深度学习入门—基于Python的理论与实现(一)
本文参考书籍《深度学习入门—基于Python的理论与实现》
Python 入门
Python内容均已书本内容来赘述,涵盖量小且不完全,建议初学者参考其他相关书籍或博客python教程进行学习。
NumPy是用于数值计算的库,提供了很多高级的数学算法和便利的数组(矩阵)操作方法。
Matplotlib是用来画图的库。使用Matplotlib能实现实验结果可视化,并在视觉上确认深度学习运行期间的数据。
本内容均在Python 3.x版本进行。
- window命令下打开cmd输入 python --version 可以查询安装python的版本。输入 python 后可以进行python命令的操作。
- 算术计算:通过 +、-、*、/可以进行加减乘除运算, ** 表示乘方(3**2表示3的2次方)。
- 使用 type() 函数可以用来查看数据类型。 () 内填写需要查询数据类型的内容。
- 可以通过字母来定义变量,可以进行赋值与计算。
- 在python中,使用 # 来进行注释。
- 我们使用 [ ] 来汇总数据列表(数组),len(a) 来获取列表a的长度,a[0] 来访问列表a的第一个元素,在python中索引值从 0 开始,索引 -1 对应最后一个元素,-2 对应倒数第二个元素,以此类推。python列表还提供 切片 的索引方式,可进行访问列表的子列表 a[0:2] 表示访问列表a的索引0到2(不包括2)的元素; a[1:] 表示索引为1到最后一个元素; a[:3] 索引第一个元素到索引为3(不包括3)的元素,以此类推,多模仿多操作。
- 字典以键值对的形式存储起来 ,还有一些详细内容请读者进行自我学习。
>>> me={'height' : 180 } #生成字典,冒号前的是键,冒号后的是值
>>>> me['height'] #访问元素
180
>>> me['weight']=70 #添加新元素
>>> print(me)
{'height': 180, 'weight': 70}
- 布尔型,bool型取值为false或true
- if语句:if、elif、 else来进行不同条件的选择。在python中常用空格来表示缩进,每缩进一次使用4个空格,不建议使用 Tab 。
- for循环 :与C语言不同 for…in… .
- 函数:
>>> def hello():
... print("hello")
...
>>> hello()
hello
>>> def hello(object):
... print("hello " + object +"!")
...
>>> hello("kk")
hello kk!
+ 用于连接字符串。
- 类:
class 类名:
def __init__(self,参数,...): #构造参数
#该方法时进行初始化的方法,也称为**构造函数**,只在生成类的函数实例时被调用一次
#第一个参数**self**是python的一个特点,表示自身
...
def 方法名1 (self,参数,...): #方法1
...
def 方法名2 (self,参数,...): #方法2
...
class Man:
def __init__(self,name): #构造参数
self.name = name
print("Initialized")
def hello (self): #方法1
print("hello " + self.name + "!")
def goodbye (self): #方法2
print("goodbye " + self.name + "!")
m=Man("kk")
m.hello()
m.goodbye()

- Numpy
因为NumPy是外部库,因此需要导入
>>> import numpy as py #将numpy库作为np导入
>>> x=np.array([1,2 ,3])
>>> y=np.array([4,5,6])#用NumPy生成数组
NumPy进行算术运算时均是对应元素进行算术运算。
生成N维数组时的算术运算也是对应元素进行算术运算。
>>>A= np.array([[1,2],[3,4]])
本文将以为数组称为向量,二维数组称为数组,三维或三维以上的数组称为张量或多维数组。
- 广播:
>>>A= np.array([[1,2],[3,4]])
>>>B= np.array([10,20])
>>>A*B
array([10,40],[30,80])
当数组形状不同时会自动进行扩展成相同的形状再进行乘法运算。
- 访问元素:上文有陈述,这里不再进行赘述。
- Matplotlib:使用Matplotlib中的pyplot模块进行绘制图形
import numpy as np
import matplotlib.pyplot as plt
#生成数据
x=np.arange(0,6,0.1)#以0.1为单位生成0到6的数据
y1=np.sin(x)
y2=np.cos(x)
#绘制图形
plt.plot(x,y1,label="sin")
plt.plot(x,y2,linestyle='--',label="sin")#用虚线绘制
plt.xlabel("x")
plt.ylabel("y")
plt.title('sin & cos')
plt.legend()
plt.show()

import matplotlib.pyplot as plt
from matplotlib.image import imread
img = imread('1.jpg')#读入图片(注意路径)
plt.imshow(img)
plt.show()

本书推荐了基本Python的书,书名如下
《Python语言及其应用》
《利用Python进行数据分析》
20201.04.17
感知机
感知机接收多个输入信号,输出一个信号。感知机的信号只有0、1两种取值。
 上图所示,为单层感知机。x1,x2是输入信号,y是输出信号,w1,w2
上图所示,为单层感知机。x1,x2是输入信号,y是输出信号,w1,w2
是权重,⭕称为“神经元”或“节点”。输入信号被送往神经元时,会被分别乘以固定的权重(w1x1,w2x2)。神经元会计算传送过来的信号的综合,只有但这个总和超过了某个界限值时,才会输出1.这也称为“神经元被激活”。这里将这个界限值称为阈值,用符号θ表示。
可以用单层感知机来实现简单的逻辑电路,与门(AND),与非门(NAND)和或门(OR)。关于简单逻辑电路不清楚的内容可以查阅数字电子技术。
def AND(x1,x2):
w1,w2,theta =0.5,0.5,0.7
tmp=x1*w1+x2*w2
if tmp<=theta:
return 0
elif tmp>theta:
return 1
引入权重和偏置。
>>> import numpy as np
>>> x=np.array([0,1])
>>> w=np.array([0.5 ,0.5])
>>> b=-0.7
>>> w*x
array([0. , 0.5])
>>> np.sum(w*x)
0.5
>>> np.sum(w*x)+b
-0.19999999999999996
#与门
def AND(x1,x2):
x=np.array([x1,x2])
w=np.array([0.5 ,0.5])
b=-0.7
tmp=np.sum(w*x)+b
if tmp<=theta:
return 0
else:
return 1
#与非门
def NAND(x1,x2):
x=np.array([x1,x2])
w=np.array([-0.5 ,-0.5])
b=0.7
tmp=np.sum(w*x)+b
if tmp<=theta:
return 0
else:
return 1
#或门
def OR(x1,x2):
x=np.array([x1,x2])
w=np.array([0.5 ,0.5])
b=-0.2
tmp=np.sum(w*x)+b
if tmp<=theta:
return 0
else:
return 1
单层感知机无法实现异或门,只能实现线性分割。非线性分割可以通过多层感知机来实现。

#异或门
def XOR(x1,x2):
s1=NAND(x1,x2)
s2=OR(x1,x2)
y=AND(s1,s2)
return y
感知机的内容比较简单,稍加结合一下数电的知识就能很容易理解。
神经网络
上一节的感知机中的权重是人工进行标注的,而神经网络则是自动的从数据中学习到合适的权重参数。
在神经网络中,将输入层和输出层之间的层称为隐藏层或隐层。
在感知机中我们的输出为y=xw+b,在神经网络中输出y会通过一个激活函数(activation function)输出。即y=σ(xw+b)如图所示。
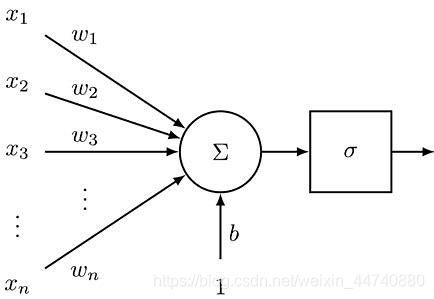 常用的激活函数如下图所示。在本书中主要用到sigmoid和RELU激活函数。
常用的激活函数如下图所示。在本书中主要用到sigmoid和RELU激活函数。

我们通过阶跃函数来进行讲解sigmoid和 RELU函数的实现与图形。
阶跃函数以0为分界点,大于0的输出均为1,小于0的输出均为0.
def step_function(x):
if x>0:
return 1
else:
return 0
这样很容易就实现了阶跃函数,但是这里的参数x只能是实数,不允许取NumPy数组,因此对上述代码进行修改
def step_function(x):
y=x>0
return y.astype(np.int)
>>> import numpy as np
>>> x=np.array([-1, 1,2])
>>> x
array([-1, 1, 2])
>>> y=x>0
>>> y
array([False, True, True])
>>> y=y.astype(np.int64)
>>> y
array([0, 1, 1], dtype=int64)
用astype()方法转换NumPy数组的类型。上述参数为np.int将bool转换为整型。
#绘制阶跃函数图形
import numpy as np
import matplotlib.pylab as plt
def step_function(x):
return np.array(x>0,dtype=int)
x=np.arange(-5.0, 5.0, 0.1) #注意与array区分开
y=step_function(x)
plt.plot(x,y)
plt.ylim(-0.1 , 1.1) #指定y轴范围
plt.show()
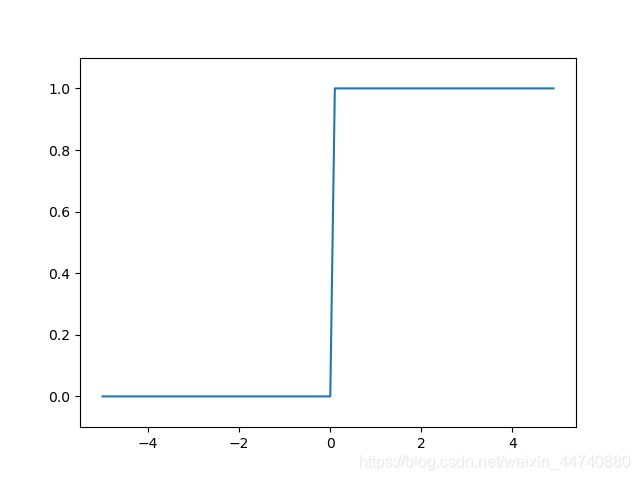
sigmoid实现
>>> x=np.array([-1,1,2])
>>> sigmoid(x)
array([0.26894142, 0.73105858, 0.88079708])
#绘制sigmoid图形
def sigmoid(x):
return 1/(1+np.exp(-x))
x=np.arange(-5.0, 5.0, 0.1) #注意与array区分开
y=sigmoid(x)
plt.plot(x,y)
plt.ylim(-0.1,1.1)
plt.show()

#对比阶跃函数与sigmoid函数
import numpy as np
import matplotlib.pylab as plt
def step_function(x):
return np.array(x>0,dtype=int)
x=np.arange(-5.0, 5.0, 0.1) #注意与array区分开
y1=step_function(x)
def sigmoid(x):
return 1/(1+np.exp(-x))
y2=sigmoid(x)
plt.figure()
plt.plot(x,y1,linestyle='--',label='0-1')
plt.plot(x,y2,label='sigmoid')
plt.title('0-1 & sigmoid')
plt.ylim(-0.1,1.1)
plt.show()
 从图中可以看出sigmoid函数比阶跃函数更平滑,阶跃函数只能返回0或1,而sigmoid函数可以返回0到1之间的任意实数。
从图中可以看出sigmoid函数比阶跃函数更平滑,阶跃函数只能返回0或1,而sigmoid函数可以返回0到1之间的任意实数。
他们的共同特征就是都是非线性函数。在神经网络中必须使用非线性函数。否则无法发挥出多层网络带来的优势。
RELU函数
RELU函数是在输入大于0时输出该值,在输入小于0时输出0。
import numpy as np
import matplotlib.pylab as plt
def step_function(x):
return np.array(x>0,dtype=int)
def sigmoid(x):
return 1/(1+np.exp(-x))
def relu(x):
return np.maximum(x,0)
x=np.arange(-5.0, 5.0, 0.1) #注意与array区分开
y1=step_function(x)
y2=sigmoid(x)
y3=relu(x)
plt.figure()
plt.plot(x,y1,linestyle='--',label='0-1')
plt.plot(x,y2,label='sigmoid')
plt.plot(x,y3,linestyle='-.',label='relu')
plt.title('0-1 & sigmoid&relu')
plt.ylim(-0.1,1.1)
plt.show()
 多维数组的运算
多维数组的运算
数组的维数可以通过np.ndim()函数来获得,获得的维数是空间维数,而非像线性代数那样的维数,这里要注意。
数组的形状可以通过实例变量shape获得。在获取数组的形状时会自动忽略参数1
二维数组也称为矩阵,数组的横向排列称为行,纵向排列称为列。
矩阵的乘法用np.dot()函数来计算。这里时做点积,与前面的对应元素相乘不同,注意区分。做点积的两个矩阵的内标要相同,即前一个矩阵的列与后一个矩阵的行数相同。
三层神经网络的实现(前向传播 forward propagation)
权重符号如下图所示。




import numpy as np
import matplotlib.pylab as plt
def sigmoid(x):
return 1/(1+np.exp(-x))
#从输入层到第一层的信号传递
X=np.array([1,0.5])
W1=np.array([[0.1,0.3,0.5],[0.2,0.4,0.6]])
B1=np.array([0.1,0.2,0.3])
print(W1.shape)#(2, 3)
print(X.shape)#(2,)
print(B1.shape)#(3,)
A1=np.dot(X,W1)+B1
Z1=sigmoid(A1)
print(A1)#[0.3 0.7 1.1]
print(Z1)#[0.57444252 0.66818777 0.75026011]
#第一层到第二层的信号传递
W2=np.array([[0.1,0.4],[0.2,0.5],[0.3,0.6]])
B2=np.array([0.1,0.2])
print(W2.shape)#(3, 2)
print(B2.shape)#(2,)
A2=np.dot(Z1,W2)+B2
Z2=sigmoid(A2)
print(A2)#[0.51615984 1.21402696]
print(Z2)#[0.62624937 0.7710107 ]
#第二层到输出层的信号传递
def identify_function(x):
return x
W3=np.array([[0.1,0.3],[0.2,0.4]])
B3=np.array([0.1,0.2])
A3=np.dot(Z2,W3)+B3
Y=indentify_function(A3)
#identify_function函数是恒等函数,输入等于输出,在这里这一不做函数定义,但与前面的的流程保持一致,故定义了恒等函数。
softmax函数常用于分类问题,而恒等函数常用于回归问题。
输出层常用恒等函数和softmax函数进行处理。
恒等函数输入与输出相同,常用一根箭头来表示。而softmax函数的输出通过箭头与所有输入性信号相连。
#softmax
def softmax(a):
exp_a=np.exp(a)
sum_exp_a=np.sum(exp_a)
y=exp_a/sum_exp_a
return y
softmax函数有一个缺点就是会出现溢出问题,因为 数值的范围是有限的。因此在计算时我们通过减去一个输入信号的最大值来防止溢出问题的发生。
>>> a=np.array([1010,1000,990])
>>> np.exp(a)/np.sum(np.exp(a))
:1: RuntimeWarning: overflow encountered in exp
:1: RuntimeWarning: invalid value encountered in true_divide
array([nan, nan, nan])
#a的值太大了,溢出了
>>> c=np.max(a)
>>> a-c
array([ 0, -10, -20])
>>> np.exp(a-c)/np.sum(np.exp(a-c))
array([9.99954600e-01, 4.53978686e-05, 2.06106005e-09])
#防止溢出softmax
def softmax(a):
c=np.max(a)
exp_a=np.exp(a-c)
sum_exp_a=np.sum(exp_a)
y=exp_a/sum_exp_a
return y
softmax函数的输出是从0.0到1.0之间的实数。并且,softmax函数的输出值的总和值为1.输出总和为1是softmax函数的一个重要性质。所以我们常把softmax函数的输出解释为“概率”。一般而言,神经网络只把输出值最大的神经元许哦对应的类别作为识别结果,并且,即便使用softmax函数,输出值最大的神经元的位置也不会变。
输出层神经元的数需要根据待解决的问题来决定。对于分类文艺,输出神经元数量一般设定为类别的数量。
手写数字识别的内容参考博客手写数字识别或手写数字识别3.6
2021.04.19