评分卡模型开发-定性指标筛选
定量指标是数值型的,我们还可以用回归的方法来筛选,那么定性的指标怎么办呢?
R里面给我们提供了非常强大的IV值计算算法,通过引用R里面的informationvalue包,来计算各指标的IV值,即可得到各定性指标间的重要性度量,选取其中的high predictive指标即可。
有很多小伙伴不知道informationvalue是什么:
我大概说一下,IV值衡量两个名义变量(其中一个是二元变量)之间关联性的常用指标。
library(InformationValue)
library(klaR)
credit_risk<-ifelse(train_kfolddata[,"credit_risk"]=="good",0,1)
#将违约状态变量用0和1表示,1表示违约。
tmp<-train_kfolddata[,-21]
data<-cbind(tmp,credit_risk)
data<-as.data.frame(data)
factor_vars<-c("status","credit_history","purpose","savings","employment_duration",
"personal_status_sex","other_debtors","property",
"other_installment_plans","housing","job","telephone","foreign_worker")
#获取所有名义变量
all_iv<-data.frame(VARS=factor_vars,IV=numeric(length(factor_vars)),
STRENGTH=character(length(factor_vars)),stringsAsFactors = F)
#初始化待输出的数据框
for(factor_var in factor_vars)
{
all_iv[all_iv$VARS==factor_var,"IV"]<-InformationValue::IV(X=
data[,factor_var],Y=data$credit_risk)
#计算每个指标的IV值
all_iv[all_iv$VARS==factor_var,"STRENGTH"]<-attr(InformationValue::IV(X=
data[,factor_var],Y=data$credit_risk),"howgood")
#提取每个IV指标的描述
}
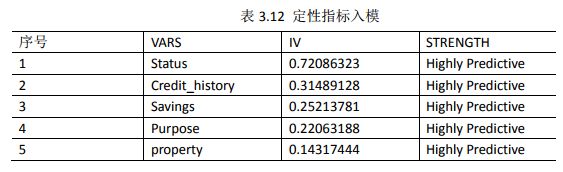
all_iv<-all_iv[order(-all_iv$IV),] #排序IV由结果可知,可选择的定性入模指标,如表3.12所示。
综上所述,模型开发中定量和定性的入模指标如表3.13所示。

对入模的定量和定性指标,分别进行连续变量分段(对定量指标进行分段),以便于计算定量指标的WOE和对离散变量进行必要的降维。对连续变量的分段方法通常分为等距分段和最优分段两种方法。等距分段是指将连续变量分为等距离的若干区间,然后在分别计算每个区间的WOE值。最优分段是指根据变量的分布属性,并结合该变量对违约状态变量预测能力的变化,按照一定的规则将属性接近的数值聚在一起,形成距离不相等的若干区间,最终得到对违约状态变量预测能力最强的最优分段。
定量指标筛选见上篇:
http://blog.csdn.net/lll1528238733/article/details/76600019