图像上放一个网格,为了介绍起来简单一些,这里用3×3的网格,实际实现时会用更精细的网络,可能19×19

基本思路是:使用图像分类和定位算法,然后将算法应用到9个格子上
更具体一些,你需要这样定义训练标签,所以对于9个格子中的每一个指定一个标签y,y是8维向量,第一个是Pc,0或1取决于是否有图像,对于每个格子都有这么一个向量

我们看左上角格子,啥也没有,所以它的y是

这张图中有两个对象,YOLO算法做的就是 取两个对象的中点,然后将这个对象分配给包含对象中点的格子,所以这张图的两个对象分在中间行左右两个格子,即使中心格子同时有两辆车的一部分,我们就假装中心格子没有任何我们感兴趣的对象,所以中心格子的y也和左上角的一样。
而对于左边绿色框起来的和右边黄色的,y就是
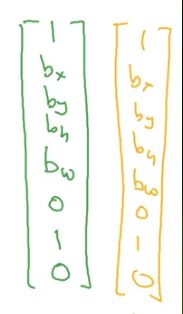
因为是3×3的网格有9个格子,所以总的输出尺寸是3×3×8,然后对于每个格子都有一个8维向量
而如果要训练一个输入100×100×3的神经网络,选择卷积层和最大池化层,这样最后映射到一个3×3×8的输出尺寸,所以要做的就是,有一个输入x 就是这样的输入图像,然后有这些3×3×8的目标标签y
当用反向传播训练神经网络时,将任意输入x映射到这类输出向量y,所以这个算法的优点在于:神经网络可以输出精确的边界框。因为每一格对应的输出向量中都有边界框参数bx、by......,因为别的格子中的边界属于卷积时的公有区域、卷积运算后会将此部分的坐标权重加给Pc等于1那块对应的坐标,训练时手动标
所以测试的时候,做的就是输入图像x,跑正向传播,直到得到输出y,然后对于这里的3×3位置对应的9个输出,就可以读出0或1,你就知道9个位置之一有个对象,且这个对象的边界框是什么,只要格子中对象的数目没有超过1个,这个算法就应该没有问题
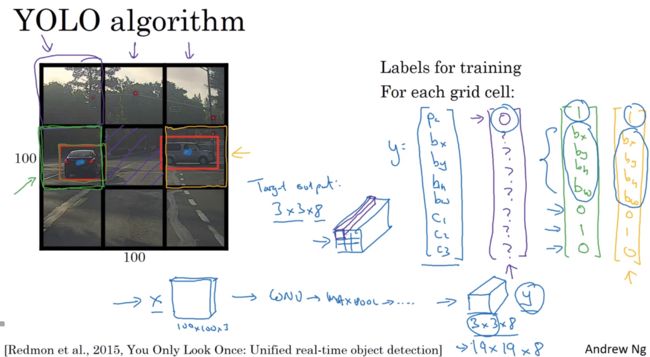
这里用的是3×3的网格,实践中可能会用更精细的19×19的网格,所以就是19×19×8的,这样的网格精细很多,分配到同一格子的概率就小很多。
把对象分配到一个格子的过程是,你观察对象的中点,然后将这个对象分配到其中点所在的格子,所以即使对象横跨多个格子,也只会被分配到9个格子其中之一
所以要注意,首先这和图像分类和定位算法非常想,它显式地输出边界框坐标,所以这能让神经网络输出边界框,可以具有任意宽高比,并且能输出更精确的坐标,不会受到滑动窗法分类器的步长大小限制;其次,这是一个卷积实现,并没有在3×3网格上跑9次算法,这是单次卷积实现,你使用了一个卷积网络,有很多共享计算步骤,所以该算法效率很高
事实上,YOLO算法有一个好处,也是它受欢迎的原因,因为这是一个卷积实现,它的运行速度非常快,可以达到实时识别
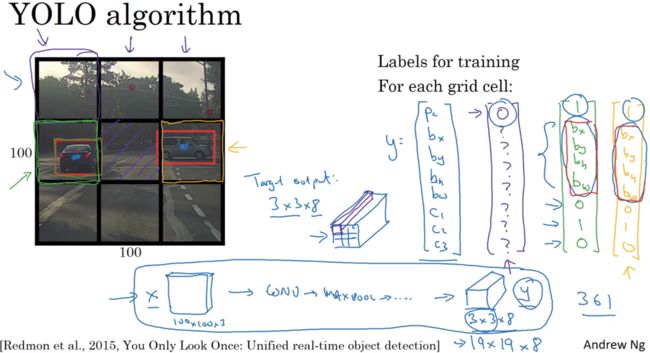
还有一个小细节,就是如何编码边界框 bx,by,bh,bw
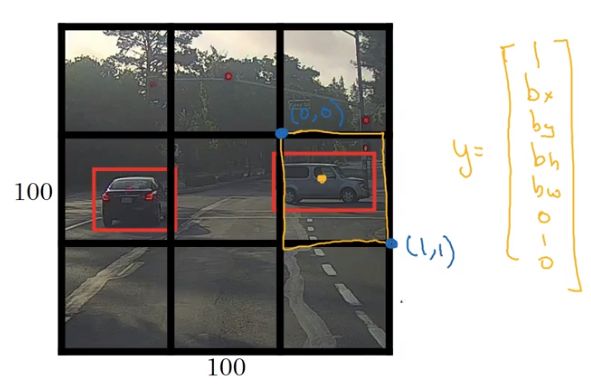
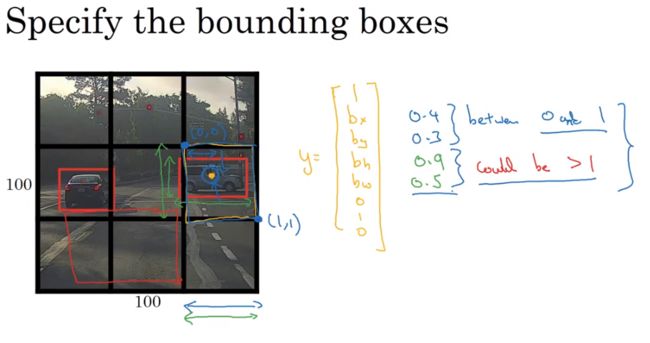
如右边网格的对象,以这个网格左上角为(0,0),右下角为(1,1),即bx,by,bh,bw是相对网格尺度的比例,bx,by在0和1之间,bh,bw可能大于1
不过还有其他更复杂的参数化方式,如sigmoid确保在0和1之间,然后使用指数参数化,确保都是非负数,还有其他更高级的参数化方式
也可以看看YOLO论文,但较难
3.6 交并比(IoU)
如何判断对象检测算法运作良好呢?
运用交并比函数可以用来评价对象检测算法
在对象检测任务中,实际边界框是红框,而算法给出的是紫框;那么这个是好是坏呢?

所以交并比(IoU)函数做的是 计算两个边界框交集和并集之比,一般认为IoU大于或等于0.5就说检测正确,完美重叠时,IoU=1,IoU越高,边界框越精确,阈值也可以人为定的更严格,比如0.6甚至0.7

3.7 非极大值抑制
迄今为止,我们学到的对象检测中的一个问题是 算法可能对同一对象做出多次预测,所以算法不是对某个对象检测出一次,而是检测出多次,非极大值抑制可以确保你的算法对每个对象只检测一次
假设需要在这张图里检测行人和汽车,可能会放个19×19的网格

理论上车只有一个中点,只有一个格子可以做出有车的预测;实践中,跑对象分类和定位算法时,可能周围的格子都认为里面有车,周围的格子在分类的时候有车的特征,但它并不知道中心点在不在自己格子里
那么非极大值抑制是如何生效的呢?
因为要在19×19=361个格子上都跑一遍图像检测和定位算法,那么很多格子都会说我这里有车的概率很高,而不是仅有两个格子会报告他们检测出一个对象,所以跑算法时,最后可能会对同一个对象做出多次检测

所以非极大值抑制做的就是清理这些检测结果,所以具体上,这算法做的就是,首先看看每次报告,每个检测结果相关的概率Pc,首先看概率最大的哪个,这个例子中是0.9,所以高亮标记,其次非极大值抑制逐一深时剩下的矩形,所有和这个最大的边界框有很高交并比,高度重叠的其他边界框,那么这些输出就会被抑制,所以右边两个0.6和0.7的框将被抑制变暗;
接下来再逐一审视剩下的矩形,找出概率Pc最高的一个,即左边的0.8,此时非极大值抑制就会去掉其他IoU值很高的矩形,所以现在每个矩形都是高亮或者变暗的,抛去变暗的,剩下的高亮就是结果。
非最大值意味着只输出概率最大的分类结果,抑制很接近但不是最大的其他预测结果,所以叫非极大值抑制

算法细节:首先在19×19的网格上跑算法,会得到19×19×8的输出,简化一下只检测汽车,可以去除c1、c2、c3。现在要实现非极大值抑制,第一就是去掉所有边界框,去掉Pc小于0.6的,然后选择Pc最高的输出为预测结果,再去掉有很高交并比的边界框,直到所有边界框都判断一遍

这里只检测的单个对象,如果要同时检测三个对象,如行人、汽车、摩托,那么输出向量就会有三个额外的分量;事实证明,正确的做法是,独立进行三次非极大值抑制对每个输出类别都做一次
3.8 Anchor Boxers
到目前为止,对象检测存在的一个问题是,每个格子只能检测出一个对象,如果想要一个格子检测出多个对象,就是使用anchor box概念
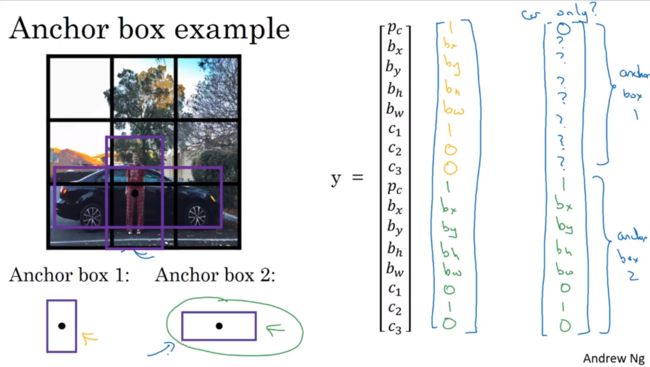
对于下列的例子,我们采用3×3网格,而行人和汽车的中点几乎在一个地方,所以落在同一格子。输出y时将无法,输出检测结果,所以必须从两个结果中选择一个
而anchor box的思路就是,预先定义两个不同形状的 anchor box,要做的就是,把预测结果和这两个 anchor box关联起来,一般来说,可能会用更多的 anchor box,可能要5个甚至更多,但对于这个例子,我们只用两个
要做的就是定义类别标签,用的向量y需要重复两次;行人的形状像 anchor box 1,所以用上面8个数值,用它来编码包住行人的边界框,说明对象是个行人;汽车像 anchor box 2,就用下面的编码

总结一下,用anchor box之前,做的是对于训练集图像中的每个对象都根据那个对象中点位置,分类到对应的格子中,所以输出是3×3×8;而anchor box是这样的,每个对象都和之前一样分配到同一个格子中,分配到对象中点所在的格子,但是他还分配到一个anchor box分配到一个格子和对象形状交并比最高的anchor box,观察哪一个anchor box和实际边界框交并比更高,不管选的哪一个,这个对象不止分配到一个格子,而是一对,这就是对象在目标标签中的编码方式,所以现在输出就是3×3×16,也可以看成是3×3×2×8,如果有多个对象,那么y的维度会更高,如下:

来看一个具体的例子,对于这个例子,我们定义一下y,行人类别1,汽车类别2;只有格子一个对象时,如果像anchor box 2,那么anchor box 1的Pc就是0,其他don‘t care
但如果有2个anchor box,而同一格子有3个对象时,算法处理不好,还有两个对象anchor box的形状一样的情况,也处理不好,所以需要打破僵局的处理手段
anchor box就是处理两个对象在同一格子的情况,但实际很少发生,特别是用的19×19的网格情况下而不是3×3的网格,一般手动指定anchor box的形状,可以选5到10个形状,还有更好的做法,即k-means算法,将两类对象聚类,用它选择一组anchor box,选择最具代表性的一组,可以代表你试图检测的十几个对象的类别,其实是自动选择anchor box 的高级方法
3.9 YOLO算法
让我们把所有零件组合在一起,构成YOLO对象检测算法
首先如何构造训练集:
假设要训练一个算法取检测行人、汽车、摩托,还需要显式指定完整的背景类别,这里有3个类别标签。如果要用2个anchor box,那么输出就是3×3×2×8,要构建训练集,需要遍历9个格子,然后构成对应的目标向量y,最终输出尺寸就是3×3×16
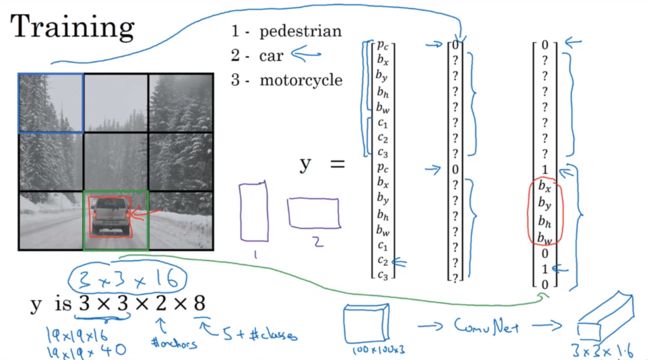
训练时一个卷积网络,输入是图片,可能是100×100×3,然后卷积网络最后输出尺寸是3×3×16或3×3×2×8
接下来看看卷积网络是如何预测的:
根据输入图片,如左上角没有东西就应该Pc为0,下方有汽车,我们就希望对车子指定一个相当准确的边界框
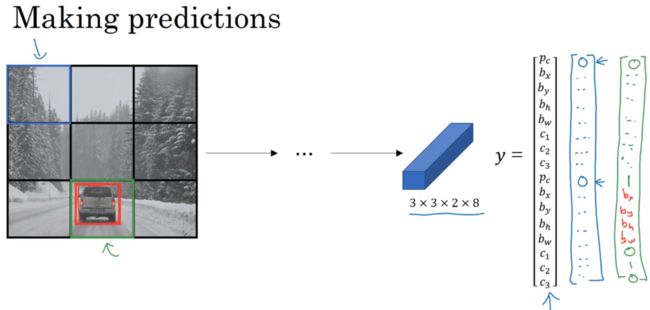
最后,要跑一下非极大值抑制的话,我们用一张新的图片
如果使用2个anchor box,那么对于9个格子中的任何一个都会有两个预测的边界框,其中一个的Pc很低,比如得到的边界框是这样的

有一些边界框可以超出所在格子的高度和宽度,接下来抛弃概率低的预测

最后,如果有三个对象检测类别,希望检测到行人、汽车、摩托,就对每个类别单独运行非极大值抑制,处理预测结果是那个类别的边界框,用非极大值抑制分别来处理行人、汽车、摩托类别,运行三次得到最终预测结果;所以算法输出,最好可以检测出图像里所有的汽车,还有所有的行人和摩托
3.10 候选区域(可选)
可选只是因为用到候选区域这一系列算法的概率没那么高,但是是很有影响力的
如下图,跑算法时,会在没有任何对象的区域浪费时间,所以提出一种叫做 R-CNN 的算法,意思是带区域的卷积网络 或者说 带区域的CNN,这个算法尝试选出一些区域,在这些区域上运行卷积网络分类器是有意义的,所以这里不再针对每个滑动窗跑检测算法,而是只选择一些窗口,在少数窗口上运行卷积网络分类器

选出候选区域的方法是:运行图像分割算法,结果是下边的图像

为了找出可能存在对象的区域,比如说分割算法在这里得到一个色块,所以你可能在这个色块上跑分类器,也像上面的绿色框,在绿色框再跑分类器,所以这个就是所谓的分割算法。找出2000多个色块,在这些色块上跑一下分类器,这样需要处理的位置可能少很多,可以减少卷积网络分类器运行时间,


现在看来R-CNN算法还是很慢的,所以有一系列研究来改善
所以基本的R-CNN算法是使用某种算法求出候选区域,然后对每个区域跑一下分类器,每个区域会输出一个标签,并输出一个边界框,这样就能在确实存在对象的区域得到一个精确的边界框。
R-CNN算法不会直接信任输入的边界框,他也会输出一个边界框bx、by、bw、bh,这样得到的边界框比较精确,比单纯使用图像分割算法给出的色块边界要好,所以它可以得到相当精确的边界框
现在R-CNN的一个缺点就是太慢了,有一些对R-CNN算法的改进工作,即快速R-CNN,用的是滑动窗法的一个卷积实现,而最初的算法是逐一对区域分类;事实证明,快速R-CNN算法的其中一个问题就是得到候选区域的聚类步骤仍然非常缓慢,所以又提出了另一个更快的
使用的是卷积神经网络, 而不是更传统的分割算法,来获得候选区域色块,结果快得多,不过大多数更快R-CNN算法实现还是比YOLO算法慢很多
